

前日(2010年4月12日),微软正式发布了 Microsoft Visual Studio 2010,相信这是个让众多微软开发者们心情激动的一天吧。至于 VS是啥米东东之类的就不再解释了,相关人员请移步维基百科。
微软称 Visual Studio 2010 集成开发环境(IDE)的界面被重新设计和组织,变得更加清晰和简单。新的 IDE 更好的支持了多文档窗口以及浮动工具窗,并且对于多显示器的支持也有所增强。IDE的外壳使用 WPF 重写,内部使用 MEF 重新设计,以提供比先前版本更好的扩展性。
VS2010 的版本较之前版本有所不同,取消了标准版、团队版命名方式等,而采用跟 Window 7 一致的:
| 产品功能 | Professional (专业版) | Premium (高级版) | Ultimate (旗舰版) |
| 测试和诊断 | ≈ | ≈ | √ |
| 测试工具 | ≈ | ≈ | √ |
| 集成开发环境 | √ | √ | √ |
| 数据库开发 | ≈ | √ | √ |
| 开发平台支持 | √ | √ | √ |
| 体系结构和建模 | × | ≈ | √ |
| Lab Management | × | × | √ |
| Team Foundation Server | ≈ | ≈ | √ |
| MSDN 订阅 | ≈ | ≈ | √ |
| 价格 | $1,199 | $5,469 | $11,899 |
(注:√ 支持 × 不支持 ≈ 部分支持)
“只选贵的”符合天朝国情。许多大侠认为官方下载的肯定是未破解的,那是您的错,其实微软也是一只河蟹,记住一个公式:Trial(测试版)+ Key(序列号)= 正式版
分卷下载:(下载后双击part1.exe解压为 VS2010UltimTrial.iso)
VS2010UltimTrialCHS_4PartsTotal.part1.exe 官网下载 迅雷下载
VS2010UltimTrialCHS_4PartsTotal.part2.rar 官网下载 迅雷下载
VS2010UltimTrialCHS_4PartsTotal.part3.rar 官网下载 迅雷下载
VS2010UltimTrialCHS_4PartsTotal.part4.rar 官网下载 迅雷下载
完整镜像下载: X16-60997VS2010UltimTrialCHS.iso 官网下载 迅雷下载
CRC: 0x3DB619A0
SHA-1: 0x8BA7308E1F74AEE8DE6094CE04F78CD21486608D
分卷下载:(下载后双击part1.exe解压为 VS2010UltimTrial.iso)
VS2010UltimTrial_4PartsTotal.part1.exe 官网下载 迅雷下载
VS2010UltimTrial_4PartsTotal.part2.rar 官网下载 迅雷下载
VS2010UltimTrial_4PartsTotal.part3.rar 官网下载 迅雷下载
VS2010UltimTrial_4PartsTotal.part4.rar 官网下载 迅雷下载
完整镜像下载: X16-42552VS2010UltimTrial1.iso 官网下载 迅雷下载
CRC: 0x8095c67f
SHA-1: 0x8371f6a8d090063fcc320617e94854374633df3c
钥匙:YCFHQ-9DWCY-DKV88-T2TMH-G7BHP(需刮开才能看到,显示器刮坏请找经销商)

一个关于Visual Studio 2008 SP1 (KB971092) 的系统补丁重复安装问题的解决方案:
出现该问题的原因是未安装 Visual C++,除了安装VC++,您可以按以下步骤解决该补丁更新问题。
1.)下载补丁包或直接从 \Windows\SoftwareDistribution\Download\Install 目录找。
2.)双击安装,记住释放文件的目录。出现提示“VC Libraries QFE Patch 不适用或被系统的其他条件阻止。有关详细信息,请单击以下链接。”时,不要关闭窗口。
3.)找到释放安装文件的临时文件夹,复制到桌面。
4.)现在可以关闭刚才的提示窗口了。
5.)找到“\Program Files\Microsoft Visual Studio 9.0\Common7\Tools\vsvars32.bat”这个文件,添加 Everyone 的权限为可写。
6.)运行桌面文件夹内的 VS90SP1-KB971092-x86.msp 等待安装完成,完成时没有提示。
7.)更新成功!
Earlier this summer I started writing a multi-part blog series that discusses the built-in LINQ to SQL provider in .NET 3.5. LINQ to SQL is an ORM (object relational mapping) implementation that allows you to model a relational database using .NET classes. You can then query the database using LINQ, as well as update/insert/delete data from it. LINQ to SQL fully supports transactions, views, and stored procedures. It also provides an easy way to integrate data validation and business logic rules into your data model.
You can learn more about LINQ to SQL by reading my posts below (more will be coming soon):
- Part 1: Introduction to LINQ to SQL
- Part 2: Defining our Data Model Classes
- Part 3: Querying our Database
- Part 4: Updating our Database
- Part 5: Binding UI using the ASP:LinqDataSource Control
Using the LINQ to SQL Debug Visualizer
One of the nice development features that LINQ to SQL supports is the ability to use a "debug visualizer" to hover over a LINQ expression while in the VS 2008 debugger and inspect the raw SQL that the ORM will ultimately execute at runtime when evaluating the LINQ query expression.
For example, assume we write the below LINQ query expression code against a set of data model classes:
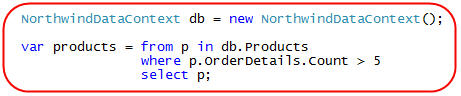
We could then use the VS 2008 debugger to hover over the "products" variable after the query expression has been assigned:

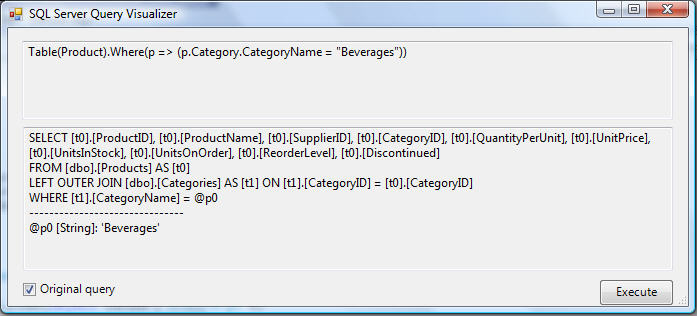
And if we click the small magnifying glass in the expression above, we can launch the LINQ to SQL debug visualizer to inspect the raw SQL that the ORM will execute based on that LINQ query:
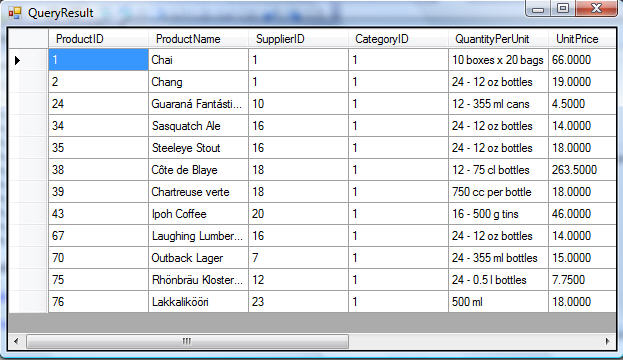
If you click the "Execute" button, you can even test out the SQL query and see the raw returned results that will be returned from the database:
This obviously makes it super easy to see precisely what SQL query logic LINQ to SQL ORM is doing for you.
You can learn even more about how all this works by reading the Part 3: Querying our Database segment in my LINQ to SQL series above.
How to Install the LINQ to SQL Debug Visualizer
The LINQ to SQL Debug Visualizer isn't built-in to VS 2008 - instead it is an add-in that you need to download to use. You can download a copy of it here.
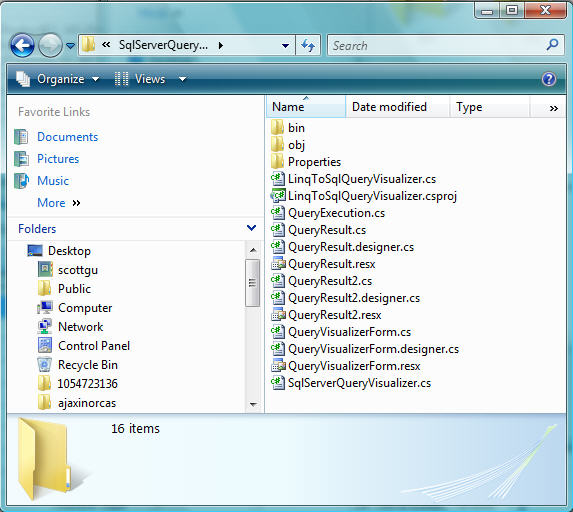
The download contains both a binary .dll assembly version of the visualizer (within the \bin\debug directory below), as well as all of the source code for the visualizer:
To install the LINQ to SQL debug visualizer, follow the below steps:
1) Shutdown all running versions of Visual Studio 2008
2) Copy the SqlServerQueryVisualizer.dll assembly from the \bin\debug\ directory in the .zip download above into your local \Program Files\Microsoft Visual Studio 9.0\Common7\Packages\Debugger\Visualizers\ directory:
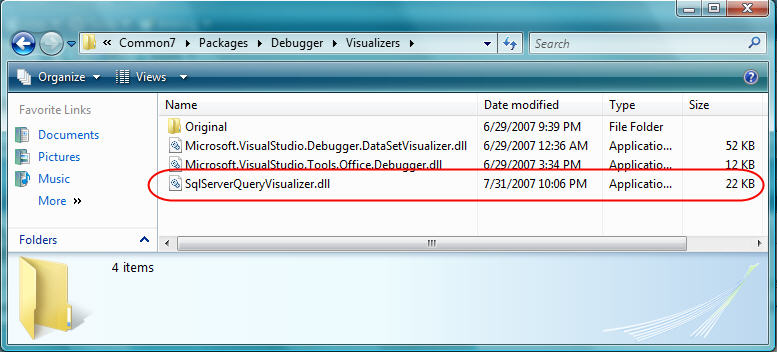
3) Start up Visual Studio 2008 again. Now when you use the debugger with LINQ to SQL you should be able to hover over LINQ query expressions and inspect their raw SQL (no extra registration is required).
Hope this helps,
Scott
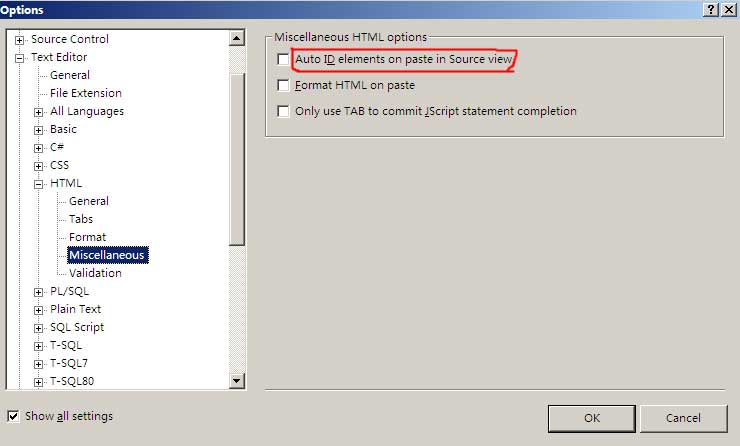
在我们开发过程中,经常会复制一些代码,而Visual Studio会自动把这些代码的ID重新生成,常常导致我们还必须去修改回原ID
其实,Visual Studio是可以保留原始ID的。我们可以通过在Tools->Options->Text Editor->HTML->Miscellaneous中,把Auto ID elements on paste in Source View前面的勾去掉就可以。
如图所示
下载地址 ftp://xuexi:xuexi123456@218.246.23.98/VS2005.rar
新增地址 ftp://thc123_net:thc123_com@220.113.41.144/thcvs2005.rar
附上天轰穿主页:
下载最新的免费CodeHighlighter组件 http://www.CodeHighlighter.com
1。确保web.config中的languages节点的.xml文件路径正确。
2。可以在insertCode.aspx更改编辑的默认设置,如checkbox的check等。(或在项目中搜索相关代码)
DotNetTextBox 已集成CodeHighlighter,我的修改如下:
自从有了IP数据库这种东西,QQ外挂的显示IP功能也随之而生,本人见识颇窄,是否还有其他应用不得而知,不过,IP数据库确实是个不错的东西。如今网络上最流行的IP数据库我想应该是纯真版的(说错了也不要扁我),迄今为止其IP记录条数已经接近30000,对于有些IP甚至能精确到楼层,不亦快哉。2004年4、5月间,正逢LumaQQ破土动工,为了加上这个人人都喜欢,但是好像人人都不知道为什么喜欢的显IP功能,我也采用了纯真版IP数据库,它的优点是记录多,查询速度快,它只用一个文件QQWry.dat就包含了所有记录,方便嵌入到其他程序中,也方便升级。
基本结构
QQWry.dat文件在结构上分为3块:文件头,记录区,索引区。一般我们要查找IP时,先在索引区查找记录偏移,然后再到记录区读出信息。由于记录区的记录是不定长的,所以直接在记录区中搜索是不可能的。由于记录数比较多,如果我们遍历索引区也会是有点慢的,一般来说,我们可以用二分查找法搜索索引区,其速度比遍历索引区快若干数量级。图1是QQWry.dat的文件结构图。

图1. QQWry.dat文件结构
要注意的是,QQWry.dat里面全部采用了little-endian字节序
一. 了解文件头
QQWry.dat的文件头只有8个字节,其结构非常简单,首四个字节是第一条索引的绝对偏移,后四个字节是最后一条索引的绝对偏移。
二. 了解记录区
每条IP记录都由国家和地区名组成,国家地区在这里并不是太确切,因为可能会查出来“清华大学计算机系”之类的,这里清华大学就成了国家名了,所以这个国家地区名和IP数据库制作的时候有关系。所以记录的格式有点像QName,有一个全局部分和局部部分组成,我们这里还是沿用国家名和地区名的说法。
于是我们想象着一条记录的格式应该是: [IP地址][国家名][地区名],当然,这个没有什么问题,但是这只是最简单的情况。很显然,国家名和地区名可能会有很多的重复,如果每条记录都保存一个完整的名称拷贝是非常不理想的,所以我们就需要重定向以节省空间。所以为了得到一个国家名或者地区名,我们就有了两个可能:第一就是直接的字符串表示的国家名,第二就是一个4字节的结构,第一个字节表明了重定向的模式,后面3个字节是国家名或者地区名的实际偏移位置。对于国家名来说,情况还可能更复杂些,因为这样的重定向最多可能有两次。
那么什么是重定向模式?根据上面所说,一条记录的格式是[IP地址][国家记录][地区记录],如果国家记录是重定向的话,那么地区记录是有可能没有的,于是就有了两种情况,我管他叫做模式1和模式2。我们对这些格式的情况举图说明:

图2. IP记录的最简单形式
图2表示了最简单的IP记录格式,我想没有什么可以解释的

图3. 重定向模式1
图3演示了重定向模式1的情况。我们看到在模式1的情况下,地区记录也跟着国家记录走了,在IP地址之后只剩下了国家记录的4字节,后面3个字节构成了一个指针,指向了实际的国家名,然后又跟着地址名。模式1的标识字节是0x01。

图4. 重定向模式2
图4演示了重定向模式2的情况。我们看到了在模式2的情况下(其标识字节是0x02),地区记录没有跟着国家记录走,因此在国家记录之后4个字节之后还是有地区记录。我想你已经明白了模式1和模式2的区别,即:模式1的国家记录后面不会再有地区记录,模式2的国家记录后会有地区记录。下面我们来看一下更复杂的情况。

图5. 混和情况1
图5演示了当国家记录为模式1的时候可能出现的更复杂情况,在这种情况下,重定向指向的位置仍然是个重定向,不过第二次重定向为模式2。大家不用担心,没有模式3了,这个重定向也最多只有两次,并且如果发生了第二次重定向,则其一定为模式2,而且这种情况只会发生在国家记录上,对于地区记录,模式1和模式2是一样的,地区记录也不会发生2次重定向。不过,这个图还可以更复杂,如图7:

图6. 混和情况2
图6是模式1下最复杂的混和情况,不过我想应该也很好理解,只不过地区记录也来重定向而已,有一点我要提醒你,如果重定向的地址是0,则表示未知的地区名。
所以我们总结如下:一条IP记录由[IP地址][国家记录][地区记录]组成,对于国家记录,可以有三种表示方式:字符串形式,重定向模式1和重定向模式2。对于地区记录,可以有两种表示方式:字符串形式和重定向,另外有一条规则:重定向模式1的国家记录后不能跟地区记录。按照这个总结,在这些方式中合理组合,就构成了IP记录的所有可能情况。
设计的理由
在我们继续去了解索引区的结构之前,我们先来了解一下为何记录区的结构要如此设计。我想你可能想到了答案:字符串重用。没错,在这种结构下,对于一个国家名和地区名,我只需要保存其一次就可以了。我们举例说明,为了表示方便,我们用小写字母代表IP记录,C表示国家名,A表示地区名:
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2, A1 = A2,那么我们就可以使用图3显示的结构来实现重用
有三条记录a(C1, A1), b(C2, A2), c(C3, A3),如果C1 = C2, A2 = A3,现在我们想存储记录b,那么我们可以用图6的结构来实现重用
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2,现在我们想存储记录b,那么我们可以采用模式2表示C2,用字符串表示A2
你可以举出更多的情况,你也会发现在这种结构下,不同的字符串只需要存储一次。
了解索引区
在"了解文件头"部分,我们说明了文件头实际上是两个指针,分别指向了第一条索引和最后一条索引的绝对偏移。如图8所示:

图8. 文件头指向索引区图示
实在是很简单,不是吗?从文件头你就可以定位到索引区,然后你就可以开始搜索IP了!每条索引长度为7个字节,前4个字节是起始IP地址,后三个字节就指向了IP记录。这里有些概念需要说明一下,什么是起始IP,那么有没有结束IP?假设有这么一条记录:166.111.0.0 - 166.111.255.255,那么166.111.0.0就是起始IP,166.111.255.255就是结束IP,结束IP就是IP记录中的那头4个字节,这下你应该就清楚了吧。于是乎,每条索引配合一条记录,构成了一个IP范围,如果你要查找166.111.138.138所在的位置,你就会发现166.111.138.138落在了166.111.0.0- 166.111.255.255 这个范围内,那么你就可以顺着这条索引去读取国家和地区名了。那么我们给出一个最详细的图解吧:

图9. 文件详细结构
现在一切都清楚了是不是?也许还有一点你不清楚,QQWry.dat的版本信息存在哪里呢? 答案是:最后一条IP记录实际上就是版本信息,最后一条记录显示出来就是这样:255.255.255.0255.255.255.255 纯真网络 2004年6月25日IP数据。OK,到现在你应该全部清楚了。
Demo
下一步:我给出一个读取IP记录的程序片断,此片断摘录自LumaQQ源文件edu.tsinghua.lumaqq.IPSeeker.java,如果你有兴趣,可以下载源代码详细看看。
/** *//**
* 给定一个ip国家地区记录的偏移,返回一个IPLocation结构
* @param offset 国家记录的起始偏移
* @return IPLocation对象
*/
private IPLocation getIPLocation(long offset) {
try {
// 跳过4字节ip
ipFile.seek(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = ipFile.readByte();
if(b == REDIRECT_MODE_1) {
// 读取国家偏移
long countryOffset = readLong3();
// 跳转至偏移处
ipFile.seek(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = ipFile.readByte();
if(b == REDIRECT_MODE_2) {
loc.country = readString(readLong3());
ipFile.seek(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(ipFile.getFilePointer());
} else if(b == REDIRECT_MODE_2) {
loc.country = readString(readLong3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(ipFile.getFilePointer() - 1);
loc.area = readArea(ipFile.getFilePointer());
}
return loc;
} catch (IOException e) {
return null;
}
}
/** *//**
* 从offset偏移开始解析后面的字节,读出一个地区名
* @param offset 地区记录的起始偏移
* @return 地区名字符串
* @throws IOException 地区名字符串
*/
private String readArea(long offset) throws IOException {
ipFile.seek(offset);
byte b = ipFile.readByte();
if(b == REDIRECT_MODE_1 || b == REDIRECT_MODE_2) {
long areaOffset = readLong3(offset + 1);
if(areaOffset == 0)
return LumaQQ.getString("unknown.area");
else
return readString(areaOffset);
} else
return readString(offset);
}
/** *//**
* 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法
* 用了这么一个函数来做转换
* @param offset 整数的起始偏移
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/** *//**
* 从当前位置读取3个字节转换成long
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3() {
long ret = 0;
try {
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/** *//**
* 从offset偏移处读取一个以0结束的字符串
* @param offset 字符串起始偏移
* @return 读取的字符串,出错返回空字符串
*/
private String readString(long offset) {
try {
ipFile.seek(offset);
int i;
for(i = 0, buf[i] = ipFile.readByte(); buf[i] != 0; buf[++i] = ipFile.readByte());
if(i != 0)
return Utils.getString(buf, 0, i, "GBK");
} catch (IOException e) {
log.error(e.getMessage());
}
return "";
}代码并不复杂,getIPLocation是主要方法,它检查国家记录格式,并针对字符串形式,模式1,模式2采用不同的代码,readArea则相对简单,因为只有字符串和重定向两种情况需要处理。
总结
纯真IP数据库的结构使得查找IP简单迅速,不过你想要编辑它却是比较麻烦的,我想应该需要专门的工具来生成QQWry.dat文件,由于其文件格式的限制,你要直接添加IP记录就不容易了。不过,能查到IP已经很开心了,希望纯真记录越来越多~。
LumaQQ is a Java QQ client which has a reusablepure Java core and SWT-based GUI
微软下载中心:Microsoft Visual Studio International Pack
Visual Studio International Pack 包含一组类库,该类库扩展了.NET Framework对全球化软件开发的支持。使用该类库提供的类,.NET 开发人员可以更方便的创建支持多文化多语言的软件应用。
概述
- East Asia Numeric Formatting Library - 支持将小写的数字字符串格式化成简体中文,繁体中文,日文和韩文的大写数字字符串。
- Japanese Kana Conversion Library - 支持将日文假名(Kana)转化为另一种日文字符。
- Japanese Text Alignment Library - 支持日文特有的一种对齐格式。
- Japanese Yomi Auto-Completion Library - 类库支持感知日文输入法的输入自动完成和一个文本框控制的示例。
- Korean Auto Complete TextBox Control - 在文本框中支持韩文输入法的智能感知和输入自动完成。
- Simplified Chinese Pin-Yin Conversion Library - 支持获取简体中文字符的常用属性比如拼音,多音字,同音字,笔画数。
- Traditional Chinese to Simplified Chinese Conversion Library and Add-In Tool - 支持简繁体中文之间的转换. 该组件还包含一个Visual Studio集成开发环境中的插件(Add-in)支持简繁体中文资源文件之间的转换。
说明
2. 运行所需组件的MSI文件安装该组件。
文件安装在X:\Program Files\Microsoft Visual Studio International Pack(Beta)\Simplified Chinese Pin-Yin Conversion Library下。
使用时,需要引用目录下的两个dll文件:ChnCharInfo.dll,ChnCharInfoResource.dll。
其中ChnCharInfo.dll包含应用的类Microsoft.International.Converters.PinYinConverter > ChineseChar
ChnCharInfoResource.dll只包含数据资源。
ChineseCharNew(Char) ChineseChar类的构造函数。
ChineseCharacter 获取这个汉字字符。
CompareStrokeNumber(Char) 将给出的字符和实例字符的笔画数进行比较。
GetCharCount(Int16) 检索具有指定笔画数的字符个数。
GetChars(String) 获取给定拼音的所有同音字。
GetChars(Int16) 检索具有指定笔画数的所有字符串。
GetHomophoneCount(String) 检索具有指定拼音的字符数。
GetStrokeNumber(Char) 检索指定字符的笔画数。
HasSound(String) 识别字符是否有指定的读音。
IsHomophone(Char) 识别给出的字符是否是实例字符的同音字。
IsHomophone(Char, Char) 识别给出的两个字符是否是同音字。
IsPolyphone 获取这个字符是否是多音字。
IsValidChar(Char) 识别给出的字符串是否是一个有效的汉字字符。
IsValidPinyin(String) 识别给出的拼音是否是一个有效的拼音字符串。
IsValidStrokeNumber(Int16) 识别给出的笔画数是否是一个有效的笔画数。
PinyinCount 获取这个字符的拼音个数。
Pinyins 获取这个字符的拼音。
StrokeNumber 获取这个字符的笔画数。
以下代码演示了返回给出字符的笔划数。
using Microsoft.International.Converters.PinYinConverter;
class Main
{
publicvoid Main()
{
object chineseChar = new ChineseChar("微");
Console.WriteLine("stroke number of 微 in Chinese is {0}.", chineseChar.StrokeNumber);
Console.WriteLine("{0} characters' pinyin is \\'wei1\\'.", chineseChar.GetHomophoneCount("wei1"));
if ((chineseChar.IsHomophone("微", "薇")))
{
Console.WriteLine("微 and 薇 have the same pinyin.");
}
}
}
// This code produces the following output.
// stroke number of 微 in Chinese is 13.
// 37 characters' pinyin is 'wei1'.
// 微 and 薇 have the same pinyin.
//
它也没有提供注音功能。象“乪”字,它提供了拼音:NANG2,可没提供注音:náng。这我觉得很奇怪了。
namespace LzmTW.Converters.PinYinConverter
{
partial class ChineseChar
{
private class Vowels
{
private static ReadOnlyCollection<string> gArray;
static Vowels()
{
string[] mArray = new string[] {"b", "p", "m", "f", "d", "t", "n", "l", "g", "k",
"h", "j", "q", "x", "zh", "ch", "sh", "r", "z", "c",
"s", "y", "w"};
gArray =new ReadOnlyCollection<string>(mArray);
}
public static string Item {
get{
if (pinyin.Length ==1) {
return string.Empty;
}
string mVowel = pinyin.Substring(0, 2).ToLower;
if (gArray.Contains(mVowel))
return mVowel;
mVowel = mVowel.Substring(0, 1);
if (gArray.Contains(mVowel))
return mVowel;
return string.Empty;
}
}
}
}
}
namespace LzmTW.Converters.PinYinConverter
{
partial class ChineseChar
{
private class Consonants
{
private static ConsonantCollection gArray;
public static string Item {
get{
string mLastChar = yunmu.Substring(yunmu.Length -1, 1);
int mTone =-1;
string mConsonant = yunmu;
if (char.IsNumber((char)mLastChar)) {
mTone =int.Parse(mLastChar);
}
if (mTone >0) {
mConsonant = yunmu.Substring(0, yunmu.Length -1);
}
if (gArray.Contains(mConsonant)) {
switch (mTone) {
case0:
return gArray(mConsonant).tone1;
case1:
return gArray(mConsonant).tone2;
case2:
return gArray(mConsonant).tone3;
case3:
return gArray(mConsonant).tone4;
case4:
return gArray(mConsonant).tone5;
default:
return gArray(mConsonant).tone1;
}
}
return string.Empty;
}
}
static Consonants()
{
gArray =new ConsonantCollection();
//i,u,ü,iu
gArray.Add(ConsonantItem.Create(new string[] {"i", "i", "ī", "í", "ǐ", "ì"}));
gArray.Add(ConsonantItem.Create(new string[] {"u", "u", "ū", "ú", "ǔ", "ù"}));
gArray.Add(ConsonantItem.Create(new string[] {"v", "ü", "ǖ", "ǘ", "ǚ", "ǜ"}));
gArray.Add(ConsonantItem.Create(new string[] {"iu", "iu", "iū", "iú", "iǔ", "iù"}));
//ɑ,iɑ,uɑ
gArray.Add(ConsonantItem.Create(new string[] {"a", "a", "ā", "á", "ǎ", "à"}));
gArray.Add(ConsonantItem.Create(new string[] {"ia", "ia", "iā", "iá", "iǎ", "ià"}));
gArray.Add(ConsonantItem.Create(new string[] {"ua", "ua", "uā", "uá", "uǎ", "uà"}));
//o,uo
gArray.Add(ConsonantItem.Create(new string[] {"o", "o", "ō", "ó", "ǒ", "ò"}));
gArray.Add(ConsonantItem.Create(new string[] {"uo", "uo", "uō", "uó", "uǒ", "uò"}));
//e,ie,eü,er,ue,üe
gArray.Add(ConsonantItem.Create(new string[] {"e", "e", "ē", "é", "ě", "è"}));
gArray.Add(ConsonantItem.Create(new string[] {"ie", "ie", "iē", "ié", "iě", "iè"}));
gArray.Add(ConsonantItem.Create(new string[] {"er", "er", "ēr", "ér", "ěr", "èr"}));
gArray.Add(ConsonantItem.Create(new string[] {"ve", "üe", "ǖe", "ǘe", "ǚe", "ǜe"}));
gArray.Add(ConsonantItem.Create(new string[] {"ue", "üe", "ǖe", "ǘe", "ǚe", "ǜe"}));
//ɑi,uɑi
gArray.Add(ConsonantItem.Create(new string[] {"ai", "ai", "āi", "ái", "ǎi", "ài"}));
gArray.Add(ConsonantItem.Create(new string[] {"uai", "uai", "uāi", "uái", "uǎi", "uài"}));
//ei,uei(ui)
gArray.Add(ConsonantItem.Create(new string[] {"ei", "ei", "ēi", "éi", "ěi", "èi"}));
gArray.Add(ConsonantItem.Create(new string[] {"ui", "ui", "uī", "uí", "uǐ", "uì"}));
//ɑo,iɑo
gArray.Add(ConsonantItem.Create(new string[] {"ao", "ao", "āo", "áo", "ǎo", "ào"}));
gArray.Add(ConsonantItem.Create(new string[] {"iao", "iao", "iāo", "iáo", "iǎo", "iào"}));
//ou,iou
gArray.Add(ConsonantItem.Create(new string[] {"ou", "ou", "ōu", "óu", "ǒu", "òu"}));
//ɑn,iɑn
gArray.Add(ConsonantItem.Create(new string[] {"an", "an", "ān", "án", "ǎn", "àn"}));
gArray.Add(ConsonantItem.Create(new string[] {"ian", "ian", "iān", "ián", "iǎn", "iàn"}));
//uɑn,üɑn
gArray.Add(ConsonantItem.Create(new string[] {"uan", "uan", "uān", "uán", "uǎn", "uàn"}));
//en, uen(un)
gArray.Add(ConsonantItem.Create(new string[] {"en", "en", "ēn", "én", "ěn", "èn"}));
gArray.Add(ConsonantItem.Create(new string[] {"un", "un", "ūn", "ún", "ǔn", "ùn"}));
//in,ün
gArray.Add(ConsonantItem.Create(new string[] {"in", "in", "īn", "ín", "ǐn", "ìn"}));
gArray.Add(ConsonantItem.Create(new string[] {"vn", "ün", "ǖn", "ǘn", "ǚn", "ǜn"}));
//ɑnɡ,iɑnɡ,uɑnɡ
gArray.Add(ConsonantItem.Create(new string[] {"ang", "ang", "āng", "áng", "ǎng", "àng"}));
gArray.Add(ConsonantItem.Create(new string[] {"iang", "iang", "iāng", "iáng", "iǎng", "iàng"}));
gArray.Add(ConsonantItem.Create(new string[] {"uang", "uang", "uāng", "uáng", "uǎng", "uàng"}));
//enɡ,uenɡ
gArray.Add(ConsonantItem.Create(new string[] {"eng", "eng", "ēng", "éng", "ěng", "èng"}));
//inɡ
gArray.Add(ConsonantItem.Create(new string[] {"ing", "ing", "īng", "íng", "ǐng", "ìng"}));
//onɡ,ionɡ
gArray.Add(ConsonantItem.Create(new string[] {"ong", "ong", "ōng", "óng", "ǒng", "òng"}));
gArray.Add(ConsonantItem.Create(new string[] {"iong", "iong", "iōng", "ióng", "iǒng", "iòng"}));
}
private class ConsonantItem
{
public string tone0;
public string tone1;
public string tone2;
public string tone3;
public string tone4;
public string tone5;
public static ConsonantItem Create(string[] array)
{
ConsonantItem tmp =new ConsonantItem();
{
tmp.tone0 = array(0);
tmp.tone1 = array(1);
tmp.tone2 = array(2);
tmp.tone3 = array(3);
tmp.tone4 = array(4);
tmp.tone5 = array(5);
}
return tmp;
}
}
private class ConsonantCollection : KeyedCollection<string, ConsonantItem>
{
protected override string GetKeyForItem(ConsonantItem item)
{
return item.tone0;
}
}
}
}
}PinyinConverter.cs
namespace LzmTW.Converters.PinYinConverter
{
public class ChineseChar : Microsoft.International.Converters.PinYinConverter.ChineseChar
{
private Collections.ObjectModel.ReadOnlyCollection<string> gZhuyins;
public ChineseChar(char ch) : base(ch)
{
string[] mZhuyinList =new string[8];
string mPinyin;
for (int i =0; i <= mZhuyinList.Length -1; i++) {
mPinyin =this.Pinyins(i);
if (!string.IsNullOrEmpty(mPinyin)) {
mZhuyinList(i) = ChineseChar.Zhuyin(mPinyin);
}
}
gZhuyins =new Collections.ObjectModel.ReadOnlyCollection<string>(mZhuyinList);
}
public Collections.ObjectModel.ReadOnlyCollection<string> Zhuyins {
get { return gZhuyins; }
}
private static string Zhuyin {
get {
pinyin = pinyin.Trim.ToLower;
string mVowel = Vowels.Item(pinyin);
string mYummu = pinyin;
if (!mVowel.Equals(string.Empty)) {
mYummu = mYummu.Substring(mVowel.Length);
}
string mConsonant = Consonants.Item(mYummu);
return string.Concat(mVowel, mConsonant);
}
}
/**////' <param name="pinyins">如 XIAN1 JIN4</param>
//Private Shared Function GetZhuyins(ByVal pinyins As String) As String
// Dim mList As New List(Of String)
// Dim mPinyin As String
// For Each pinyin As String In pinyins.Split(" "c)
// mPinyin = ChineseChar.Zhuyin(pinyin)
// If mPinyin.Equals(String.Empty) Then Continue For
// mList.Add(mPinyin)
// Next
// Return String.Join(" ", mList.ToArray)
//End Function
}
}private void Button5_Click(object sender, System.EventArgs e)
{
LzmTW.Converters.PinYinConverter.ChineseChar t =new LzmTW.Converters.PinYinConverter.ChineseChar('和');
Console.WriteLine("\"和\"为多音字:");
for (int i =0; i <= t.PinyinCount -1; i++) {
Console.WriteLine("拼音:{0,-5},注音:{1}", t.Pinyins(i), t.Zhuyins(i));
}
}"和"为多音字:
拼音:HE2 ,注音:hé
拼音:HE4 ,注音:hè
拼音:HE5 ,注音:he
拼音:HU2 ,注音:hú
拼音:HUO2 ,注音:huó
拼音:HUO4 ,注音:huò
拼音:HUO5 ,注音:huo