


uni-app 的 input,当 type = "text" 时,设置 confirm-type = "next" 可以提供键盘的“下一项”,通过 @confirm 触发设置下一个文本框的焦点,即可实现只操作键盘即可完成表单填写。
我们以从 a 组件跳转到 b 组件为例:
<input v-model="a" type="text" confirm-type="next" @confirm="moveNext('b')" />uni-app 的组件只有属性和事件,不提供方法,那么我们只能设置提供了 focus 属性的组件的焦点。
<input v-model="b" :focus="focusList['b']" />moveNext() 方法实现:
moveNext(dom){
this.focusList[dom] = true;
}当然 focusList 必须先定义并初始化,否则设置 focus 为 true 将失效:
data() {
return {
a: '',
b: '',
focusList: {
b: false
}
}
}几个注意点:
confirm-type = "next" 仅支持微信小程序
“下一项”按钮效果是一次性的,使用一次后再次在 a 上触摸“下一项”将不再跳转到 b,即使在 moveNext() 中先设置为 false 再设置为 true 也没用
其它组件也可以通过自带的方法实现跳转到带 focus 属性的组件(如在 picker 的 @change 中设置 this.focusList['b'] = true)
限制于 confirm-type = "next" 只当 type = "text" 时有效,因此非文本键盘(如数字键盘)就不能提供“下一项”功能
textarea 组件的右下角始终是“换行”,由其右上角的“完成”按钮来实现“下一项”功能
textarea 组件在“下一项”跳转过程中,组件可能会被 tabBar 遮挡(几率很大)

| ThoughtWorks.QRCode | ZXing.Net | |
| 生成方式 | 以指定的码元大小、版本、模式、纠错级别等信息来确定最终生成的图片大小 | 指定图片大小后,自动调整码元大小、出血* |
| 关于图片尺寸 | 不能直接确定最终生成的二维码图片的尺寸,可以先反向估算码元大小,再微调码元大小,直到不小于目标尺寸,如果必须严格限制尺寸,建议在 jpg 方式处理,因为 png 二维码的每个像素点非 0 即 1,在小尺寸的情况下会导致无法识别。(涉及到多次生成二维码,请斟酌性能消耗) | 生成二维码时即指定图片大小,但会留白,比较难以掌控实际效果 |
| "BUG" | 右边和下边有多余 1 像素需要手动去除 | 虽然可以设置参数 EncodeHintType.MARGIN,但还是没有达到预期的效果(网上有解析原因,请自行搜索) |
| …… |
*出血:为了提高二维码识别度,在生成的二维码四周留出若干码元(建议 4 个)空白。
更多
本文不定时更新!
A: MySQL 执行 SHOW FULL PROCESSLIST
Q: 查看连接数和慢查询,适用于 MySQL 数据库无法连接 1040
A: iftop -i eth0
Q: 查看占用带宽的IP(命令:iftop -i eth0 -F ip/24),添加到安全组、防火墙、宝塔的黑名单中。
命令 grep -l "x.x.x.x" /www/wwwlogs/*.log 可以在 wwwlogs 目录下的所有 .log 文件中查找指定的恶意 IP。
A: goaccess -f xxx.log
Q: 实时分析网站日志,查看请求最多的IP
A: net.xoyozo.weblog 日志分析工具
Q: 自制的 Web 日志分析工具,可按多种方式排序,纠出可疑访问
A: 重启 web 服务器
Q: 有时候能解决 CPU 和内存消耗的问题,如果一会儿又升高,则需要找另外的原因
Q: 500 服务器内部错误
502 Bad Gateway
504 Gateway Time-out
A: 查看 php 日志,可能的路径:
/usr/local/php/var/log/php-fpm.log
/www/server/php/[版本]/var/log/php-fpm.log
Q: RDS MySQL IOPS 使用率高的原因和处理
A: 根据时间点查看慢查询
Q: Discuz! 论坛界面错乱、表情不显示、模块缺失、登录失败、发帖失败等等
A: 进入管理中心 - 工具 - 更新缓存,能解决大部分问题
Q: Discuz! 浏览帖子提示“没有找到帖子”
A: 进入数据库,修复表 pre_forum_post 或分表
Q: CPU 100% 或内存 100%,负载100+
A: 原因有很多,以下是一些建议:
Windows 在任务管理器中查看进程
当前是否有正常的大流量访问(譬如民生类论坛的某个帖子突然火了)特别是重启无效的情况
对比网站日志大小可大致确定哪个网站被大量恶意请求。
观察:命令 top
排查:通过关闭网站来确定是某网站的问题,通过关闭功能确定是某功能的问题,如果 nginx 崩溃请参下条
案例:通过修改 mobcent 文件夹名确定是安米的文件被疯狂请求导致的,更新插件和 mobcent 包解决问题。
如果都是正常访问,top 看到很多 php-fpm,而且个个占用 CPU 还不小,那么根据服务器硬件配置来修改 php 的并发量,如宝塔面板在 php 设置 - 性能调整 页,300 并发方案的推荐配置是:
max_children:300
start_servers:30
min_spare_servers:30
max_spare_servers:180另外,memcached 或 redis 的配置也可以进行相应的修改。
另一个案例是 kswapd0 进程占满 CPU,原因是内存不足导致 swap 分区与内存频繁交换数据。同样调整 php 的设置即可。
也可以通过 iftop 来查询占用带宽较多的 IP 并封禁(出方向),如果 CPU 能降下来,那这个 IP 就是罪魁祸首。
* 使用 WAF 的审计 WAF 日志,未使用 WAF 的审计 Web 日志。
Q: 阿里云 ECS 的 CPU 突然达到 100%,并持续到次日 0:00 左右
A: 可能 ECS 是 t5 规格,受 CPU 积分制度限制,积分耗尽时 CPU 不工作。解决方法是更换其它规格产品或升配。
Q: ASP.NET 所在服务器 CPU 突然达到 50% 或 100%,并持续
A: 首先确定哪个网站,再依次排查网站各功能。可能是 HttpWebRequest 请求远程数据时长时间未返回结果导致的程序阻塞。
Q: nginx 服务停止
A: 查看 nginx 日志
WDCP 路径:/www/wdlinux/nginx-1.0.15/logs/error.log
Q: 公网出带宽 100%,其它指标正常
A: Windows 在任务管理器-性能-资源监视器-网络 查看占用带宽的进程PID,然后在任务管理器-详细信息中的找到对应的用户(如果为每个网站分别创建了用户,就能知道是哪个网站占用了带宽);如果是被 PID 为 4 的 System 占用大部分带宽,也可以尝试重启 IIS 来解决。
CentOS 使用 nethogs 查看占用带宽的进程PID和USER,如果为每个网站分别创建了用户,就能知道是哪个网站占用了带宽,否则只能一个个关闭网站来判断,不知道大家有没有好的方法?当然还可以直接用 iftop 命令查看占用带宽的 IP。另外,查看每个网站在那个时间段的日志文件的大小也能大概看出是哪个网站被采集了。
A: Linux 显示每个用户会话的登入和登出信息
utmpdump /var/log/wtmp
参考:http://www.tulaoshi.com/n/20160331/2050641.html
Q: RDS 的 CPU 100%
A: 如果是突然持续占满(同时伴随 ECS 资源使用率下降,页面出现 502),很大可能是受攻击(或社交网站推送突发事件等),查看“慢查询”,添加相关索引;如果是 Discuz! 论坛,可尝试修复优化表 pre_common_session。
如果是数日缓步上升,或新项目上线,考虑 SQL 慢查询,思路:MySQL / SQL Server。
MySQL:SHOW FULL PROCESSLIST
SQL Server:sp_who
Q: php 网站的服务器,内存在数天内缓慢上升
A: 大概是 php-fpm 占用过多,或进程数太多
更改 php 的配置(如 max_spare_servers),执行:service php-fpm reload
Q: 进程 cloudfs 占用内存过多
A: 参:https://xoyozo.net/Blog/Details/cloudfs-cache
Q: RDS 磁盘占用过大
A: 参:https://xoyozo.net/Blog/Details/how-to-use-rds
Q: ECS 受到 DDoS 攻击怎么办?
A: 参:https://xoyozo.net/Blog/Details/aliyun-ddos-without-bgp
Q: 如果 ECS 和 RDS 各项指标都没有异常,但网页打开慢或打不开502,TTFB 时间很长,是什么原因?(ECS 的 CPU 100%,RDS 的连接数上升,也可参考此条)
A: 数据库有坏表,尝试优化/修复表(慢 SQL 日志中锁等待时间较长的表?),或主备切换。show full processlist 时看到许多
DELETE FROM pre_common_session WHERE sid='******' OR lastactivity<****** OR (uid='0' AND ip1='*' AND ip2='*' AND ip3='*' AND ip4='*' AND lastactivity>******)
Q: Discuz! 创始人(站长)密码被改
A: 数据库找到 pre_ucenter_members 表,复制其它的已知登录密码的账号,复制其 password 和 salt 两个字段的值到创始人账号中,创始人账号即可用该密码登录了。
Q: 通过 iftop 观察到,Discuz! 网站从 RDS 数据库到 ECS 网站服务器私网流量非常大,远大于公网流量
A: 可能是缓存出问题了,尝试卸载重装 Redis 来解决。
Q: 宝塔面板中安装的 Redis 经常自动停止
A: 尝试卸载重装 Redis 来解决。
Q: 马甲客户端出现“您的网络有些问题”
A: 原因有许多,其中一个就是新建了一个数据表,然后 /source/class/table/ 下面丢失了对应的文件,具体可以找官方排查原因。
Q: 排查服务器安全需要检查哪些日志?
A: Web日志、登录日志(/var/log/secure)等。
Q: 带宽波形以几分钟为周期呈锯齿状波动是什么原因?
A: 该现象主要由防火墙流量管控机制与检测周期设置共同作用所致。防火墙基于预设的带宽阈值执行安全防护策略,当检测到流量峰值超过设定阈值时,将自动触发限流策略拒绝后续请求。待流量回落至安全阈值后,系统自动恢复服务访问权限。若防火墙的带宽采样检测周期设置过长(如以分钟为单位的检测间隔),将导致系统对实时流量变化的响应出现迟滞。这种周期性的检测机制会使带宽监控数据在阈值临界点附近呈现规律性的锯齿状波动特征。
优化建议:可通过调整防火墙的流量检测周期至更小时间粒度(如10-15秒),或采用动态流量整形策略,以实现更平滑的带宽控制效果。
补充说明:对于阿里云监控数据的调用,建议注意接口调用频率管控。高频调用云监控API接口将触发阿里云的API计费策略,可能产生额外的资源消耗成本。
其它案例
IIS:
进入 IIS 管理器,
打开“Web 平台安装程序”
在“产品”选项卡中选择“服务器”项
添加“IIS:IP 和域限制”
安装
关闭并重新打开 IIS 管理器
打开“IP 地址和域限制”
右侧“添加拒绝条目”
itables:
查看当前规则:
iptables -L
或直接编辑
vim /etc/sysconfig/iptables
添加规则:
封单个IP:
iptables -I INPUT -s 888.888.888.888 -j DROP
封IP段:
iptables -I INPUT -s 888.888.888.0/24 -j DROP
解封:
iptables -D INPUT -s 888.888.888.888 -j DROP
在开发微信中的网页时,会遇到一些域名相关的配置:
① 公众号设置 - 功能设置 - 业务域名
② 公众号设置 - 功能设置 - JS接口安全域名
③ 接口权限 - 网页授权获取用户基本信息
④ 商户平台 - 产品中心 - 开发配置 - JSAPI支付授权目录
⑤ 小程序 - 开发 - 开发设置 - 业务域名
⑥ 公众号开发 - 基本设置 - IP白名单
第①种 业务域名:相对不重要,只是用来禁止显示“防欺诈盗号,请勿支付或输入qq密码”提示框,可配置 3 个二级或二级以上域名(个人理解是“非顶级域名”,即填写了 b.a.com 的话,对 c.b.a.com 不起作用,待测)。
我们网站的域名和公众号是没有绑定关系的,那么你在打开一个(可能是朋友分享的)网页时,跟哪个公众号的配置去关联呢,答案是 JS-SDK。
测试结果:由于一个月只有3次修改机会,这次先测二级域名,有效;再测顶级域名,有效;删除所有,仍有效。所以应该是缓存作用。过几天再试,然后下个月先测顶级域名,来确定直接填写顶级域名是否对所有二级域名有效。
第②种 JS接口安全域名:是配置所配置的域名下的网页可调用 JS-SDK。可配置 5 个一级或一级以上域名(个人理解是“任何级域名”,即填写了 b.a.com 对 c.b.a.com 也有效,但对 c.z.a.com 无效,待测。如果我们拥有顶级域名对应网站的控制权(上传验证文件到网站根目录),直接填写顶级域名即可)。
使用 JS-SDK 的每个网页都必须注入配置信息(wx.config),而之前必须获取 jsapi_ticket,jsapi_ticket api 的调用次数非常有限,必须全局缓存。而获取 jsapi_ticket 之前必须先获取 access_token,同样需要全局缓存。所以,我们专门做个接口,功能是传入需要使用 JS-SDK 的网页的 url,输出 wx.config 需要用到的配置信息,来实现在不同网页(网站)使用 JS-SDK。
第③种 网页授权域名:这是已认证的服务号才能享有的特权,主要作用是获取用户在该服务号中的 openid 和 unionid。可配置 1 个 2 个回调域名(可填写任意级别的域名,但仅对该域名的网页(网站)有效,若填写了 a.com 对 b.a.com 是无效的)。
因此,如果我们需要在不同二级域名甚至不同顶级域名下的网页(以下称之为活动页面)实现用户授权,需要做一个统一的代理授权页面(回调域名当然是填写这个页面所在的域名),引导用户依次打开:微信授权页面 - 代理授权页面 - 活动页面,根据开发说明文档,具体实现如下:
当用户第一次打开活动页面时,引导打开微信授权页面(https://open.weixin.qq.com/connect/oauth2/authorize),其中参数 redirect_uri 指定回调地址,即代理授权页面地址,参数 state 指定活动页面地址。微信授权页面返回 code 和 state,code 作为换取网页授权 access_token 的票据。到这一步,本来可以由代理授权页面直接拿这个 code 去换取 access_token、openid 和 unionid 了,但是由于当前用户还在 302 重定向过程中,将这些信息带入到活动页面时势必导致信息泄露,所以这里将 code 追加到 state 指定的网址上后重定向到活动页面,活动页面拿到 code 再通过服务器端向代理授权页面所在服务器请求 openid 和 unionid,并将它们保存于 Session 中视为用户登录。这样,服务号的 appid 和 secret 也能得到保护。代理授权页面请求的微信服务器接口地址是 https://api.weixin.qq.com/sns/oauth2/access_token。
注:网页授权 access_token 不同于 JS-SDK 中使用的全局唯一接口调用凭据 access_token,没有请求次数限制。
流程既然通了,实现逻辑可以这样设定:
活动页面首先判断 Session 中是否有 openid 或 unionid,若有表示已授权登录;没有再判断地址栏是否有 code 参数,若有则调用代理授权页面所在服务器的接口,用 code 换 openid 和 unionid;没有则直接重定向到代理授权页面,带上 state。用 code 换 openid 和 unionid 时若成功则保存至 Session,若失败则仍然重定向到代理授权页面,带上 state,特别注意 state 中的活动页面地址确保没有 code 参数。
第④种 JSAPI支付授权目录:涉及到微信支付时用到,顾名思义是固定某一个网站内的某个目录,以“/”结尾。最多可添加 5 个。如果支付页面在目录 https://www.a.com/b/ 下,那么可以填写 https://www.a.com/b/ 或 https://www.a.com/(建议后者),暂未测试填写 https://a.com/ 会不会起作用。涉及支付安全,建议设置支付页面的最深一层不可写的目录,以防目录内被上传后门文件带来的安全隐患。
第⑤种 小程序业务域名:任何需要在小程序的 web-view 组件中打开的网页,都必须配置小程序业务域名,限制 20 个。该域名要求必须 https,可填入“任何级域名”(建议填顶级域名,即填写了 a.com 对 b.a.com 也有效。如果我们拥有顶级域名对应网站的控制权(上传验证文件到网站根目录),直接填写顶级域名即可)。
第⑥种 IP白名单:仅填写管理全局 access_token 的中控服务器的 IP。
总结:在上述自定义接口部署完成后,如果微信中的网页想获取用户的 unionid,则不需要配置域名,直接使用统一的代理授权即可;如果需要使用 JS-SDK 功能,如分享、上传等等,则需要配置 JS 接口安全域名;如果有表单,最好配置一下业务域名。
本文系个人经验总结,部分结果未经证实,欢迎指正!QQ:940534113
微信是一个生活方式,朋友圈是用户分享和关注朋友们生活点滴的空间,微信公众平台是一个企业、机构与个人用户之间交流和服务的平台。一直以来,微信致力于为用户提供绿色、健康的网络生态环境。通过《微信公众平台服务协议》、《微信公众平台运营规范》和《微信开放平台开发者服务协议》等相关协议及专项规则,微信公众平台和微信开放平台的内容得到了良好的管理。为了进一步优化微信用户的使用体验,更好地保障微信用户合法权益,现将非由微信公众平台产生(即域名地址不归属于微信公众平台)且在微信内传播的外部链接内容相关管理规范进行公示。
对于违反本规范的内容,一经发现将立即进行处理,包括但不限于停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行访问、屏蔽相关链接等。由微信公众平台或开放平台帐号施行或者发起的,一经查实,前述帐号、主体也将按照微信相关规则进行处罚,包括但不限于限制或禁止使用部分或全部功能、帐号封禁直至注销等,并公告处理结果;微信也有权依照本规范及相关协议、专项规则的规定,拒绝再向前述主体提供服务。
具体规则及相关处罚如下:
-
诱导分享类内容
-
1.1 要求用户分享,分享后方可进行下一步操作,分享后方可知道答案等;
-
1.2 含有明示或暗示用户分享的文案、图片、按钮、弹层、弹窗等的,如:分享给好友、邀请好友一起完成任务等;
-
1.3 通过利益诱惑,诱导用户分享、传播外链内容或者微信公众帐号文章的,包括但不限于:现金奖励、实物奖品、虚拟奖品(红包、优惠券、代金券、积分、话费、流量、信息等)、集赞、拼团、分享可增加抽奖机会、中奖概率,以积分或金钱利益诱导用户分享、点击、点赞微信公众帐号文章等;
-
1.4 用夸张言语来胁迫、引诱用户分享的。包括但不限于:“不转不是中国人”、“请好心人转发一下”、“转发后一生平安”、“转疯了”、“必转”、“转到你的朋友圈朋友都会感激你”等;
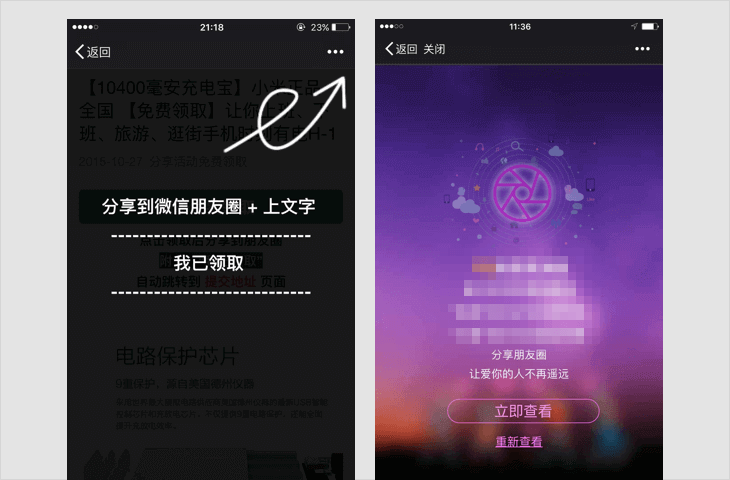
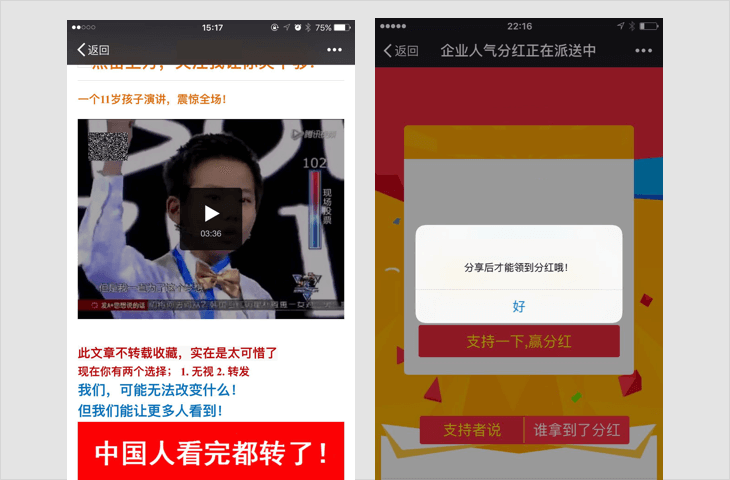
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问,短期封禁相关开放平台帐号或应用的分享接口;对于情节恶劣的情况,永久封禁帐号、域名、IP地址或分享接口。
-
-
诱导关注类内容
-
强制或诱导用户关注公众帐号的,包括但不限于关注后查看答案、领取红包、关注后方可参与活动等;
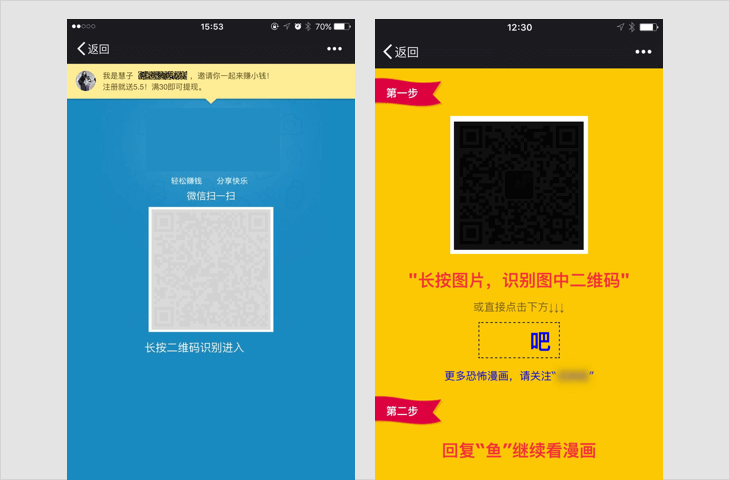
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
H5游戏、测试类内容
-
以游戏、测试等方式,吸引用户参与互动的,具体形式包括但不限于比手速、好友问答、性格测试,测试签、网页小游戏等;
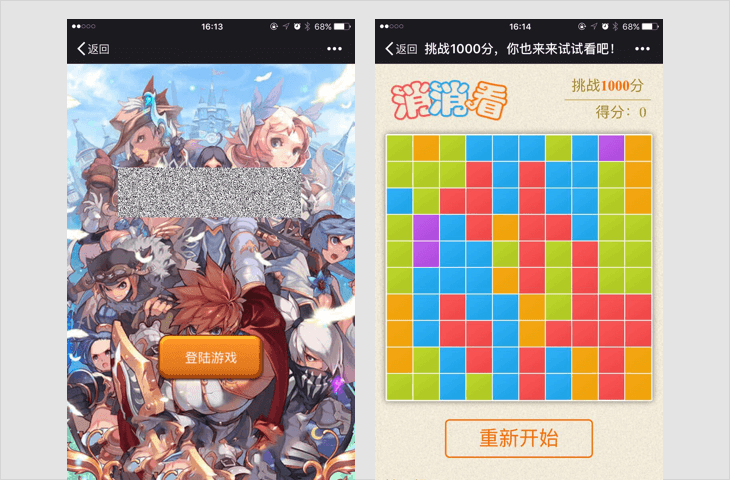
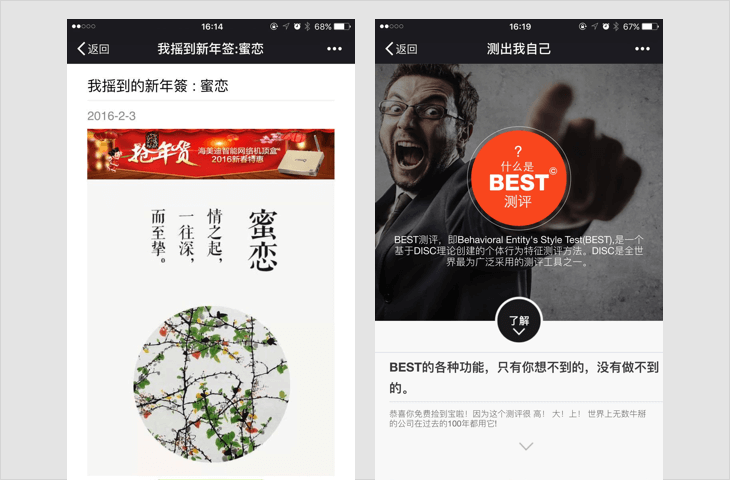
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
欺诈类内容
-
4.1 虚假红包、活动
通过虚假的红包、活动等形式,以赚取现金、实物奖品、虚拟奖品等方式欺骗用户参与的,具体形式包括但不限于虚假现金红包、虚假话费卡、虚假流量红包、虚假优惠券、虚假优惠活动等;
-
4.2 宣传或销售侵害他人合法权益的商品
通过虚假宣传、恶意营销等方式,向用户宣传或诱骗用户购买侵害他人合法权益的物品的,例如以骗取邮费为目的的赠送物品活动、虚假付费服务等;
-
4.3 仿冒微信公众帐号排版、域名
仿冒微信公众帐号文章排版、域名,可能造成微信用户混淆的;
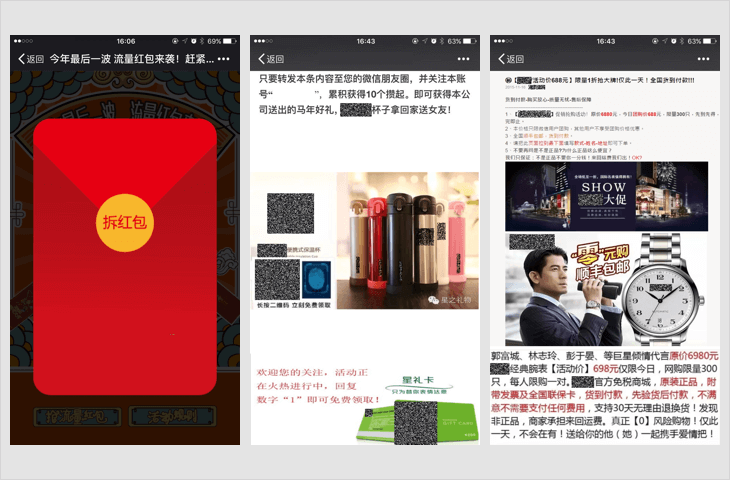
若内容中包含以上情况,一经发现,立即永久封禁帐号、域名、IP地址。
-
-
谣言类内容
-
发送不实信息,制造谣言,可能对他人、企业或其他机构造成损害的,例如自来水有毒、香蕉致癌、小龙虾不能吃等;
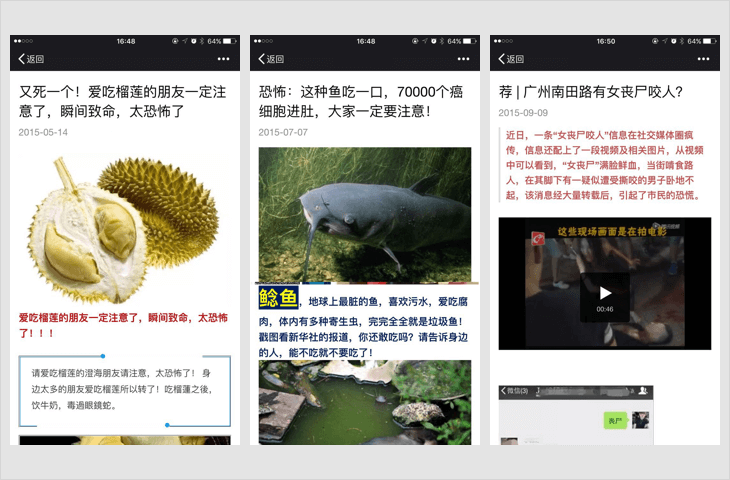
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问、短期封禁相关开放平台帐号或应用的分享接口;对于情节恶劣的情况,永久封禁帐号、域名、IP地址;
-
-
骚扰信息、广告信息及垃圾信息
-
传播骚扰、欺诈、垃圾广告等信息的,包括但不限于虚假中奖类信息,不符合国家相关法律法规的保健品、药品、食品类信息,假冒伪劣商品信息,虚假服务信息,虚假网络货币等;
-
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
题文不符、内容低俗的信息
-
7.1 题文不符的信息
故意拟制耸动标题,或以明显倾向性、误导性、煽动性的标题吸引他人点击的,即俗称“标题党”;
-
7.2 内容低俗的信息
涉及性器官、性行为、性暗示的,传播低级趣味、庸俗、有伤风化内容的,或者宣扬暴力、恶意谩骂、侮辱他人内容的,例如:传播走光、偷拍、露点、一夜情、换妻、性虐待、情色动漫、非法性药品广告和性病治疗广告、推介淫秽色情网站等;
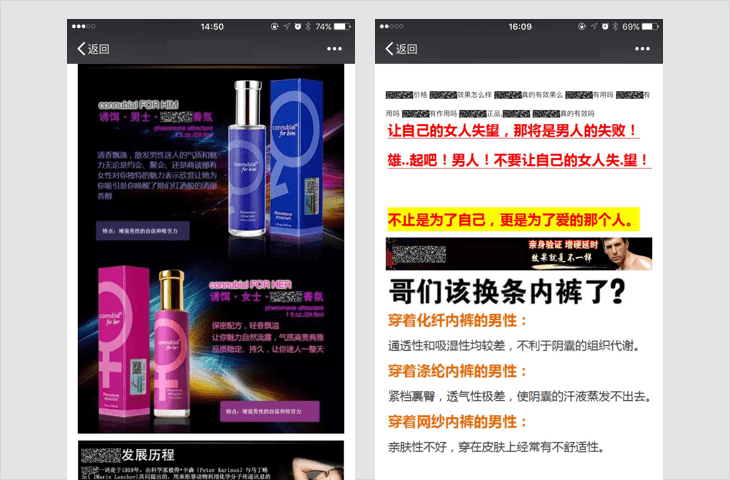
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
非法获取用户数据、信息
-
未经用户明确同意,并向用户如实披露数据用途、使用范围等相关信息的情形下复制、存储、使用或传输用户数据的,包括但不限于要求用户共享个人信息(手机号、出生日期等)才可使用其功能,或收集用户密码或者用户个人信息(包括但不限于,手机号,身份证号,生日,住址等);
-
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问,短期封禁相关帐号;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
其它违反国家法律法规的内容,包括但不限于:
-
(1) 违反宪法确定的基本原则的;
-
(2) 危害国家安全,泄露国家秘密,颠覆国家政权,破坏国家统一的;
-
(3) 损害国家荣誉和利益的;
-
(4) 煽动民族仇恨、民族歧视,破坏民族团结的;
-
(5) 破坏国家宗教政策,宣扬邪教和封建迷信的;
-
(6) 散布谣言,扰乱社会秩序,破坏社会稳定的;
-
(7) 散布淫秽、色情、赌博、暴力、恐怖或者教唆犯罪的;
-
(8) 侮辱或者诽谤他人,侵害他人合法权益的;
-
(9) 煽动非法集会、结社、游行、示威、聚众扰乱社会秩序;
-
(10) 以非法民间组织名义活动的;
-
(11) 含有法律、行政法规禁止的其他内容的。
-
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问,短期封禁相关帐号;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
申诉及常见问题可查看:http://kf.qq.com/faq/131117ne2MV7141117JzI32q.html
微信团队请用户主动遵守上述条款,也欢迎用户对违反微信链接类内容管理规范的内容进行投诉,一经核实,微信团队将立即按照规范进行处理。让我们共同创建并维护和谐的微信生态!
微信团队
| 软件名称 | 价格 | 软件介绍 |
|---|---|---|
| ProPresenter | 试用 / $399 | 一款跨平台(Mac、Windows),专为高品质现场(包括晚会、体育赛事、会议等)打造字幕及多媒体展示的软件。 (试用版是全功能的,但输出窗口有水印,试用期两周) |
| Sports Sounds Pro | 免费 / $149.95 | 一款专业用于现场事件的音控软件。 (免费版是全功能的,仅有一些限制,比如:只能播放 10 组中每组的前 3 页的第 1 行,而且只能放置 180 个按钮) |
| Miro Video Converter | 免费 | 可以导出兼容 HTML5 网页播放的视频格式(.mp4)。 |
| Vistumbler | 免费 | 无线网络扫描工具。 |
| VNC | 免费 / $30 / $40 | Mac 上优秀的远程桌面软件。 |
| 免费 | 快速扫描目录大小和空间占用 | |
| IconWorkshop | 试用 / 购买 | 优秀的 ICO、ICON 制作软件,专业图标制作,编辑,转换工具 |
| $19 / $59 | 功能强大的数字音乐编辑器,是一个集声音编辑、播放、录制和转换的音频工具。 | |
| EasyRecovery | EasyRecovery 是由全球著名数据厂商 Kroll Ontrack 出品的一款数据文件恢复软件。支持恢复不同存储介质数据:硬盘、光盘、U盘、移动硬盘、数码相机、手机、Raid 文件恢复等,能恢复包括文档、表格、图片、音视频等各种文件。 | |
| DiskGenius | 一款专业级的数据恢复软件,算法精湛、功能强大!支持多种情况下的文件丢失、分区丢失恢复;支持文件预览;支持扇区编辑、RAID 恢复等高级数据恢复功能。 | |
| sagethumbs | 免费 | 预览 PSD 文件 |
| WebP Codec for Windows | 免费 | 预览 WebP 文件 |
| ventoy | 免费 | 多系统启动U盘解决方案 |
我们继续讲解LINQ to SQL语句,这篇我们来讨论Group By/Having操作符和Exists/In/Any/All/Contains操作符。
Group By/Having操作符
适用场景:分组数据,为我们查找数据缩小范围。
说明:分配并返回对传入参数进行分组操作后的可枚举对象。分组;延迟
1.简单形式:
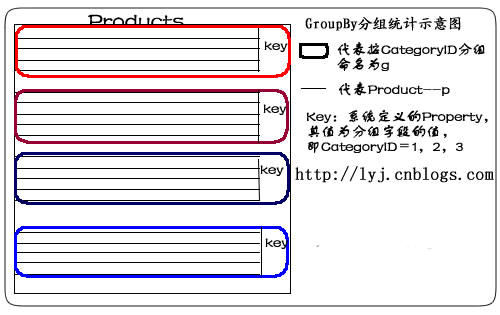
var q =
from p in db.Products
group p by p.CategoryID into g
select g;
语句描述:使用Group By按CategoryID划分产品。
说明:from p in db.Products 表示从表中将产品对象取出来。group p by p.CategoryID into g表示对p按CategoryID字段归类。其结果命名为g,一旦重新命名,p的作用域就结束了,所以,最后select时,只能select g。当然,也不必重新命名可以这样写:
var q =
from p in db.Products
group p by p.CategoryID;
我们用示意图表示:
如果想遍历某类别中所有记录,这样:
foreach (var gp in q)
{
if (gp.Key == 2)
{
foreach (var item in gp)
{
//do something
}
}
}
2.Select匿名类:
var q =
from p in db.Products
group p by p.CategoryID into g
select new { CategoryID = g.Key, g };
说明:在这句LINQ语句中,有2个property:CategoryID和g。这个匿名类,其实质是对返回结果集重新进行了包装。把g的property封装成一个完整的分组。如下图所示:

如果想遍历某匿名类中所有记录,要这么做:
foreach (var gp in q)
{
if (gp.CategoryID == 2)
{
foreach (var item in gp.g)
{
//do something
}
}
}
3.最大值
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
MaxPrice = g.Max(p => p.UnitPrice)
};
语句描述:使用Group By和Max查找每个CategoryID的最高单价。
说明:先按CategoryID归类,判断各个分类产品中单价最大的Products。取出CategoryID值,并把UnitPrice值赋给MaxPrice。
4.最小值
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
MinPrice = g.Min(p => p.UnitPrice)
};
语句描述:使用Group By和Min查找每个CategoryID的最低单价。
说明:先按CategoryID归类,判断各个分类产品中单价最小的Products。取出CategoryID值,并把UnitPrice值赋给MinPrice。
5.平均值
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
AveragePrice = g.Average(p => p.UnitPrice)
};
语句描述:使用Group By和Average得到每个CategoryID的平均单价。
说明:先按CategoryID归类,取出CategoryID值和各个分类产品中单价的平均值。
6.求和
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
TotalPrice = g.Sum(p => p.UnitPrice)
};
语句描述:使用Group By和Sum得到每个CategoryID 的单价总计。
说明:先按CategoryID归类,取出CategoryID值和各个分类产品中单价的总和。
7.计数
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
NumProducts = g.Count()
};
语句描述:使用Group By和Count得到每个CategoryID中产品的数量。
说明:先按CategoryID归类,取出CategoryID值和各个分类产品的数量。
8.带条件计数
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
NumProducts = g.Count(p => p.Discontinued)
};
语句描述:使用Group By和Count得到每个CategoryID中断货产品的数量。
说明:先按CategoryID归类,取出CategoryID值和各个分类产品的断货数量。 Count函数里,使用了Lambda表达式,Lambda表达式中的p,代表这个组里的一个元素或对象,即某一个产品。
9.Where限制
var q =
from p in db.Products
group p by p.CategoryID into g
where g.Count() >= 10
select new {
g.Key,
ProductCount = g.Count()
};
语句描述:根据产品的―ID分组,查询产品数量大于10的ID和产品数量。这个示例在Group By子句后使用Where子句查找所有至少有10种产品的类别。
说明:在翻译成SQL语句时,在最外层嵌套了Where条件。
10.多列(Multiple Columns)
var categories =
from p in db.Products
group p by new
{
p.CategoryID,
p.SupplierID
}
into g
select new
{
g.Key,
g
};
语句描述:使用Group By按CategoryID和SupplierID将产品分组。
说明: 既按产品的分类,又按供应商分类。在by后面,new出来一个匿名类。这里,Key其实质是一个类的对象,Key包含两个Property:CategoryID、SupplierID。用g.Key.CategoryID可以遍历CategoryID的值。
11.表达式(Expression)
var categories =
from p in db.Products
group p by new { Criterion = p.UnitPrice > 10 } into g
select g;
语句描述:使用Group By返回两个产品序列。第一个序列包含单价大于10的产品。第二个序列包含单价小于或等于10的产品。
说明:按产品单价是否大于10分类。其结果分为两类,大于的是一类,小于及等于为另一类。
Exists/In/Any/All/Contains操作符
适用场景:用于判断集合中元素,进一步缩小范围。
Any
说明:用于判断集合中是否有元素满足某一条件;不延迟。(若条件为空,则集合只要不为空就返回True,否则为False)。有2种形式,分别为简单形式和带条件形式。
1.简单形式:
仅返回没有订单的客户:
var q =
from c in db.Customers
where !c.Orders.Any()
select c;
生成SQL语句为:
SELECT [t0].[CustomerID], [t0].[CompanyName], [t0].[ContactName],
[t0].[ContactTitle], [t0].[Address], [t0].[City], [t0].[Region],
[t0].[PostalCode], [t0].[Country], [t0].[Phone], [t0].[Fax]
FROM [dbo].[Customers] AS [t0]
WHERE NOT (EXISTS(
SELECT NULL AS [EMPTY] FROM [dbo].[Orders] AS [t1]
WHERE [t1].[CustomerID] = [t0].[CustomerID]
))
2.带条件形式:
仅返回至少有一种产品断货的类别:
var q =
from c in db.Categories
where c.Products.Any(p => p.Discontinued)
select c;
生成SQL语句为:
SELECT [t0].[CategoryID], [t0].[CategoryName], [t0].[Description],
[t0].[Picture] FROM [dbo].[Categories] AS [t0]
WHERE EXISTS(
SELECT NULL AS [EMPTY] FROM [dbo].[Products] AS [t1]
WHERE ([t1].[Discontinued] = 1) AND
([t1].[CategoryID] = [t0].[CategoryID])
)
All
说明:用于判断集合中所有元素是否都满足某一条件;不延迟
1.带条件形式
var q =
from c in db.Customers
where c.Orders.All(o => o.ShipCity == c.City)
select c;
语句描述:这个例子返回所有订单都运往其所在城市的客户或未下订单的客户。
Contains
说明:用于判断集合中是否包含有某一元素;不延迟。它是对两个序列进行连接操作的。
string[] customerID_Set =
new string[] { "AROUT", "BOLID", "FISSA" };
var q = (
from o in db.Orders
where customerID_Set.Contains(o.CustomerID)
select o).ToList();
语句描述:查找"AROUT", "BOLID" 和 "FISSA" 这三个客户的订单。 先定义了一个数组,在LINQ to SQL中使用Contains,数组中包含了所有的CustomerID,即返回结果中,所有的CustomerID都在这个集合内。也就是in。 你也可以把数组的定义放在LINQ to SQL语句里。比如:
var q = (
from o in db.Orders
where (
new string[] { "AROUT", "BOLID", "FISSA" })
.Contains(o.CustomerID)
select o).ToList();
Not Contains则取反:
var q = (
from o in db.Orders
where !(
new string[] { "AROUT", "BOLID", "FISSA" })
.Contains(o.CustomerID)
select o).ToList();
1.包含一个对象:
var order = (from o in db.Orders
where o.OrderID == 10248
select o).First();
var q = db.Customers.Where(p => p.Orders.Contains(order)).ToList();
foreach (var cust in q)
{
foreach (var ord in cust.Orders)
{
//do something
}
}
语句描述:这个例子使用Contain查找哪个客户包含OrderID为10248的订单。
2.包含多个值:
string[] cities =
new string[] { "Seattle", "London", "Vancouver", "Paris" };
var q = db.Customers.Where(p=>cities.Contains(p.City)).ToList();
语句描述:这个例子使用Contains查找其所在城市为西雅图、伦敦、巴黎或温哥华的客户。
总结一下这篇我们说明了以下语句:
| Group By/Having | 分组数据;延迟 |
| Any | 用于判断集合中是否有元素满足某一条件;不延迟 |
| All | 用于判断集合中所有元素是否都满足某一条件;不延迟 |
| Contains | 用于判断集合中是否包含有某一元素;不延迟 |
本系列链接:LINQ体验系列文章导航
LINQ推荐资源
LINQ专题:http://kb.cnblogs.com/zt/linq/ 关于LINQ方方面面的入门、进阶、深入的文章。
LINQ小组:http://space.cnblogs.com/group/linq/ 学习中遇到什么问题或者疑问提问的好地方。
自从有了IP数据库这种东西,QQ外挂的显示IP功能也随之而生,本人见识颇窄,是否还有其他应用不得而知,不过,IP数据库确实是个不错的东西。如今网络上最流行的IP数据库我想应该是纯真版的(说错了也不要扁我),迄今为止其IP记录条数已经接近30000,对于有些IP甚至能精确到楼层,不亦快哉。2004年4、5月间,正逢LumaQQ破土动工,为了加上这个人人都喜欢,但是好像人人都不知道为什么喜欢的显IP功能,我也采用了纯真版IP数据库,它的优点是记录多,查询速度快,它只用一个文件QQWry.dat就包含了所有记录,方便嵌入到其他程序中,也方便升级。
基本结构
QQWry.dat文件在结构上分为3块:文件头,记录区,索引区。一般我们要查找IP时,先在索引区查找记录偏移,然后再到记录区读出信息。由于记录区的记录是不定长的,所以直接在记录区中搜索是不可能的。由于记录数比较多,如果我们遍历索引区也会是有点慢的,一般来说,我们可以用二分查找法搜索索引区,其速度比遍历索引区快若干数量级。图1是QQWry.dat的文件结构图。

图1. QQWry.dat文件结构
要注意的是,QQWry.dat里面全部采用了little-endian字节序
一. 了解文件头
QQWry.dat的文件头只有8个字节,其结构非常简单,首四个字节是第一条索引的绝对偏移,后四个字节是最后一条索引的绝对偏移。
二. 了解记录区
每条IP记录都由国家和地区名组成,国家地区在这里并不是太确切,因为可能会查出来“清华大学计算机系”之类的,这里清华大学就成了国家名了,所以这个国家地区名和IP数据库制作的时候有关系。所以记录的格式有点像QName,有一个全局部分和局部部分组成,我们这里还是沿用国家名和地区名的说法。
于是我们想象着一条记录的格式应该是: [IP地址][国家名][地区名],当然,这个没有什么问题,但是这只是最简单的情况。很显然,国家名和地区名可能会有很多的重复,如果每条记录都保存一个完整的名称拷贝是非常不理想的,所以我们就需要重定向以节省空间。所以为了得到一个国家名或者地区名,我们就有了两个可能:第一就是直接的字符串表示的国家名,第二就是一个4字节的结构,第一个字节表明了重定向的模式,后面3个字节是国家名或者地区名的实际偏移位置。对于国家名来说,情况还可能更复杂些,因为这样的重定向最多可能有两次。
那么什么是重定向模式?根据上面所说,一条记录的格式是[IP地址][国家记录][地区记录],如果国家记录是重定向的话,那么地区记录是有可能没有的,于是就有了两种情况,我管他叫做模式1和模式2。我们对这些格式的情况举图说明:

图2. IP记录的最简单形式
图2表示了最简单的IP记录格式,我想没有什么可以解释的

图3. 重定向模式1
图3演示了重定向模式1的情况。我们看到在模式1的情况下,地区记录也跟着国家记录走了,在IP地址之后只剩下了国家记录的4字节,后面3个字节构成了一个指针,指向了实际的国家名,然后又跟着地址名。模式1的标识字节是0x01。

图4. 重定向模式2
图4演示了重定向模式2的情况。我们看到了在模式2的情况下(其标识字节是0x02),地区记录没有跟着国家记录走,因此在国家记录之后4个字节之后还是有地区记录。我想你已经明白了模式1和模式2的区别,即:模式1的国家记录后面不会再有地区记录,模式2的国家记录后会有地区记录。下面我们来看一下更复杂的情况。

图5. 混和情况1
图5演示了当国家记录为模式1的时候可能出现的更复杂情况,在这种情况下,重定向指向的位置仍然是个重定向,不过第二次重定向为模式2。大家不用担心,没有模式3了,这个重定向也最多只有两次,并且如果发生了第二次重定向,则其一定为模式2,而且这种情况只会发生在国家记录上,对于地区记录,模式1和模式2是一样的,地区记录也不会发生2次重定向。不过,这个图还可以更复杂,如图7:

图6. 混和情况2
图6是模式1下最复杂的混和情况,不过我想应该也很好理解,只不过地区记录也来重定向而已,有一点我要提醒你,如果重定向的地址是0,则表示未知的地区名。
所以我们总结如下:一条IP记录由[IP地址][国家记录][地区记录]组成,对于国家记录,可以有三种表示方式:字符串形式,重定向模式1和重定向模式2。对于地区记录,可以有两种表示方式:字符串形式和重定向,另外有一条规则:重定向模式1的国家记录后不能跟地区记录。按照这个总结,在这些方式中合理组合,就构成了IP记录的所有可能情况。
设计的理由
在我们继续去了解索引区的结构之前,我们先来了解一下为何记录区的结构要如此设计。我想你可能想到了答案:字符串重用。没错,在这种结构下,对于一个国家名和地区名,我只需要保存其一次就可以了。我们举例说明,为了表示方便,我们用小写字母代表IP记录,C表示国家名,A表示地区名:
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2, A1 = A2,那么我们就可以使用图3显示的结构来实现重用
有三条记录a(C1, A1), b(C2, A2), c(C3, A3),如果C1 = C2, A2 = A3,现在我们想存储记录b,那么我们可以用图6的结构来实现重用
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2,现在我们想存储记录b,那么我们可以采用模式2表示C2,用字符串表示A2
你可以举出更多的情况,你也会发现在这种结构下,不同的字符串只需要存储一次。
了解索引区
在"了解文件头"部分,我们说明了文件头实际上是两个指针,分别指向了第一条索引和最后一条索引的绝对偏移。如图8所示:

图8. 文件头指向索引区图示
实在是很简单,不是吗?从文件头你就可以定位到索引区,然后你就可以开始搜索IP了!每条索引长度为7个字节,前4个字节是起始IP地址,后三个字节就指向了IP记录。这里有些概念需要说明一下,什么是起始IP,那么有没有结束IP?假设有这么一条记录:166.111.0.0 - 166.111.255.255,那么166.111.0.0就是起始IP,166.111.255.255就是结束IP,结束IP就是IP记录中的那头4个字节,这下你应该就清楚了吧。于是乎,每条索引配合一条记录,构成了一个IP范围,如果你要查找166.111.138.138所在的位置,你就会发现166.111.138.138落在了166.111.0.0- 166.111.255.255 这个范围内,那么你就可以顺着这条索引去读取国家和地区名了。那么我们给出一个最详细的图解吧:

图9. 文件详细结构
现在一切都清楚了是不是?也许还有一点你不清楚,QQWry.dat的版本信息存在哪里呢? 答案是:最后一条IP记录实际上就是版本信息,最后一条记录显示出来就是这样:255.255.255.0255.255.255.255 纯真网络 2004年6月25日IP数据。OK,到现在你应该全部清楚了。
Demo
下一步:我给出一个读取IP记录的程序片断,此片断摘录自LumaQQ源文件edu.tsinghua.lumaqq.IPSeeker.java,如果你有兴趣,可以下载源代码详细看看。
/** *//**
* 给定一个ip国家地区记录的偏移,返回一个IPLocation结构
* @param offset 国家记录的起始偏移
* @return IPLocation对象
*/
private IPLocation getIPLocation(long offset) {
try {
// 跳过4字节ip
ipFile.seek(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = ipFile.readByte();
if(b == REDIRECT_MODE_1) {
// 读取国家偏移
long countryOffset = readLong3();
// 跳转至偏移处
ipFile.seek(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = ipFile.readByte();
if(b == REDIRECT_MODE_2) {
loc.country = readString(readLong3());
ipFile.seek(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(ipFile.getFilePointer());
} else if(b == REDIRECT_MODE_2) {
loc.country = readString(readLong3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(ipFile.getFilePointer() - 1);
loc.area = readArea(ipFile.getFilePointer());
}
return loc;
} catch (IOException e) {
return null;
}
}
/** *//**
* 从offset偏移开始解析后面的字节,读出一个地区名
* @param offset 地区记录的起始偏移
* @return 地区名字符串
* @throws IOException 地区名字符串
*/
private String readArea(long offset) throws IOException {
ipFile.seek(offset);
byte b = ipFile.readByte();
if(b == REDIRECT_MODE_1 || b == REDIRECT_MODE_2) {
long areaOffset = readLong3(offset + 1);
if(areaOffset == 0)
return LumaQQ.getString("unknown.area");
else
return readString(areaOffset);
} else
return readString(offset);
}
/** *//**
* 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法
* 用了这么一个函数来做转换
* @param offset 整数的起始偏移
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/** *//**
* 从当前位置读取3个字节转换成long
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3() {
long ret = 0;
try {
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/** *//**
* 从offset偏移处读取一个以0结束的字符串
* @param offset 字符串起始偏移
* @return 读取的字符串,出错返回空字符串
*/
private String readString(long offset) {
try {
ipFile.seek(offset);
int i;
for(i = 0, buf[i] = ipFile.readByte(); buf[i] != 0; buf[++i] = ipFile.readByte());
if(i != 0)
return Utils.getString(buf, 0, i, "GBK");
} catch (IOException e) {
log.error(e.getMessage());
}
return "";
}代码并不复杂,getIPLocation是主要方法,它检查国家记录格式,并针对字符串形式,模式1,模式2采用不同的代码,readArea则相对简单,因为只有字符串和重定向两种情况需要处理。
总结
纯真IP数据库的结构使得查找IP简单迅速,不过你想要编辑它却是比较麻烦的,我想应该需要专门的工具来生成QQWry.dat文件,由于其文件格式的限制,你要直接添加IP记录就不容易了。不过,能查到IP已经很开心了,希望纯真记录越来越多~。
LumaQQ is a Java QQ client which has a reusablepure Java core and SWT-based GUI
简单安装过程:请各位注意安装顺序
----------------------------------------------------
(一)Apache:
装在默认目录。安装-自定义-全部选中。
----------------------------------------------------
(二)PHP:
第一步:压缩C:\php5目录下。
第二步:(将PHP目录添加到PATH环境变量中)开始 -> 控制面板 -> 系统 -> 高级 -> 环境变量 -> 系统变量 -> Path -> 双击 -> 加入“;C:\php5”
第三步:将C:\php5\php.ini-recommended 重命名为 php.ini 。
用记事本打开 php.ini ,查找register_globals = Off,把off改成On (有二处)
查找short_open_tag = Off,把off改成On 有一处
查找extension_dir = "./" 改为 extension_dir = "C:\php5\ext"
查找;extension=php_mbstring.dll,把下面几句前面的分号去掉
extension=php_mbstring.dll
extension=php_dba.dll
extension=php_dbase.dll
extension=php_filepro.dll
extension=php_gd2.dll
extension=php_imap.dll
extension=php_ldap.dll
extension=php_mysql.dll
修改了一些文件上传以及内存使用最大限制:
memory_limit = 20M 内存容量
post_max_size = 20M 闪存容量
upload_max_filesize = 20M 附件容量
保存退出。
第四步:(使php.ini文件在Windows下被PHP所用)
开始 -> 控制面板 -> 系统 -> 高级 -> 环境变量 -> 系统变量 -> 新建 -> 输入“PHPRC” -> 在“变量值”中输入 php.ini文件所在的目录(例如:C:\php5)
点击“确定”
Microsoft Windows 下的 Apache 2.0.x
先停止Apache
用记事本打开C:\Apache2\conf(可能在C:\Program Files\Apache Group\Apache2\conf)下的httpd.conf
这个文件我改了几个地方:
把PHP直接作为apache的一个模块运行,我在里面加了两句:
查找到 #LoadModule ssl_module modules/mod_ssl.so 在它的下面一行加上
LoadModule php5_module "C:/PHP5/php5apache2.dll"
AddType application/x-httpd-php .php 注意点前面有个空格滴,大家最好用复制粘贴
(新版apache2.2的php5apache2_2.dll在外面,放上去同理用)
我在D盘下建立了一个www的目录用于存放我的站点文件,在http.conf里改了这样一句话:
把
DocumentRoot "C:/Program Files/Apache Group/Apache2/htdocs"
改成了
DocumentRoot "D:/www"
所有
Apache2.0.x于1.3.x相比2.0.x默认不能直接列目录,如需,就改:
把DocumentRoot "E:/www"这句下的如下语句
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
改为:
<Directory />
Options Indexes FollowSymLinks
AllowOverride None
</Directory>
修改目录的默认首页:
如:DirectoryIndex index.htm index.html index.php index.html index.html.var
别的就没再动什么地方,保存后退出。
注意一点的是,要使以上所有这些配置生效需要重新启动电脑
最后我们来测试PHP是否正常载入。打开记事本,输入
<?php
phpinfo();
?>
保存,在弹出的窗口中,文件类型选所有文件,文件名为phpinfo.php,保存位置为网站目录下。如(E:\www\phpinfo.php)
打开IE浏览器输入:http://localhost/phpinfo.php 如果能正常显示就OK了。
-------------------------------------------------------
(三)Zend:
先停止Apache
安装Zend Optimizer也很简单,安装中它会两处提示其一:选择那种服务器?请选择Apache。其二:PHP.ini的路径?请选择C:\PHP5。其它的按默认配置安装就行了。OK安装完后我的Zend目录就是C:\Zend。
-------------------------------------------------------
(四)Mysql: