

jQuery 请求代码:
$.ajax({
url: "xxxxxx",
//method: "GET", // 默认 GET(当 dataType 为 jsonp 时此参数无效,始终以 GET 方式请求)
data: $('#myForm').serialize(), // 要传递的参数,这里提交表单 myForm 的内容
dataType: "jsonp"
//, jsonp: "callback" // 请求中的回调函数的参数名,默认值 callback
//, jsonpCallback: "jQuery_abc" // 本地回调函数名,不指定则随机
})
.done(function () {
alert("done");
if (true) {
$('#myForm')[0].reset();
}
})
.fail(function () { alert("fail"); })
.always(function () { alert("complete"); });
ASP.NET 处理代码:
JavaScriptSerializer jss = new JavaScriptSerializer();
string json = jss.Serialize(new { result = new { success = true, msg = "成功" } });
if (!string.IsNullOrWhiteSpace(Request["callback"])
&& Regex.IsMatch(Request["callback"], @"[_$a-zA-Z][$\w]*"))
{
Response.ContentType = "application/javascript; charset=utf-8";
Response.Write(json + Request["callback"] + "(" + json + ")");
}
else
{
Response.ContentType = "application/json; charset=utf-8";
Response.Write(json);
}
Response.End();


编者按:今天腾讯万技师同学的这篇技术总结必须强烈安利下,目录清晰,层次分明,每个接口都有对应的简介、系统要求、实例、核心代码以及超实用的思维发散,帮你直观把这些知识点get起来。以现在HTML 5的势头,同志们,你看到的这些,可都是钱呐。
十二年前,无论多么复杂的布局,在我们神奇的table面前,都不是问题;
十年前,阿捷的一本《网站重构》,为我们开启了新的篇章;
八年前,我们研究yahoo.com,惊叹它在IE5下都表现得如此完美;
六年前,Web标准化成了我们的基础技能,我们开始研究网站性能优化;
四年前,我们开始研究自动化工具,自动化测试,谁没玩过nodejs都不好意思说是页面仔;
二年前,各种终端风起云涌,响应式、APP开发都成为了我们研究的范围,CSS3动画开始风靡;
如今,CSS3动画、Canvas、SVG、甚至webGL你已经非常熟悉,你是否开始探寻,接下来,我们可以玩什么,来为我们项目带来一丝新意?
没错,本文就是以HTML5 Device API为核心,对HTML5的一些新接口作了一个完整的测试,希望能让大家有所启发。
目录:
一、让音乐随心而动 – 音频处理 Web audio API
二、捕捉用户摄像头 – 媒体流 Media Capture
三、你是逗逼? – 语音识别 Web Speech API
四、让我尽情呵护你 – 设备电量 Battery API
五、获取用户位置 – 地理位置 Geolocation API
六、把用户捧在手心 – 环境光 Ambient Light API
七、陀螺仪 Deviceorientation
八、Websocket
九、NFC
十、震动 - Vibration API
十一、网络环境 Connection API
一、让音乐随心而动 – 音频处理 Web audio API
简介:
Audio对象提供的只是音频文件的播放,而Web Audio则是给了开发者对音频数据进行分析、处理的能力,比如混音、过滤。
系统要求:
ios6+、android chrome、android firefox
实例:

http://sy.qq.com/brucewan/device-api/web-audio.html
核心代码:
var context = new webkitAudioContext();
var source = context.createBufferSource(); // 创建一个声音源
source.buffer = buffer; // 告诉该源播放何物
createBufferSourcesource.connect(context.destination); // 将该源与硬件相连
source.start(0); //播放
技术分析:
当我们加载完音频数据后,我们将创建一个全局的AudioContext对象来对音频进行处理,AudioContext可以创建各种不同功能类型的音频节点AudioNode,比如

1、源节点(source node)
我们可以使用两种方式加载音频数据:
<1>、audio标签
var sound, audio = new Audio();
audio.addEventListener('canplay', function() {
sound = context.createMediaElementSource(audio);
sound.connect(context.destination);
});
audio.src = '/audio.mp3';
<2>、XMLHttpRequest
var sound, context = createAudioContext();
var audioURl = '/audio.mp3'; // 音频文件URL
var xhr = new XMLHttpRequest();
xhr.open('GET', audioURL, true);
xhr.responseType = 'arraybuffer';
xhr.onload = function() {
context.decodeAudioData(request.response, function (buffer) {
source = context.createBufferSource();
source.buffer = buffer;
source.connect(context.destination);
}
}
xhr.send();
2、分析节点(analyser node)
我们可以使用AnalyserNode来对音谱进行分析,例如:
var audioCtx = new (window.AudioContext || window.webkitAudioContext)();
var analyser = audioCtx.createAnalyser();
analyser.fftSize = 2048;
var bufferLength = analyser.frequencyBinCount;
var dataArray = new Uint8Array(bufferLength);
analyser.getByteTimeDomainData(dataArray);
function draw() {
drawVisual = requestAnimationFrame(draw);
analyser.getByteTimeDomainData(dataArray);
// 将dataArray数据以canvas方式渲染出来
};
draw();
3、处理节点(gain node、panner node、wave shaper node、delay node、convolver node等)
不同的处理节点有不同的作用,比如使用BiquadFilterNode调整音色(大量滤波器)、使用ChannelSplitterNode分割左右声道、使用GainNode调整增益值实现音乐淡入淡出等等。
需要了解更多的音频节点可能参考:
https://developer.mozilla.org/en-US/docs/Web/API/Web_Audio_API
4、目的节点(destination node)
所有被渲染音频流到达的最终地点
思维发散:
1、可以让CSS3动画跟随背景音乐舞动,可以为我们的网页增色不少;
2、可以尝试制作H5酷酷的变声应用,增加与用户的互动;
3、甚至可以尝试H5音乐创作。
看看google的创意:http://v.youku.com/v_show/id_XNTk0MjQyNDMy.html
二、捕捉用户摄像头 – 媒体流 Media Capture
简介:
通过getUserMedia捕捉用户摄像头获取视频流和通过麦克风获取用户声音。
系统要求:
android chrome、android firefox
实例:
捕获用户摄像头 捕获用户麦克风

http://sy.qq.com/brucewan/device-api/camera.html

http://sy.qq.com/brucewan/device-api/microphone-usermedia.html
核心代码:
1、摄像头捕捉
navigator.webkitGetUserMedia ({video: true}, function(stream) {
video.src = window.URL.createObjectURL(stream);
localMediaStream = stream;
}, function(e){
})
2、从视频流中拍照
btnCapture.addEventListener('touchend', function(){
if (localMediaStream) {
canvas.setAttribute('width', video.videoWidth);
canvas.setAttribute('height', video.videoHeight);
ctx.drawImage(video, 0, 0);
}
}, false);
3、用户声音录制
navigator.getUserMedia({audio:true}, function(e) {
context = new audioContext();
audioInput = context.createMediaStreamSource(e);
volume = context.createGain();
recorder = context.createScriptProcessor(2048, 2, 2);
recorder.onaudioprocess = function(e){
recordingLength += 2048;
recorder.connect (context.destination);
}
}, function(error){});
4、保存用户录制的声音
var buffer = new ArrayBuffer(44 + interleaved.length * 2);
var view = new DataView(buffer);
fileReader.readAsDataURL(blob); // android chrome audio不支持blob
… audio.src = event.target.result;
思维发散:
1、从视频拍照自定义头像;
2、H5视频聊天;
3、结合canvas完成好玩的照片合成及处理;
4、结合Web Audio制作有意思变声应用。
三、你是逗逼? – 语音识别 Web Speech API简介:
1、将文本转换成语音;
2、将语音识别为文本。
系统要求:
ios7+,android chrome,android firefox
测试实例:

http://sy.qq.com/brucewan/device-api/microphone-webspeech.html
核心代码:
1、文本转换成语音,使用SpeechSynthesisUtterance对象;
var msg = new SpeechSynthesisUtterance();
var voices = window.speechSynthesis.getVoices();
msg.volume = 1; // 0 to 1
msg.text = ‘识别的文本内容’;
msg.lang = 'en-US';
speechSynthesis.speak(msg);
2、语音转换为文本,使用SpeechRecognition对象。
var newRecognition = new webkitSpeechRecognition();
newRecognition.onresult = function(event){
var interim_transcript = '';
for (var i = event.resultIndex; i < event.results.length; ++i) {
final_transcript += event.results[i][0].transcript;
}
};
测试结论:
1、Android支持不稳定;语音识别测试失败(暂且认为是某些内置接口被墙所致)。
思维发散:
1、当语音识别成为可能,那声音控制将可以展示其强大的功能。在某些场景,比如开车、网络电视,声音控制将大大改善用户体验;
2、H5游戏中最终分数播报,股票信息实时声音提示,Web Speech都可以大放异彩。
四、让我尽情呵护你 – 设备电量 Battery API简介:
查询用户设备电量及是否正在充电。
系统要求:
android firefox
测试实例:

http://sy.qq.com/brucewan/device-api/battery.html
核心代码:
var battery = navigator.battery || navigator.webkitBattery || navigator.mozBattery || navigator.msBattery;
var str = '';
if (battery) {
str += '<p>你的浏览器支持HTML5 Battery API</p>';
if(battery.charging) {
str += '<p>你的设备正在充电</p>';
} else {
str += '<p>你的设备未处于充电状态</p>';
}
str += '<p>你的设备剩余'+ parseInt(battery.level*100)+'%的电量</p>';
} else {
str += '<p>你的浏览器不支持HTML5 Battery API</p>';
}
测试结论:
1、QQ浏览器与UC浏览器支持该接口,但未正确显示设备电池信息;
2、caniuse显示android chrome42支持该接口,实测不支持。
思维发散:
相对而言,我觉得这个接口有些鸡肋。
很显然,并不合适用HTML5做电池管理方面的工作,它所提供的权限也很有限。
我们只能尝试做一些优化用户体验的工作,当用户设备电量不足时,进入省电模式,比如停用滤镜、摄像头开启、webGL、减少网络请求等。
五、获取用户位置 – 地理位置 Geolocation简介:
Geolocation API用于将用户当前地理位置信息共享给信任的站点,目前主流移动设备都能够支持。
系统要求:
ios6+、android2.3+
测试实例:

http://sy.qq.com/brucewan/device-api/geolocation.html
核心代码:
var domInfo = $("#info");
// 获取位置坐标
if (navigator.geolocation) {
navigator.geolocation.getCurrentPosition(showPosition,showError);
}
else{
domInfo.innerHTML="抱歉,你的浏览器不支持地理定位!";
}
// 使用腾讯地图显示位置
function showPosition(position) {
var lat=position.coords.latitude;
var lon=position.coords.longitude;
mapholder = $('#mapholder')
mapholder.style.height='250px';
mapholder.style.width = document.documentElement.clientWidth + 'px';
var center = new soso.maps.LatLng(lat, lon);
var map = new soso.maps.Map(mapholder,{
center: center,
zoomLevel: 13
});
var geolocation = new soso.maps.Geolocation();
var marker = null;
geolocation.position({}, function(results, status) {
console.log(results);
var city = $("#info");
if (status == soso.maps.GeolocationStatus.OK) {
map.setCenter(results.latLng);
domInfo.innerHTML = '你当前所在城市: ' + results.name;
if (marker != null) {
marker.setMap(null);
}
// 设置标记
marker = new soso.maps.Marker({
map: map,
position:results.latLng
});
} else {
alert("检索没有结果,原因: " + status);
}
});
}
测试结论:
1、Geolocation API的位置信息来源包括GPS、IP地址、RFID、WIFI和蓝牙的MAC地址、以及GSM/CDMS的ID等等。规范中没有规定使用这些设备的先后顺序。
2、初测3g环境下比wifi环境理定位更准确;
3、测试三星 GT-S6358(android2.3) geolocation存在,但显示位置信息不可用POSITION_UNAVAILABLE。
六、把用户捧在手心 – 环境光 Ambient Light简介:
Ambient Light API定义了一些事件,这些时间可以提供源于周围光亮程度的信息,这通常是由设备的光感应器来测量的。设备的光感应器会提取出辉度信息。
系统要求:
android firefox
测试实例:

http://sy.qq.com/brucewan/device-api/ambient-light.html
核心代码:
这段代码实现感应用前当前环境光强度,调整网页背景和文字颜色。
var domInfo = $('#info');
if (!('ondevicelight' in window)) {
domInfo.innerHTML = '你的设备不支持环境光Ambient Light API';
} else {
var lightValue = document.getElementById('dl-value');
window.addEventListener('devicelight', function(event) {
domInfo.innerHTML = '当前环境光线强度为:' + Math.round(event.value) + 'lux';
var backgroundColor = 'rgba(0,0,0,'+(1-event.value/100) +')';
document.body.style.backgroundColor = backgroundColor;
if(event.value < 50) {
document.body.style.color = '#fff'
} else {
document.body.style.color = '#000'
}
});
}
思维发散:
该接口适合的范围很窄,却能做出很贴心的用户体验。
1、当我们根据Ambient Light强度、陀螺仪信息、当地时间判断出用户正躺在床上准备入睡前在体验我们的产品,我们自然可以调整我们背景与文字颜色让用户感觉到舒适,我们还可以来一段安静的音乐,甚至使用Web Speech API播报当前时间,并说一声“晚安”,何其温馨;
2、该接口也可以应用于H5游戏场景,比如日落时分,我们可以在游戏中使用安静祥和的游戏场景;
3、当用户在工作时间将手机放在暗处,偷偷地瞄一眼股市行情的时候,我们可以用语音大声播报,“亲爱的,不用担心,你的股票中国中车马上就要跌停了”,多美的画面。
参考文献:
https://developer.mozilla.org/en-US/docs/Web/API
http://webaudiodemos.appspot.com/
http://www.w3.org/2009/dap/
数据库设计规范是个技术含量相对低的话题,只需要对标准和规范的坚持即可做到。当系统越来越庞大,严格控制数据库的设计人员,并且有一份规范书供执行参考。在程序框架中,也有一份强制性的约定,当不遵守规范时报错误。
以下20个条款是我从一个超过1000个数据库表的大型ERP系统中提炼出来的设计约定,供参考。
1 所有的表的第一个字段是记录编号Recnum,用于数据维护
[Recnum] [decimal] (8, 0) NOT NULL IDENTITY(1, 1)
在进行数据维护的时候,我们可以直接这样写:
UPDATE Company SET Code='FLEX' WHERE Recnum=23
2 每个表增加4个必备字段,用于记录该笔数据的创建时间,创建人,最后修改人,最后修改时间
[CreatedDate] [datetime] NULL, [CreatedBy] [nvarchar] (10) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [RevisedDate] [datetime] NULL, [RevisedBy] [nvarchar] (10) COLLATE SQL_Latin1_General_CP1_CI_AS NULL
框架程序中会强制读取这几个字段,默认写入值。
3 主从表的主外键设计
主表用参考编号RefNo作为主键,从表用RefNo,EntryNo作为主键。RefNo是字符串类型,可用于单据编码功能中自动填写单据流水号,从表的EntryNo是行号,LineNo是SQL Server 的关键字,所以用EntryNo作为行号。
如果是三层表,则第三层表的主键依次是RefNo,EntryNo,DetailEntryNo,第三个主键用于自动增长行号。
4 设计单据状态字段
| 字段 | 含义 |
| Posted | 过帐,已确认 |
| Closed | 已完成 |
| Cancelled | 已取消 |
| Approved | 已批核 |
| Issued | 已发料 |
| Finished | 已完成 |
| Suspended | 已取消 |
5 字段含义相近,把相同的单词调成前缀。
比如工作单中的成本核算,人工成本,机器成本,能源成本,用英文表示为LaborCost,MachineCost,EnergyCost
但是为了方便规组,我们把Cost调到字段的前面,于是上面三个字段命名为CostLabor,CostMachine,CostEnergy。
可读性后者要比前者好一点,Visual Studio或SQL Prompt智能感知也可帮助提高字段输入的准确率。
6 单据引用键命名 SourceRefNo SourceEntryNo
销售送货Shipment会引用到是送哪张销售单据的,可以添加如下引用键SourceRefNo,SourceEntryNo,表示送货单引用的销售单的参考编号和行号。Source开头的字段一般用于单据引用关联。
7 数据字典键设计
比如员工主档界面的员工性别Gender,我的方法是在源代码中用枚举定义。性别枚举定义如下:
public enum Gender
{
[StringValue("M")]
[DisplayText("Male")]
Male,
[StringValue("F")]
[DisplayText("Female")]
Female
}
在代码中调用枚举的通用方法,读取枚举的StringValue写入到数据库中,读取枚举的DisplayText显示在界面中。
经过这一层设计,数据库中有关字典方面的设计就规范起来了,避免了数据字典的项的增减给系统带来的问题。
8 数值类型字段长度设计
Price/Qty 数量/单价 6个小数位 nnnnnnnnnn.nnnnnn 格式 (10.6)
Amount 金额 2个小数位 nnnnnnnnnnnn.nn 格式(12.2)
Total Amt 总金额 2个小数位 nnnnnnnnnnnnnn.nn 格式(14.2)
参考编号默认16个字符长度,不够用的情况下增加到30个字符,再不够用增加到60个字符。这样可以保证每张单据的第一个参考编号输入控件看起来都是一样长度。
除非特别需求,一般而言,界面中控件的长度取自映射的数据库中字段的定义长度。
9 每个单据表头和明细各增加10个自定义字段,基础资料表增加20个自定义字段
参考供应商主档的自定义字段,自定义字段的名称统一用UserDefinedField。
ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_1] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_2] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_3] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_4] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_5] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_6] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_7] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_8] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_9] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_10] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_11] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_12] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_13] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_14] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_15] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_16] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_17] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_18] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_19] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ALTER TABLE Vendor ADD COLUMN [USER_DEFINED_FIELD_20] nvarchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL
10 多货币(本位币)转换字段的设计
金额或单价默认是以日记帐中的货币为记录,当默认货币与本位币不同时需要同时记录下本位币的值。
销售单销售金额 SalesAmount或SalesAmt,本位币字段定义为SalesAmountLocal或SalesAmtLocal
通常是在原来的字段后面加Local表示本位币的值。
11 各种日期字段的设计
| 字段名称 | 含义 |
| TranDate | 日期帐日期 Tran是Transaction的简写 |
| PostedDate | 过帐日期 |
| ClosedDate | 完成日期 |
| InvoiceDate | 开发票日期 |
| DueDate | 截止日期 |
| ScheduleDate | 计划日期,这个字段用在不同的单据含义不同。比如销售单是指送货日期,采购单是指收货日期。 |
| OrderDate | 订单日期 |
| PayDate | 付款日期 |
| CreatedDate | 创建日期 |
| RevisedDate | 修改日期 |
| SettleDate | 付款日期 |
| IssueDate | 发出日期 |
| ReceiptDate | 收货日期 |
| ExpireDate | 过期时间 |
12 财务有关的单据包含三个标准字段
FiscalYear 财年,PeriodNo 会计期间,Period 前面二个的组合。以国外的财年为例子,FiscalYear是2015,PeriodNo是4,Period是2015/04。
欧美会计期间是从每年的4月份开始,需要注意的是会计期间与时间没有必然的联系,看到会计期间是2015/04,不一定是表示2015的4月份,它只是说这是2015财年的第四期,具体在哪个时间段需要看会计期间定义。
13 单据自动生成 DirectEntry
有些单据是由其它单据生成过来的,逻辑上应该不支持编辑。比如销售送货Shipment单会产生出仓单,出仓单应该不支持编辑,只能做过帐扣减库存操作。这时需要DirectEntry标准字段来表示。当手工创建一张出仓单时,将DirectEntry设为true,表示可编辑单据中的字段值,当由其它单据传递产生过来产生的出仓单,将DirectEntry设为false,表示不能编辑此单据。这种情况还发生在业务单据产生记帐凭证(Voucher)的功能中,如果可以修改由原始单据传递过来的数量金额等字段,则会导致与源单不匹配,给系统对帐产生困扰。
14 百分比值字段的设计
Percentage百分比值,用于折扣率,损耗率等相关比率设定的地方。推荐用数值类型表示,用脚本表示是
[ScrapRate] [decimal] (5, 2) NULL
预留两位小数,整数部分支持1-999三位数。常常是整数部分2位就可以,用3位也是为了支持一些特殊行业(物料损耗率超过100)的要求。
15 日志表记录编号LogNo字段设计
LogNo字段的设计有些巧妙,以出仓单为例子,一张出仓单有5行物料明细,每一行物料出仓都会扣减库存,再写物料进出日记帐,因为这五行物料出仓来自同一个出仓单,于是将这五行物料的日记帐中的LogNo都设为同一个值。于在查询数据时,以这个字段分组即可看到哪些物料是在同一个时间点上出仓的,对快速查询有很重要的作用。
16 基础资料表增加名称,名称长写,代用名称三个字段
比如供应商Vendor表,给它加以下三个字段:
Description 供应商名称,比如微软公司。
ExtDescription 供应商名称长写,比如电气行业的南网的全名是南方国家电网有限公司。
AltDescription 供应商名称替代名称,用在报表或是其它单据引用中。比如采购单中的供应商是用微软,还是用代用名称Microsoft,由参数(是否用代用名称)控制。
17 文件类表增加MD5 Hash字段
比如产品数据管理系统要读取图纸,单据功能中增加的附件文件,这类涉及文件读写引用的地方,考虑存放文件的MD5哈希值。文件的MD5相当于文件的唯一识别身份,在网上下载文件时,网站常常会放出文件的MD5值,以方便对比核对。当下载到本机的文件的MD5值与网站上给出的值不一致时,有可能这个文件被第三方程序修改过,不可信任。
18 数据表的主键用字符串而不是数字
比如销售单中的货币字段,是存放货币表的货币字符串值RMB/HKD/USD,还是存放货币表的数字键,1/2/3。
存放前者对于报表制作相对容易,但是修改起来相对麻烦。存放后者对修改数据容易,但对报表类或查询类操作都需要增加一个左右连接来看数字代表的货币。金蝶使用的是后者,它的BOS系统也不允许数据表之间有直接的关联,而是间接通过Id值来关联表。
在我看到的系统中,只有一个会计期间功能(财年Fiscal Year)用到数字值作主键,其余的单据全部是字符串做主键。
19 使用约定俗成的简写
模块Module 简写
| 简写 | 全名 |
| SL | Sales 销售 |
| PU | Purchasing 采购 |
| IC | Inventory 仓库 |
| AR | Account Receivable 应收 |
| AP | Account Payable 应付 |
| GL | General Ledger 总帐 |
| PR | Production 生产 |
名称Name 简写
| 简写 | 全名 |
| Uom | Unit of Measure 单位 |
| Ccy | Currency 货币 |
| Amt | Amount 金额 |
| Qty | Quantity 数量 |
| Qty Per | Quantity Per 用量 |
| Std Output | Standard Output 标准产量 |
| ETA | Estimated Time of Arrival 预定到达时间 |
| ETD | Estimated Time of Departure 预定出发时间 |
| COD | Cash On Delivery 货到付款 |
| SO | Sales Order 销售单 |
| PO | Purchase Order 采购单 |
20 库存单据数量状态
Qty On Hand 在手量
Qty Available 可用量
Qty On Inspect 在验数量
Qty On Commited 提交数量
Qty Reserved 预留数量
以上每个字段都有标准和行业约定的含义,不可随意修改取数方法。
去年,我们分享了《40个良好用户界面Tips》,对设计师来说确实很有帮助,今年,Goodui.org已经更新至71条,这些原则都是由Goodui官方精心整理,认为这些都是非常重要的设计要点,所以对于设计师来说,建议学习一下。
01 尝试使用一列的布局替代多列布局

02 给用户一些小的利益,别看上去那么赤裸裸
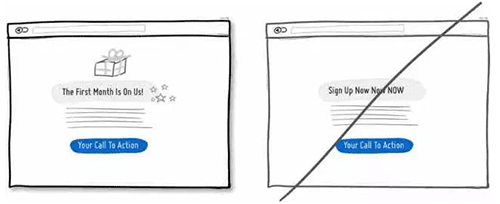
03 合并相似的功能

04 尝试展示来自用户的赞扬,而不是自我表扬

05 重复核心行动点

06 统一视觉规范,提升可识别性

07 尝试使用推荐的口吻,而不是让用户感觉面对一台冷冰冰的机器
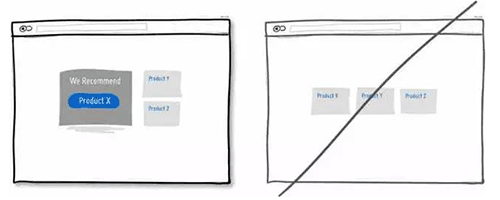
08 给用户吃「后悔药」的机会
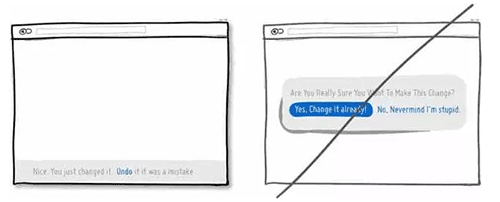
09 告诉用户产品适用的人群,而不是人人都通用

10 将文案写得更加的直接,而不是一堆废话
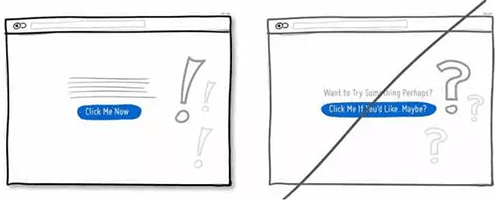
11 增强主行动点的视觉冲击力,提升它在页面中的可对比性
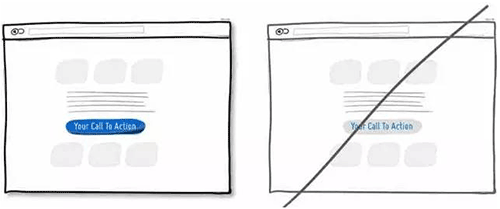
12 让用户知道你从哪儿来更易于拉近与用户的关系
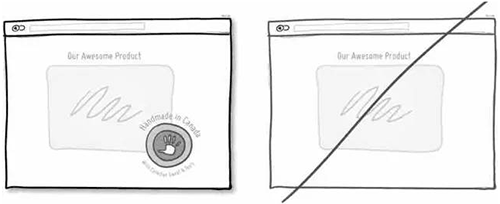
13 将表单做的简单点,确保用户在抓狂之前能进入下一步

14 尽量将用户需要选择的信息展示出来而不是藏起来

15 页面的排版需要考虑用户是否会漏掉底部信息

16 如果页面的底部有需要关注的行动点,别让文中过多的外链带走了用户

17 确保用户知道自己目前的状态

18 将利益点融合在行动点中,增强用户的点击欲望
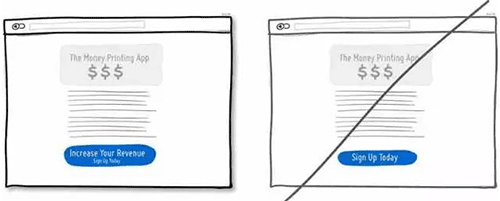
19 将行动点与当前信息结合起来

20 将简要的表单合并到页面中,减少调整页面带来的用户流失

21 适当的增加延迟动效,让用户感知到页面的变化
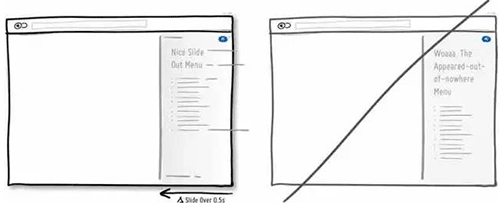
22 让新用户从尝试产品入手,而不是一来就面对冷冰冰的注册表单
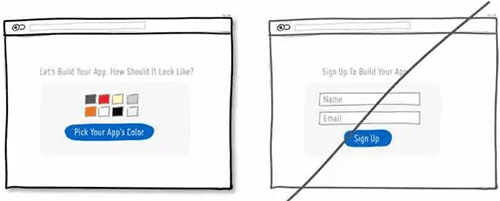
23 减少使用线框,这会过多的吸引用户注意力,而且会让页面看上去透不过气
24 给用户推销你能给他带来的利益,而不是功能

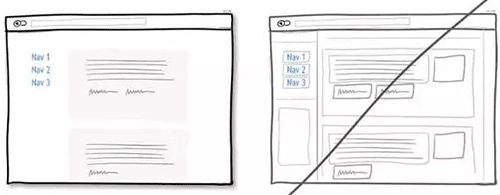
25 一定要注意0结果页面的设计,这也是引导用户的好地方
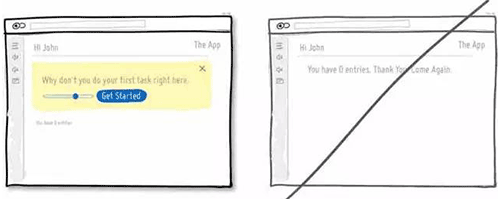
26 给用户选择退出的权利,特别是邮件订阅

27 注意界面元素的一致性,降低用户学习成本

28 给下拉框增加一些预设值,降低用户填写成本
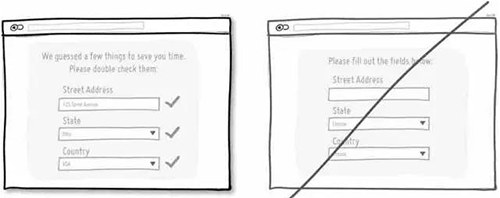
29 延续用户日常的使用习惯,而不是重新创造

30 尝试告诉用做些事情降低自己的损失,而不是提升收益
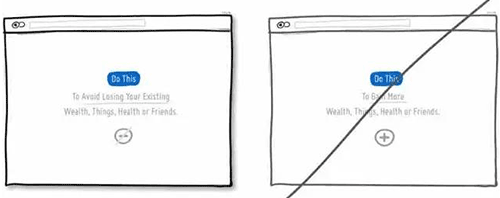
31 提升页面的视觉层次,增强可阅读性

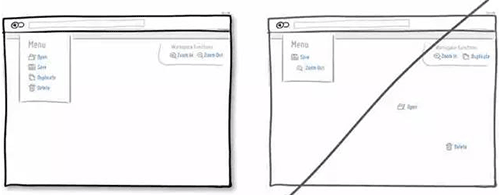
32 将同类的操作合并在一起,降低用户的认知成本
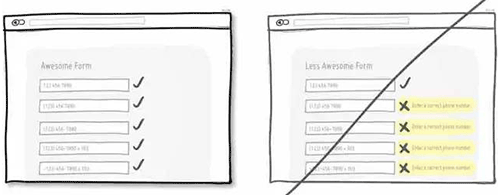
33 表单及时校验,而不是统一提交后在告诉用户填错了

34 尝试将表单输入变得更加宽容,让用户的填写更加简单
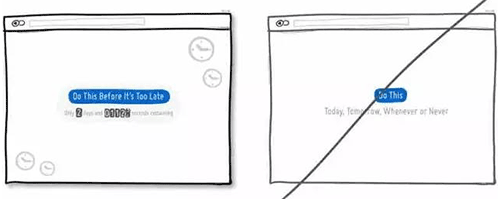
35 通过时间增强紧迫感
36 提供用户可预见性的操作,降低用户的心理成本
37 尽可能的帮助用户选择,而不是让用户想破脑袋
38 尽可能将操作区域放大,降低用户操作成本
39 页面加载速度很重要,尽可能让用户感受到你的网站速度很快
40 如果可以,增加键盘快捷键,提升操作效率
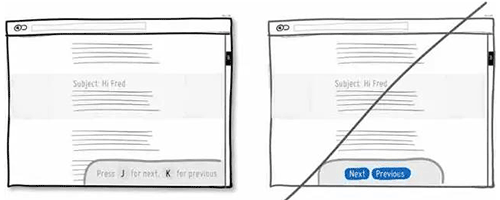
41 尝试通过对比来让用户感知到性价比
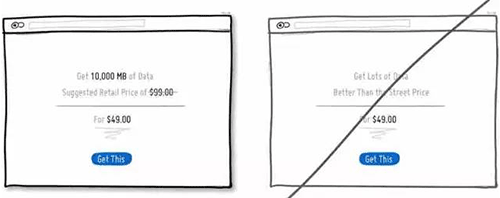
42 尝试对进度条进行「设计」来降低用户等待的焦虑

43 根据用户选择逐步展示信息,降低无效信息对用户的干扰

44 有时候较小的承诺比「夸海口」会更容易让用户信服

45 尝试将提示信息弱化,减少对用户操作的干扰
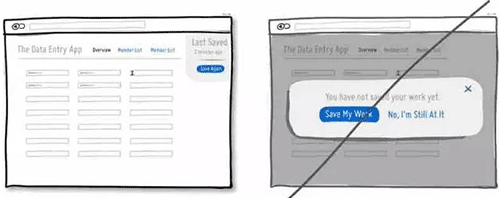
46 尽量通过系统的功能来简化用户的操作
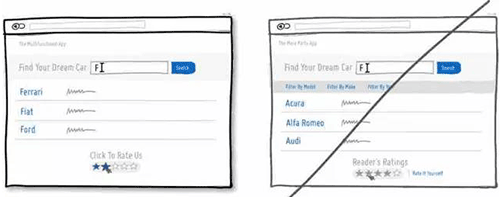
47 用文本配合图标来降低用户的认知成本

48 用更自然的语言代替冷冰冰的机器

49 放出一些摘要信息来帮助用户识别是否需要进一步了解
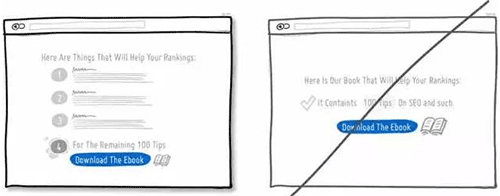
50 在关键的页面增加用户权益信息,增强用户进一步操作的信心
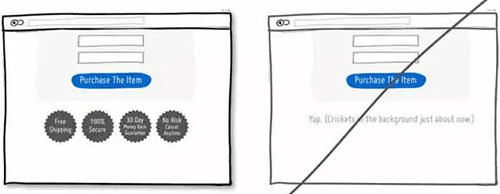
51 将价格进行换算,让用户感觉这很便宜
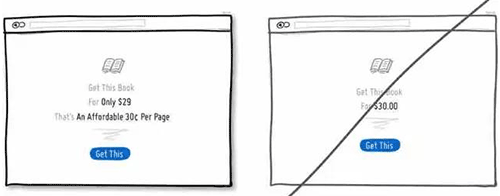
52 记得在成功页面感谢用户
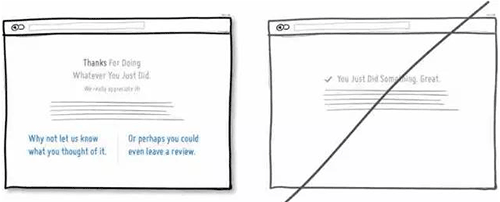
53 将数字转化成易于用户阅读的形式,而不是冷冰冰的机器语言
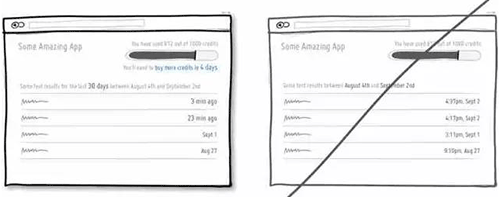
54 告诉用户选择的权利和自由「诱惑力」
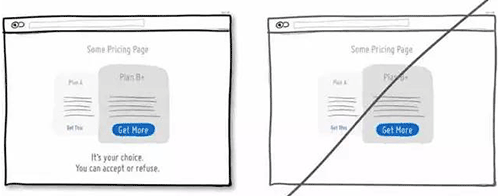
55 尝试让语言更具「诱惑力」
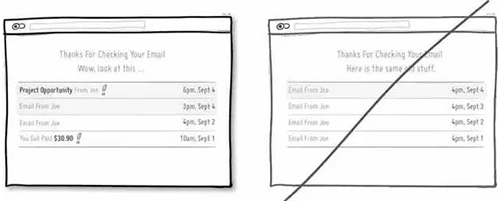
56 通过设计引导用户的注意力
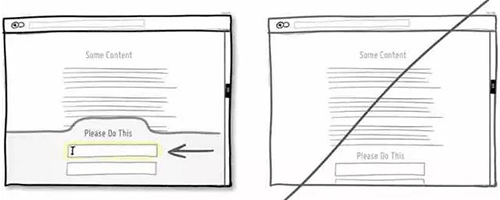
57 通过友好的对比来展示产品,为用户做决定提供帮助

58 通过任务机制来提升用户的满足感
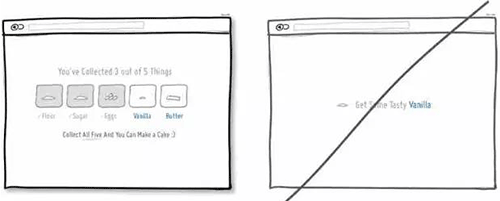
59 让用户了解接下来将要发生什么事情

60 尝试用更幽默一些的语言文案

61 任何操作之后都要给出反馈,让用户知道操作已经生效

62 注意动效的真实使用情况(Amazon 的类目菜单就是一个很好的例子)

63 注意排版的,不要让信息过于拥挤
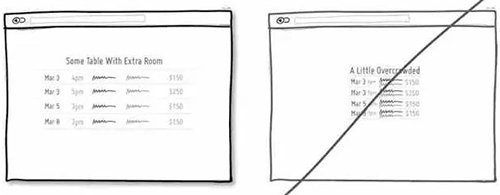
64 尝试用讲故事的方式来传递信息,增强用户的代入感

65 尽量给用户展示真实的信息,不要欺骗

66 随着用户的不断熟悉简化界面
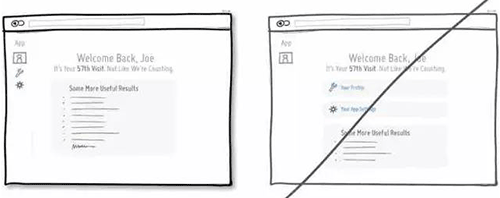
67 试着用用户的口吻展示信息
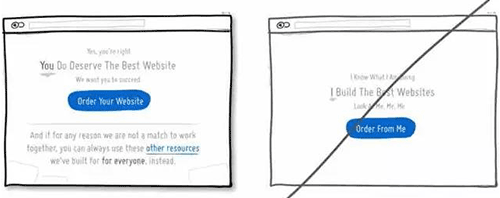
68 在表单中增加一些提示信息,减少错误的几率
69 用简单的文案传递核心关注的信息,少一些废话

70 尝试使用响应式布局
71 视觉表达要清晰,而不是模棱两可
这71条设计原则虽然针对 Web 设计,但有些部分在移动产品设计中同样有效。翻译过程只保留了图片和标题,更多详细内容可以访问 GoodUI 官网:
http://goodui.org/
原文:http://mathewsanders.com/designing-adaptive-layouts-for-iphone-6-plus/
翻译:叮当当咚当当小胖妞呀
从IOS6开始,苹果公司就一直建议我们使用自适应布局,但是迄今为止,我发现大家都在回避这个问题,考虑的最多的仍然是固定布局。
iPhone 6的上市让人们很难再去逃避自适应布局这个问题,四种屏幕尺寸(如果要支持iPad就要上升到5种)、三种分辨率和转向似乎让着手于自适应布局变得更加简单。

在文章的最后,你应该能流畅使用 storyboards、 约束(constraints)和 size class特性,这三个是Apple为开发和制作自适应布局提供的Xcode工具。
所以下载Xcode6,给自己来杯饮料,留上一个小时的时间,让我们开始吧!
- Storyboards
- 模拟尺寸
- 约束
- 头部和尾部空间
- 横向空间约束
- 同等宽度约束
- 纵横比约束
- 约束管理
- 添加约束
- 检查和编辑现有约束
- 删除约束
- 布局问题和冲突
- 错位视图警告
- 约束缺失错误
- Size Classes
- 宽度和高度特性
- 我们的目标…
- 为通用的size class添加约束
- 为iPhone纵向布局添加约束
- 为iPhone横向布局添加约束
- 编辑助手:设备预览
- 为iPad布局添加约束
- 使用布局和间隔视图
- 布局视图样例
- 间隔视图样例
- 下一步
Storyboards
Xcode中,storyboards可以让你在屏幕上拖动和放置原生对象(例如按钮、图片、文本框和标签)并且定义每个屏幕之间如何连接。
在Xcode专业术语中,可以看到、摸到、互动的用户界面元素,我们称之为 视图(按钮、图片、文本框、标签等等)。
包含并管理所有那些视图的屏幕被称为 视图控制器,我倾向于交替使用这些术语。
当我们在一个storyboard上添加视图控制器的时候,它的纵横比其实跟任何设备都不匹配,事实上,它是一个完美的600pt*600pt的正方形:

这提醒了我们,storyboard屏幕并不代表特定硬件上的屏幕,而是 任何IOS设备的抽象表现。
模拟尺寸
也许你不介意在600pt*600pt的画布上操作,但是在实际大小上操作可能会更有帮助。
我们可以非常方便的在Xcode里改变视图控制器模拟的尺寸和转向:

约束
向你们展示约束的最好方法是实例。
我们先创建一个简单的包含一个屏幕的storyboard(模拟4英寸iPhone的尺寸),再添加两个相邻的正方形。

当我们在竖屏中运行app的时候,这两个正方形完全按照我们的布局排列,当我们变成横屏时,它们仍然忠于自己的坐标:

当我们使用iPhone 6模拟器运行项目的时候,我们可以再一次看到,我们的布局并没有自适应不同的屏幕尺寸,屏幕右边多出了可见的空白区域。

这是由于没有约束,这些对象仍然会按照我们在storyboard上创建的x,y坐标和面积来定位。
所以让我们开始添加约束,看看会对它们有些什么影响。
头部和尾部空间
我们在蓝色方块前添加10pt的头部空间约束,在红色方块后添加10pt的尾部空间约束。

当我们运行项目的时候,约束把蓝色方块固定在屏幕左侧,把红色方块固定在右侧。

横向空间约束
我们在两个方块之间再添加一个10pt的横向空间约束,就像上一个约束一样,这样会让两个方块之间有一个固定的空间。

当我们运行项目的时候,会发现一个意料之外的结果:我们所有的约束都满足了,但是为了满足所有约束,其中一个方块被拉伸了。
这似乎告诉我们这样一件事:除非被告知,否则IOS会尽量让大多数对象都保持“自然”大小。

同等宽度约束
我们添加一个同等宽度约束。

当运行项目的时候,我们可以看到两个方块宽度的增量相同。

纵横比约束
最后,对两个方块添加纵横比约束。

这个约束保证了宽度和高度的比永远是相同的。
当我们运行app的时候,我们可以看到每个方块的宽度在增加,高度也同时在增加。

用iPhone 6模拟器运行项目,覆盖我们之前添加过的约束,你可以看到这两个正方形是如何利用可用空间来拉伸的。

约束管理
现在你已经看到了我们是如何使用约束的,下面我们来介绍一下具体操作。
提示:尽量少使用约束
添加约束的一个要点是试着挑战自己,越少使用约束越好。
虽然我并不认为添加的约束数量能够很大程度上影响IOS的性能,但是越少的使用约束,你的布局就会越好维护。
添加约束
在storyboard中添加约束有三个方法:
- 约束弹窗也许最好的方法就是选择一个或多个对象,从其中一个弹窗中添加约束。我认为这是个很好的方法,因为可以看到现有约束的范围。如果有一条约束不可用,可能就意味着你需要两个或更多对象来实施这条约束。

- ctrl + 拖动你可以按住ctrl键,同时拖动到一个对象上(可以是相邻对象、父级对象或者是自身),会出现一个浮层告诉你可以被添加的约束有哪些。这是我最喜欢的添加约束的方法,因为你不需要把你的鼠标移动到大老远的底部再回到对象。

- 菜单/绑定你也可以选择一个或多个对象,在菜单中点击 editor -> pin来选择约束,这其实是最没有效率的方法,但是如果你发现自己不停的重复添加一种约束,也许为一个或多个选项添加绑定更合理一点。
检查和编辑现有约束
检查视图中应用的约束最简单的办法就是选择视图,切换到Size检查面板。
或者在文档大纲层次面板中切换constant数值。
无论是哪种方法,选择约束可以让你直接更新它。

删除约束
同样的,约束也可以通过高亮+点击删除按钮来删除。
要删除一个视图的所有约束,或者屏幕中的所有约束,在布局问题弹窗中有一条捷径:
![]()
布局问题和冲突
当我们在storyboard中添加约束的时候,Xcode总会给出一些关于这些约束的警告或者错误。
有时候这些问题可以忽略不计,但是更多的时候,它们必须被解决。
查看约束警告和错误最好在文档大纲面板中,每个视图控制器会有一个红色或者黄色的icon来表示是不是有布局问题:

错位视图警告
一个比较常见的警告是错位视图警告,如果约束规定这个视图应该在的地方,和这个视图实际在的地方不匹配,那么这种警告随时会出现。
当你转换模拟尺寸或者不小心用鼠标移动了一个视图,这些警告也会出现。
点击一个错位的视图,屏幕上会出现一个虚线框,告诉你约束规定了这个视图应该在的位置。

如果点击警告,会出现一个带有几个选项的浮层,你可以选择让Xcode更新约束来匹配storyboard上的位置,也可以让Xcode更新框架来移动或者拉伸视图,使它们回到约束规定的位置。
缺失约束错误
让我们回到一开始蓝方块和红方块的例子,我们没有添加过一个关于纵向位置的约束,但当我们运行app的时候看起来完全没问题,因为IOS会认为纵向位置就是我们在storyboard上放置的位置,不过为了避免一些意料之外的行为,我们最好还是规定一下。
在 顶部布局向导添加顶部空间约束可以消除一些说不定道不明的约束和错误。

Size Classes
为了在大多数基础布局或者更高级的布局上使用约束,你需要同时使用size classes。
Size classes是一种能够告诉你物理设备宽度和高度的特性。
当我们在storyboard的屏幕上添加对象或者约束时,只有设备符合当前的宽高特性,对象才会显现,约束才会被应用。
这是一个非常有用的方法,它让我们确定了不同设备和转向下布局的变化。
高度和宽度特性
使用 紧凑(compact)、 任意(any)和 正常(regular)这三种的组合,可以让我们确定一些范围内的设备布局。
虽然不能涉及每一个变化(比如不能确定iPhone 6 Plus的竖向模式,也不能让iPad的转向消失),但是大多数的变化都可以确定。

我们说过,介绍size classes最简单的方法是实例,所以让我们看一个例子。
我们的目标…
作为例子,我们做一个Instagram详情页的简单版本,可以适应大屏和转向。
我们的目标是创建一个布局,它可以机智的适应更大的iPhone 6设备(我说的机智,是指只有照片会放大,其他的元素如头像照片仍然不变),并且当设备横屏的时候,图片和元数据会并肩排列,而不是像竖屏时的上下排列。

为通用的size class添加约束
跟之前的例子不同,这次我们不使用模拟尺寸度量,我们使用通用size class的抽象方形布局,这样会使我们记住,为这个size class添加的任何视图和约束,只能是那些添加在任意屏幕尺寸和转向上的视图和约束。
我们需要用到这些约束:

除了必要的空间、间隙和纵横比约束,我们还需要让某些对象排列在顶部或者底部。
现在,在你的storyboard上添加视图和约束吧。做这步的时候,我的storyboard长这样:

注意,现在我们有了所有转向上所需要的元素,但是我没有费心完成每个转向上的布局,下一步我们才会做!
为iPhone纵向布局添加约束
现在,我们把size class切换到 紧凑宽度和 正常高度,这个尺寸特性的组合适用于任何竖屏下的iPhone设备。
如果要切换size classes,点击storyboard中下方的size class标签,选择你想要看到的宽高组合。

注意,当你切换size class时,视图控制器的尺寸会更新来显示新的抽象布局。
最后,你可以重新定位、拉伸视图和添加竖屏上的约束了。这里有一些我添加到竖向布局上的约束:

这是我做到这步时,我的storyboard的样子:

在这个阶段,你可以用任何的iPhone模拟器(3.5、4、4.7或者5.5英寸屏幕)来运行你的项目,看看竖屏情况下的布局是否合理,虽然如果转向成横屏时,布局看上去会一团糟。
注意,我们没有固定图片的宽度,我们只是简单地把图片的左右边缘固定在屏幕两侧。当变为更大的iPhone 6屏幕尺寸时,图片会被拉伸,又因为我们添加了一个固定图片纵横比的约束,所以高度也会同时增加。
为iPhone横向布局添加约束
现在切换size class到 任意宽度和 紧凑高度,这种尺寸特性的组合适用于任何横屏下的iPhone设备,并且会为了满足横屏视图下的目标更新布局。
这次,图片的顶部、左边和底部边缘都被固定在父级视图的边缘。
这个局部另一个有意思的地方是,在评论标签上添加的尾部空间约束。
当图片的约束使得图片变大的时候,这个标签上的约束会使得自身变窄。为了适应这种视图下的文本,文本高度需要增加到两行——的确如此!

下图是我做到这步时storyboard的样子。注意,在文档大纲中,一些约束会稍稍渐隐,这些约束是在竖向视图中我们添加的,它们仍然存在,但是当我们选中当前的宽高特性时,它们不会被应用。

也要注意,当你转换宽高特性时,storyboard会更新以便显示你为那些特性增加的约束。太棒了!

现在运行项目,我们会发现当转向改变时,我们有了一个既适用于横屏又适用于竖屏的布局,更棒的是在转向时,会有一个完美的过渡动画。
我把整个过渡动画放慢,这样你们能看的更加清楚。注意动画中也有层级关系,正由于此,即使在正常布局下视图并没有重叠,我们也需要考虑如何安排视图的层级关系……
编辑助手:设备预览
Xcode另外一个很有用的东西:设备预览助手。你不再需要无数次运行项目来检查你的布局是否正确,你只需要使用编辑助手storyboard预览,选择你想要的所有设备和转向就可以了。
这并不是完美的(比如导航条的颜色在这个例子中缺失了),但是它却是一个很好地选择,它可以让你把你自己的语言切换到双倍长度伪语言,可以在你的storyboard中重复任何文本。

这是我storyboard上的预览助手,它展示了一个3.5英寸横屏和4英寸竖屏的iPhone,你可以看到我还需要再加工加工来适应更长的标签……-_-
为iPad布局添加约束
现在,切换size classes到 正常宽度和 正常高度,这是iPad横屏和竖屏的特性。
就像之前一样,我们重新定位、拉伸我们的视图。对于iPad布局,我决定使用固定尺寸的图片(所以它不会像在iPhone上那样切换横竖屏时会改变大小),元数据都显示在图片底部。
下图是我在重新排列视图并添加了约束之后的storyboard:

到现在为止,我们为某些特别的size class特性添加了约束,但是现在我们要尝试些不同的东西。
由于iPad上会有多余的空间,我们不要仅仅只是重排视图,让我们来加一点额外的内容。对于这个例子来说,我们再加两张图片(也许是在这张主照片之前和之后拍摄的照片)。
这是我的storyboard更新之后的样子:

我原本可以手动输入这些次级图片的宽高,但我没有,取而代之的是我让它们的尺寸变成主图片的某个比例。
这样做的好处是如果我们决定改变主图片的尺寸,布局的其他部分会自动的计算并且更新次级图片的宽高,而不用我们手动输入。

这是一张我截的图,我改变了主图片的宽度约束,可以看到其他的部分也随之更新了。
我没有在iPad模拟器上运行项目并截屏,不过这里有一些横屏和竖屏的效果图:

使用布局和间隔视图
Xcode中有些约束我们可以随时运用,但是对于一些些常见的布局,我们需要一点帮助。
布局视图样例
要把一个视图的边缘固定在父级视图的边缘,或者把它固定在父级视图的正中心是件很简单的事情,~~但是我没有发现简便的方法,让视图固定在离正中心有一段固定距离的地方。~~感谢Jeff Nouwen指出,在把视图固定在中间后,你可以改变constant值来达到你的期望。
理论上来说,我们需要的是一个‘ 中心排列导向’,即任何视图都能水平和垂直居中与父级视图中:

为了实现这个目标,通过现在我们可以使用的约束,我们把我们的视图嵌入一个外层视图(这个外层视图没有背景色,只是为了帮助我们布局而存在),可以把它定位在父级视图的中间。
通过这个方法,你的约束看起来可能像这样:

现在我比较喜欢让我的布局层级尽量平。另外一个不使用外层视图的方法,我叫它 布局视图。
使用这种方法,我倾向于在storyboard中添加一个颜色明亮的视图,然后把它的hidden属性设置为true,你仍然可以在storyboard布局中看到它(虽然稍稍渐隐),但是运行模拟器的时候它不会出现。
现在你在你的视图和布局视图中可以添加 居中排列(align center to center)。

间隔视图样例
之前我们看到了我们是如何固定视图边缘到父级视图边缘的间隙,使得当父级视图变大时,间隙约束也会让视图变大。
但是如果我们想要视图仍然保持原来的大小,在父级视图变大时,视图之间的间隙也变大呢?

理论上来说,我们想要某种类似 同等宽度约束的约束,只不过同等宽度约束是作用在视图上,我们想让它作用在约束上。
此时我们需要添加 间隔视图来帮助我们布局,但由于我们不想在运行app时看到它们,我们会把它们的hidden属性设置为true。
使用这项技术的方法,是为每一个你想要等比增长的间隙添加一个间隔视图,把其他视图的边缘固定在间隔视图的边缘上,然后为所有的间隔视图添加 同等宽度约束。
![]()
下一步
现在希望你们已经完全有信心开始探索应用约束的布局了。
不要指望能即刻成功,Xcode是一个非常复杂的工具,除了storyboard和约束之外它还有很多其他功能,有些功能刚开始使用会觉得很神秘和困惑。就像其他复杂的工具一样,在你熟悉它的怪癖之前你还需要一段适应时间,但是我建议你尽早的去熟悉它,因为我预计(至少我希望)下一代设计师会更多地使用Xcode这样的工具而非Photoshop。
如果你是一位创建设计规范的设计师,并想让IOS开发者遵循你的规范,你应该开始考虑和你的设计团队沟通的最好方法。也许你会创建一个视觉语言来描述你想要应用的约束。
我个人认为,设计师应该更多地承担一些他们创建工作上的责任,而不是让一个前端开发人员重新创建设计意图,而设计师只是管理storyboard文件。
如果你发现这个教程上有任何难以理解的地方,或者有错误的敌方,请让我知道,我会尽快更新这篇文章。
PHP如何获取表单的POST数据呢?本文介绍3种获取POST数据的方法,并将代码附上,希望可以帮助到你。
一、PHP获取POST数据的几种方法
方法1、最常见的方法是:$_POST['fieldname'];
说明:只能接收Content-Type: application/x-www-form-urlencoded提交的数据
解释:也就是表单POST过来的数据
方法2、file_get_contents(“php://input”);
说明:
允许读取 POST 的原始数据。
和 $HTTP_RAW_POST_DATA 比起来,它给内存带来的压力较小,并且不需要任何特殊的 php.ini 设置。
php://input 不能用于 enctype=”multipart/form-data”。
解释:
对于未指定 Content-Type 的POST数据,则可以使用file_get_contents(“php://input”);来获取原始数据。
事实上,用PHP接收POST的任何数据都可以使用本方法。而不用考虑Content-Type,包括二进制文件流也可以。
所以用方法二是最保险的方法。
方法3、$GLOBALS['HTTP_RAW_POST_DATA'];
说明:
总是产生 $HTTP_RAW_POST_DATA 变量包含有原始的 POST 数据。
此变量仅在碰到未识别 MIME 类型的数据时产生。
$HTTP_RAW_POST_DATA 对于 enctype=”multipart/form-data” 表单数据不可用
如果post过来的数据不是PHP能够识别的,可以用 $GLOBALS['HTTP_RAW_POST_DATA']来接收,
比如 text/xml 或者 soap 等等
解释:
$GLOBALS['HTTP_RAW_POST_DATA']存放的是POST过来的原始数据。
$_POST或$_REQUEST存放的是 PHP以key=>value的形式格式化以后的数据。
但$GLOBALS['HTTP_RAW_POST_DATA']中是否保存POST过来的数据取决于centent-Type的设置,即POST数据时 必须显式示指明Content-Type: application/x-www-form-urlencoded,POST的数据才会存放到 $GLOBALS['HTTP_RAW_POST_DATA']中。
二、演示
1、PHP 如何获取POST过来的XML数据和解析XML数据
比如我们在开发微信企业号时,如何处理用户回复过来的数据呢?
文档:http://qydev.weixin.qq.com/wiki/index.php?title=%E6%8E%A5%E6%94%B6%E6%99%AE%E9%80%9A%E6%B6%88%E6%81%AF
首先查阅文档,可知道:启用开发模式后,当用户给应用回复信息时,微信服务端会POST一串XML数据到已验证的回调URL
假设该URL为 http://www.xxx.com
Http请求方式: POST
http://www.xxx.com/?msg_signature=ASDFQWEXZCVAQFASDFASDFSS×tamp=13500001234&nonce=123412323
POST的XML内容为:
<xml> <ToUserName><![CDATA[toUser]]></ToUserName> <FromUserName><![CDATA[fromUser]]></FromUserName> <CreateTime>1348831860</CreateTime> <MsgType><![CDATA[text]]></MsgType> <Content><![CDATA[this is a test]]></Content> <MsgId>1234567890123456</MsgId> <AgentID>1</AgentID> </xml>
那么怎么接收这段内容呃?
这时就可以用到:方法2(file_get_contents(“php://input”))、方法3($GLOBALS['HTTP_RAW_POST_DATA'])
方法2(file_get_contents(“php://input”)):
$input = file_get_contents("php://input"); //接收POST数据
$xml = simplexml_load_string($input); //提取POST数据为simplexml对象
var_dump($xml);
方法3($GLOBALS['HTTP_RAW_POST_DATA'])
$input = $GLOBALS['HTTP_RAW_POST_DATA']; libxml_disable_entity_loader(true); $xml = simplexml_load_string($input, 'SimpleXMLElement', LIBXML_NOCDATA); var_dump($xml);
PHP获取POST数据的3种方法及其代码分析,希望可以帮到你。
错误提示:无法从其“Visible”属性的字符串表示形式“<%= true %>”创建“System.Boolean”类型的对象。
英文:Cannot create an object of type 'System.Boolean' from its string representation '<%= true %>' for the 'Visible' property.
解决办法:改为
<% if(true) { %>
内容
<% } %>
使网页变灰色,只需要一句 css 代码:
html { filter: grayscale(1); }在 I10 / IE11 上的兼容方案需要 grayscale.js,参考此文:http://www.cnblogs.com/wangmeijian/p/4324693.html
CSS 背景图片变灰:https://stackoverflow.com/questions/16340159/greyscale-background-css-images
第一步:生成执行语句
declare @name sysname
declare csr1 cursor
for
select TABLE_NAME from INFORMATION_SCHEMA.TABLES
open csr1
FETCH NEXT FROM csr1 INTO @name
while (@@FETCH_STATUS=0)
BEGIN
SET @name='旧架构名.' + @name
print 'ALTER SCHEMA 新架构名 TRANSFER ' + @name
fetch next from csr1 into @name
END
CLOSE csr1第二步:执行上面命令生成的结果
公司有个项目是使用实体刷卡的会员管理系统,并为其它系统如餐饮系统、美发厅管理系统等提供统一的会员注册与信息管理。暂定使用一维条形码卡。
一般来说,商品最常用的编码是EAN-13,而非商品(如图书馆会员卡,驾驶证条码等)一般使用39码。
39码 在线测试地址:http://xoyozo.net/Tools/Code39
EAN-13 在线测试地址:http://xoyozo.net/Tools/EAN-13
39码
39码比较简单,条码以“*”为起始符和终止符,见下图:

它所能表示的字符包括:0~9 的数字,大写 A~Z 的英文字母,「+」,「-」,「*」,「/」,「%」,「$」,「.」,以及空格符(Space)等,共44组编码。
39码表:“0”对应白色空位,“1”对应黑色线条。
| 字元 | 逻辑型态 | 字元 | 逻辑型态 |
|---|---|---|---|
| A | 110101001011 | N | 101011010011 |
| B | 101101001011 | O | 110101101001 |
| C | 110110100101 | P | 101101101001 |
| D | 101011001011 | Q | 101010110011 |
| E | 110101100101 | R | 110101011001 |
| F | 101101100101 | S | 101101011001 |
| G | 101010011011 | T | 101011011001 |
| H | 110101001101 | U | 110010101011 |
| I | 101101001101 | V | 100110101011 |
| J | 101011001101 | W | 110011010101 |
| K | 110101010011 | X | 100101101011 |
| L | 101101010011 | Y | 110010110101 |
| M | 110110101001 | Z | 100110110101 |
| 字元 | 逻辑型态 | 字元 | 逻辑型态 |
|---|---|---|---|
| 0 | 101001101101 | + | 100101001001 |
| 1 | 110100101011 | - | 100101011011 |
| 2 | 101100101011 | * | 100101101101 |
| 3 | 110110010101 | / | 100100101001 |
| 4 | 101001101011 | % | 101001001001 |
| 5 | 110100110101 | $ | 100100100101 |
| 6 | 101100110101 | . | 110010101101 |
| 7 | 101001011011 | 空白 | 100110101101 |
| 8 | 110100101101 | ||
| 9 | 101100101101 |
值得注意的是,39码生成的条形中,每个码之间有一个空位,经扫描枪测试,该空位与一个单位的线条宽度相等时,能确保被正确扫描。
代码见附件
EAN-13码
EAN-13码是由13位数字构成,其中最后一位为校验码:

| 左侧空白区 | 起始符 | 左侧数据符 | 中间分隔符 | 右侧数据符 | 校验符 | 终止符 | 右测空白区 |
| 9个模块 | 3个模块 | 42个模块 | 5个模块 | 35个模块 | 7个模块 | 3个模块 | 9个模块 |
校验码计算的步骤如下: 以 234235654652 为例:
| 数据码 | 校验码 | ||||||||||||
| 代码位置序号 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 数字码 | 2 | 3 | 4 | 2 | 3 | 5 | 6 | 5 | 4 | 6 | 5 | 2 | ? |
| 偶数位 | 3 | + | 2 | + | 5 | + | 5 | + | 6 | + | 2 | ||
| 奇数位 | 2 | + | 4 | + | 3 | + | 6 | + | 4 | + | 5 | ||
① 从序号2开始,将所有偶数位的数字代码求和,得出S1; S1=3+2+5+5+6+2=23
② 从序号3开始,将所有奇数位的数字求和,得出S2; S2=2+4+3+6+4+5=24
③ S3=S1*3+S2; S3=23*3+24=93
④ C=10-(S3的个位数),得到校验码C的值。并且当S3的个位数为0时,C=0。 C=10-3=7
EAN码的编码规则:
数字符 |
左侧数据符 | 右侧数据符 | |
| A | B | C | |
| 0 | 0001101 | 0100111 | 1110010 |
| 1 | 0011001 | 0110011 | 1100110 |
| 2 | 0010011 | 0011011 | 1101100 |
| 3 | 0111101 | 0100001 | 1000010 |
| 4 | 0100011 | 0011101 | 1011100 |
| 5 | 0110001 | 0111001 | 1001110 |
| 6 | 0101111 | 0000101 | 1010000 |
| 7 | 0111011 | 0010001 | 1000100 |
| 8 | 0110111 | 0001001 | 1001000 |
| 9 | 0001011 | 0010111 | 1110100 |
(关于左侧数据符,网络上的资料均显示A3及B6为6位数,经本人实践亲自查证,已修正)
起始符:101
中间分隔符:01010
终止符:101。
A、B、C中的“0”和“1”分别表示具有一个模块宽度的“空”和“条”。
因为左侧数据编码方式有两种,要按照前置码选其中一种,如表:
| 前置字符 | 左侧数据符编码规则的选择 | |||||
| 0 | A | A | A | A | A | A |
| 1 | A | A | B | A | B | B |
| 2 | A | A | B | B | A | B |
| 3 | A | A | B | B | B | A |
| 4 | A | B | A | A | B | B |
| 5 | A | B | B | A | A | B |
| 6(中国) | A | B | B | B | A | A |
| 7 | A | B | A | B | A | B |
| 8 | A | B | A | B | B | A |
| 9 | A | B | B | A | B | A |