

1、在“视图”选项卡上展开“视觉帮助”
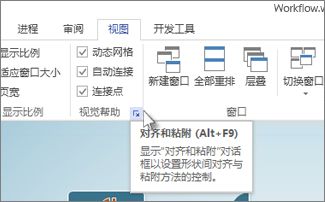
2、在“对齐和粘附”对话框中的“常规”选项卡上,在“当前活动”下,清除“粘附”复选框。
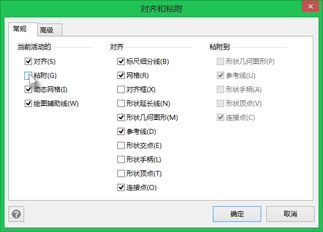
3、操作方式
直接拖动连接线的端点仍然是自动粘附至形状的,按住 Alt 再拖动则会在任意位置停留。
此设置的缺点是:无法在鼠标自动依靠形状时自动提示连接线,需要复制已有连接线来达到新建的目的。

打开“任务计划程序”(taskschd.msc)

点击右侧“创建任务”

填写“名称”

“安全选项”根据实际情况设置
如果选择“不管用户是否登录都要运行”,则启动成功后不会显示窗口(包括由该应用调起的其它应用,任务管理器中可见进程)
如果选择“只在用户登录时运行”启动成功后会显示窗口,但系统重启后需要进入系统才能运行此计划
“触发器”新建,勾选“重复任务间隔”选最短,“持续时间”无限期,并取消“任务的执行时间超过此值则停止执行”

“操作”新建,启动程序,浏览程序或脚本

“设置”请勿启动新实例(只判断它启动的实例,不判断手动打开的或开机启动的实例),其它选项按需设置

设置完成








设置完成后查看“上次运行结果”。
尚未运行,显示:(0xC000013A)
第一次运行,显示:正在运行任务。(0x41301)
从第二次起,显示:操作员或系统管理员拒绝了请求。(0x800710E0)
前几天实现了在 nginx 中使用 lua 实现远程鉴权,今天想试试在 IIS 中能不能实现相同的功能。查询资料发现需要使用 URL 重写和 HTTP 请求模块,没有深究。干脆使用 ASP.NET 中间件来实现吧。
在 StratUp.cs 的 Configure 方法中,或 Program.cs 文件中添加以下代码:
// 远程鉴权
app.Use(async (context, next) =>
{
var ip = context.Connection.RemoteIpAddress!.ToString();
var ua = context.Request.Headers.UserAgent.ToString();
var host = context.Request.Host.Host;
var uri = new Uri(context.Request.GetDisplayUrl()).PathAndQuery;
var client = new HttpClient();
client.Timeout = TimeSpan.FromSeconds(1); // 设置超时时间
try
{
var requestUrl = "https://鉴权地址/";
var requestMessage = new HttpRequestMessage(HttpMethod.Get, requestUrl);
requestMessage.Headers.Add("X-Real-IP", ip);
requestMessage.Headers.Add("User-Agent", ua);
requestMessage.Headers.Add("X-Forwarded-Host", host);
requestMessage.Headers.Add("X-Forwarded-Uri", uri);
// 发送请求
var response = await client.SendAsync(requestMessage);
// 检查响应状态码
if (response.StatusCode == HttpStatusCode.Forbidden)
{
// 如果返回403,则拒绝访问
context.Response.StatusCode = (int)HttpStatusCode.Forbidden;
await context.Response.WriteAsync("Access Denied");
}
else
{
// 如果返回其他状态码,则继续执行管道中的下一个中间件
await next();
}
}
catch (TaskCanceledException ex) when (ex.CancellationToken.IsCancellationRequested)
{
// 如果请求超时(任务被取消),则继续执行管道中的下一个中间件
await next();
}
catch
{
// 如果遇到错误,则继续执行管道中的下一个中间件
await next();
}
});代码很简单,使用 HttpClient 发送请求,若返回 403 则拒绝访问,其它情况继续执行业务逻辑,超时或报错的情况按需修改即可。
若鉴权接口在私网中,建议将鉴权接口域名和私网 IP 添加到 hosts 文件中。
本文记录于 2024 年 11 月。
| 升级前 | 期望(最新正式版) | 最终选择 | |
| 操作系统 | Alibaba Cloud Linux 3 | Alibaba Cloud Linux 3 | Alibaba Cloud Linux 3 |
| 管理面板 | 宝塔面板 Linux 版 9.2.0 | 宝塔面板 Linux 版 9.2.0 | 宝塔面板 Linux 版 9.2.0 |
| Web 服务 | nginx 1.24 | nginx 1.24 | nginx 1.24 |
| 脚本语言 | PHP 7.4 | PHP 8.2 | PHP 8.2 |
| 数据库 | PolarDB MySQL 5.6 | RDS MySQL 9.1 | PolarDB MySQL 8.0 |
| 论坛程序 | Discuz! X3.4 GBK | Discuz! X5.0 | Discuz! X3.5 UTF8 |
版本选择原因:
Discuz! X5 刚刚发布,生态尚未成熟,考虑到是老论坛升级,所以选择 X3.5。
Discuz! X3.5 目前最高支持 PHP 8.2、MySQL 8.0。
完整升级步骤:
购买新的 ECS、PolarDB,具体环境配置步骤参此文;
安装宝塔面板并配置;
安装 nginx 及 PHP;
创建网站、配置 SSL、伪静态、防盗链、可写目录禁执行、仅允许部分入口文件执行等(.conf);
配置 hosts;
如果是正式升级阶段,关闭论坛,防止产生新数据。
备份原网站程序、PolarDB 数据库;
PolarDB 创建快照。
测试阶段:从快照还原到新实例(MySQL 5.6 不能直接恢复到 MySQL 8.0),然后从 5.6 迁移到 8.0.x;
正式阶段:全量模式直接从原实例迁移到 8.0.x,若增量模式且存在触发器,建议从快照还原;
上传原网站程序到新的站点目录下;
按 Discuz! X 升级文档升级 X3.4 至 X3.5;详情见下文 ↓;
升级完成后切换到 PHP 8;
配置 OSS、Redis、更新缓存等;
测试论坛基本功能是否正常;检查附件是否能够正常上传;检查附件是否正常显示;全面检查控制台配置;
逐个开启插件并检查兼容性(短信通、马甲引擎等);
按二开备忘录逐个按需进行二开;
逐个修改调用论坛接口的项目及直接调用论坛数据库的项目;
调试 MAGAPP 接口;
尝试强制 https 访问;
将以上所有修改后的程序保留备份;发布升级公告并关闭论坛;重复以上步骤;修改域名解析;开启论坛;
配置 IP 封禁、定时器、日志、自动备份、配置其它 ECS 的 hosts 等;
查看搜索引擎中收录的地址,是否有无法访问的情况;
尝试将历史遗留的本地附件全部转移到 OSS;
建议 在新服上创建 3 个网站:
第 1 个用来尝试迁移、升级、二开,并测试所有功能;
第 2 个用来再次重复这些步骤,最终保留程序代码及 UGC 文件,作为最终的网站程序,以正式域名作为网站根目录路径;
第 3 个用来正式升级,主要功能是升级最新数据库。完成后修改第 2 个网站的数据库连接指向到最新的数据库,差异化同步新增的 UGC 文件到第 2 个网站。
Discuz! X 升级步骤及注意点:
因 PolarDB MySQL 不支持压缩,所以应移除 Discuz! 和 UCenter 代码中所有的 MYSQLI_CLIENT_COMPRESS,将 , MYSQLI_CLIENT_COMPRESS 替换为 /*, MYSQLI_CLIENT_COMPRESS*/。
升级前务必先修改 ./config/ 目录下的数据库/缓存连接信息,以防出现新站连接老库的情况;
按官方文档进行升级,升级前先修改一下:
【UC】先升级 UCenter 1.6 至 1.7。
将 /uc_server/data 权限改为 777 并递归。
打开 update_ucenter_adult.php 修改 $limit 值为 10000 以免执行超时。
因通信失败的“发送通知失败”可以直接改 URL 参数跳过就完成了,原因可能是因数据量大,发送改名通知执行改名时超时。等DZ升级完成后UC会自动重试改名通知,或单独写个 php 文件将 UCenter 的用户名同步到应用的数据库。
【DZ】运行到 /install/update_adult.php?step=innodb&table=pre_common_member_grouppm 时报错:Duplicate key name 'gpmid' ALTER TABLE common_member_grouppm ADD INDEX gpmid(gpmid);
解决方法:先删除索引,因保存时提示失败,应同时取消 gpmid 字段的自增,转换成功后再设置自增。
【DZ】运行到 /install/update_adult.php?step=file 一片空白而停止
正在解决
【问题】common_menber 表用户名字段编码转换失败
原因是部分用户名包含特殊字符(如全角空格),用以下语句查看两个表同一 uid 的不同用户:
SELECT u.uid, u.username AS ucenter_username, c.username AS common_username FROM pre_ucenter_members u JOIN pre_common_member c ON u.uid = c.uid WHERE u.username <> c.usernameDiscuz! 用户登录都是以 UCenter 中的用户名为主,所以可以写个小程序直接将 pre_ucenter_members 的用户名同步到 pre_common_member 中,另外 pre_ucenter_members 的用户数少于 pre_common_member 是正常的。若 pre_common_member_archive 表遇到错误同理。
如果用户登录慢,或打开 UCenter 慢,是因为 UC 正在通知 DZ 改用户名,每次打开一个页面会更改一个用户名,具体可以查看 pre_ucenter_notelist 中 closed 为 0 的队列,或进入 UC 后台-数据列表-通知列表 查看。
【问题】发布主题遇到错误:(1062) Duplicate entry '*' for key 'pid'
【原因】forum_post 中的 pid 不是自动增长的,而是由表 forum_post_tableid 中自动增长的 pid 生成的。如果生成的 pid 值已在 forum_post 表中存在,则会出现此错误。
【解决】迁移数据库时应关闭论坛,以防止 forum_post 表有新数据插入。
【问题】打开帖子页面 ./thread-***-1-1.html 显示 404 Not Found,而 ./forum.php?mod=viewthread&tid=*** 可以正常打开
【原因】未配置伪静态(可在宝塔面板中选择)
【问题】打开 UCenter 时报错:UCenter info: MySQL Query Error SQL:SELECT value FROM [Table]vars WHERE name='noteexists'
【解决】打开文件 ./uc_server/data/config.inc.php 配置数据库连接
【问题】打开登录 UCenter 后一片空白
【解决】将目录 ./uc_server/data/ 设为可写
需要将原来安装的插件文件移回 ./source/plugin/ 目录,并设置可写;
界面-表情管理,界面-编辑器设置-Discuz!代码
后续 Discuz! X3.5 小版本升级注意事项:
确认插件是否支持新版本(如短信通)
先创建一个新网站测试二开代码
保留 /config/、/data/、/uc_client/data/、/uc_server/data/、/source/plugin/,其它移入 old
上传文件
移回其它需要的文件,如:
-- 勋章/loading/logo/nv 等:/static/image/common/
-- 表情:/static/image/smiley/
-- 水印:/static/image/common/watermark.*
-- 风格:/template/default/style/t2/nv.png 等
-- 默认头像:/uc_server/images/noavatar_***.gif
-- 根目录 favicon.ico 等
-- 及其它非 DZ 文件
再次检查可写目录的写入权限和禁止运行 PHP 效果。

一、活动时间
2023年10月31日0点0分0秒至2026年3月31日23点59分59秒
二、活动对象
同时满足以下全部条件的阿里云用户:
1、阿里云注册会员用户;
2、完成阿里云实名认证;
3、符合活动规则的新老用户,均可参与。
三、活动权益参与规则
1、云服务器ECS经济型e实例(简称“99实例”或“99元e实例”)活动范围:
个人认证或者企业认证的用户购买指定配置“e实例2核2G,3M固定带宽,40G ESSD Entry 系统盘”可享受包1年99元,活动地域包含北京,杭州,上海,张家口,呼和浩特,深圳,成都,河源,乌兰察布,广州。
2、云服务器通用算力型u1实例(简称“199实例”或“199元u1实例”)活动范围:
企业认证的用户购买指定配置“u1实例2核4G,5M固定带宽,80G ESSD Entry 系统盘”可享受包1年199元,活动地域包含青岛,北京,杭州,上海,深圳,成都,河源,乌兰察布,广州,中国香港,日本(东京),新加坡,美国(硅谷),英国(伦敦),德国(法兰克福)。
3、活动说明:
在活动期间内,同一个人认证主体只可保有1个“99元e实例”;同一企业认证主体最多可同时保有1个“99元e实例”和1个“199元u1实例”,实例到期后在活动时间范围内可持续以低价续费保有,另购使用官网价。本次优惠不可与优惠券叠加使用。同一用户同一时间只能保有一个“99实例”或者“199实例”。
四、购买场景
1、新购场景:
在符合参与规则的情况下,直接低价购买指定配置产品,有效期1年。若无法购买,请确认是否存在同人或其他实例已占用等情况。
2、续费场景:
在活动时间内,指定配置每年最多可以以优惠价格续费1次,1次1年,直到活动时间结束持续享受续费优惠。
备注:若续费其他实例时使用了低价权益,原低价产品实例将无法再享受低价权益。
根据以上规则,常见场景有以下几种:
场景1:若您在2023年10月31日新购“99元e实例”,您可在2023年10月31日至2024年10月30日(即新购后的一年内)完成第一次续费(此时服务器到期时间为2025年10月30日);可在2024年10月31日至2025年10月30日完成第二次续费(此时服务器到期时间为2026年10月30日);可在2025年10月31日至2026年3月31日完成第三次续费(此时服务器到期时间为2027年10月30日);
即连续以99元1年的价格续费3年,可以使用“99元e实例”至2027年10月30日,该服务器总保有时长4年。
场景2:若您在2026年3月31日(活动截止前最后一天)新购“99元e实例”/“199元u1实例”,您可在2026年3月31日当天完成一次续费(此时服务器到期时间为2028年3月31日);
即以99元/199元1年的价格续费1年,可以使用“99元e实例”/“199元u1实例”至2028年3月31日,该服务器总保有时长2年。
场景3:若您在2024年4月1日新购“99元e实例”/“199元u1实例”,您可在2024年4月1日至2025年3月31日完成第一次续费(此时服务器到期时间为2026年3月31日);您可在2025年4月1日至2026年3月31日完成第二次续费(此时服务器到期时间为2027年3月31日);
即连续以99元/199元1年的价格续费2年,可以使用“99元e实例”/“199元u1实例”至2027年3月31日,服务器总保有时长3年。
3、退订场景:
支持五天无理由退款,退款后保留“低价长效”优惠资格,在活动时间范围内可再次使用低价购买活动配置;
4、变配场景:
变配至“低价长效优惠”指定配置时当前付费周期不享受低价权益,续费时可享受包1年99元/199元优惠;“低价长效优惠”指定配置发生变配/升级/降配操作后,变配需按照官网价补差价,请仔细阅读变配页面引导及相关资费说明,但仍占用权益资格直到该实例释放,购买相同规格产品不能再享受低价,同时续费时也不再享受包1年99元/199元优惠;
5、如用户账号有欠费,需先补足欠费再进行购买。
6、低价权益产品仅供账号本人使用,不允许过户转让。
7、如在参与“低价长效”优惠过程中,使用其他收费产品/功能,则需按照产品/功能标准资费支付超额产生的费用。
8、其他规则:
阿里云有权根据业务需求,随时调整提供给用户低价购买的产品范围、产品数量、产品配置、购买规则等,用户应以购买时相关页面的展示内容为准,但不影响用户在活动规则调整前已经获得的权益。
9、禁止使用产品来挖掘货币,如您使用产品来挖掘货币,可能会被收取费用及取消权益资格。
10、为保证活动的公平公正,如用户在活动中存在隐瞒、虚构、作弊、欺诈或通过其他非正常手段规避活动规则、获取不当利益的行为,例如:作弊领取、恶意套现、网络攻击、虚假交易等,阿里云有权收回相关权益、取消用户的活动参与资格,撤销违规交易,必要时追究违规用户的法律责任。
您应确保您对云服务器的使用不侵犯他人著作权,不会用于私服架设服务、私服程序、私服网站、私服源码、私服服务器和空间等。
五、常见FAQ:
1.用户在购买完99实例/199实例后,如果因某些原因导致需要退款或者释放实例,还可以再以99元/199元的优惠价格重新购买吗?
答:可以,99实例/199实例支持五天无理由退款,退款后仍然保留优惠资格,用户在活动时间范围内可再次使用低价购买活动配置;
2.活动规则里写的1年续费1次中,“1年”指的是自然年吗?
答:“1年”指的是云服务器购买1年的付费周期,即两次续费时间必须间隔1年以上;
3.99实例/199实例优惠套餐最多可以享受几年的优惠?
答:若您在24年3月31日前首次新购99实例/199实例优惠套餐,最多可以享受4年优惠(包含新购1次,续费3次,1次1年);
六、相关名词及解释
1、“阿里云官网”,是指包含域名为 www.aliyun.com/ 的网站以及阿里云客户端,如APP,但阿里云国际站,包括alibabacloud.com以及所有下属页面和jp.aliyun.com以及所有下属页面除外。
2、“同一用户”,是指根据不同阿里云账号在注册、登录、使用中的关联信息,阿里云判断其实际为同一用户。关联信息举例:同一手机号、同一邮箱、同一证件等。
3、“同人账号”,是指同一用户拥有多个阿里云账号的,各个账号之间互为同人账号。
4、“新用户”,是指在阿里云官网没有收费云产品购买记录的阿里云会员用户。新用户在进行首次云产品购买行为时,也被称为“首购用户”。
5、“老用户”,是指在阿里云官网已有收费云产品购买记录的阿里云会员用户。
6、“云产品”,是指阿里云官网售卖的中国大陆节点的产品和服务,但不包括域名、虚拟主机、云市场产品、专有云产品,云通信产品。
7、“指定云产品”,是指某场具体活动页面列举的活动云产品。
8、活动中涉及“打折”、“折扣”、“×折”或“省××元”,是指将本活动期间的某款产品的活动价格,与无任何活动期间的相同产品的日常最小单位售价(例如:月价),按相同购买时长进行比较后,所获得的比较结果。
9、活动涉及的“划线价”、“日常价”,通常是指该产品曾经展示过的销售价,并非原价,仅供参考。具体活动页面单独对“划线价”、“日常价”进行说明的,以其表述为准。
10、除非有相反证据证明外,用户参与活动所获得的全部权益和相应责任,均归属于参与活动的该阿里云账号所对应的实名认证主体。
11、活动中的“天”、“日”、“工作日”等均指该日的0点至24点(北京时间)。
12、阿里云可以根据活动的实际情况对活动规则进行变动或调整,相关变动或调整将公布在活动页面上,并于公布时即时生效;但不影响用户在活动规则调整前已经获得的权益。您购买阿里云单项产品时,亦应遵守该产品法律服务协议。
13、活动页面提到的“核” ,均指vcpu。
以下是使用定时器每秒钟请求服务器,并在后一个请求的响应比前一个请求的响应先到达客户端时抛弃前一个请求的响应的代码:
(以 $.post 为例,$.ajax 同理)
let previousXHR = null; // 存储前一个请求的 jqXHR 对象
function sendRequest() {
// 取消前一个请求
if (previousXHR) {
previousXHR.abort();
}
// 发送新的请求
const currentXHR = $.post(url, data, function(response) {
// 请求成功的回调函数
console.log(response);
});
// 更新前一个请求的 jqXHR 对象
previousXHR = currentXHR;
}
// 每秒钟发送请求
setInterval(sendRequest, 1000);如果你用 axios,请参此文。
解析域名(非网站域名)、挂载磁盘(若有另购)、修改实例名称、主机名
设置阿里云(重要)
远程连接进入 ECS(若解析未生效可以先用 IP)(若新服默认使用 3389 端口,可先在安全组临时放行 3389 端口)
开启 Windows 防火墙(使用推荐设置)
Windows 更新、并在高级选项中开启(更新 Windows 时接收其它 Microsoft 产品的更新)
安装 IIS:服务器管理器-添加角色和功能-勾选“Web 服务器(IIS)”包括管理工具
建议勾选:
默认已勾选项
按需安装 IP 和域限制
跟踪(即“失败请求跟踪”)
请求监视器、日志记录工具、
按需安装 ASP
按需安装 ASP.NET 4.8(会同时勾选 .NET Extensibility 4.8、ISAPI 扩展、ISAPI 筛选器)
按需安装 WebSocket 协议
应用程序初始化(建议安装)
管理服务(用于 Web 部署)
细节:设置任务栏;设置桌面图标;个性化-颜色-勾选“标题栏和窗口边框”;设置输入法;
下载 URL 重写(文件名:rewrite_amd64_zh-CN.msi)
下载 MySQL Connector/NET(文件名:mysql-connector-net-8.0.19.msi)
下载 ASP.NET Core 运行时 Hosting Bundle(文件名:dotnet-hosting-*.*.*-win.exe)
下载 .NET 桌面运行时 Windows x64(文件名:windowsdesktop-runtime-*.*.*-win-x64.exe)
下载 Web Deploy(文件名:WebDeploy_amd64_zh-CN.msi)
服务:设置“ASP.NET State Service”自动启动
IIS 日志:路径(如 D:\wwwlogs),每小时(统一设置一个全局的就行了,不需要设置每个网站),按需勾选“使用本地时间进行文件命名和滚动更新”
IIS 导入证书:个人、允许导出证书。参
设置默认网站的 https、设置默认网站跳转到指定网站。
设置权限:设置网站所在分区(如 D 盘),安全,添加 IIS_IUSRS,全部拒绝(防止跨站)
添加用户:为每个网站创建用户(既能防止跨站,又能跟踪进程),密码不能改、不过期,仅隶属于 IIS_IUSRS,并添加到每个网站的根目录,若用户创建失败看这里。
创建网站:设置访问物理路径的用户;设置应用程序池的“标识”用户;编辑绑定:勾选需要服务器名称指示;检查域名是否绑全;设置写入目录的用户权限;设置写入目录的“处理程序映射”取消“脚本”。
重复上面两步
检查所有网站用户是否仅隶属于 IIS_IUSRS(在“组”页面双击 Users 和 IIS_IUSRS 查看成员)
在应用程序池列表页面检查 CLR 版本、管托管道模式和标识;在网站列表页面检查绑定和路径
设置“IP 地址和域限制”
废弃旧服时再次检查:IIS 中各功能设置、hosts、安装的应用程序、启动项、任务计划程序、服务、防火墙等
接入 WAF
解析各网站域名
其它:资源管理器-选项-查看-去掉“始终显示图标,从不显示缩略图”前的勾
再次检查阿里云设置
在备份工具中添加该服务器的所有备份项
其它:到期日期提醒、
>> 关于域名解析
因各地域名解析生效时间不可控,一般国内域名 1 天内,国际域名 2 天内。
若网站数据库在 RDS、上传文件在 OSS,则解析 48 小时后直接停止原网站即可;(比较理想的)
文件上传到 ECS 的可使用 FTP 等工具定时同步文件,或直接停止原网站。(网友会遇到新文章中图片无法显示等问题)
还有一种方法是新网站提前解析一个备用域名,确保完全生效后再修改正式域名的解析,原网站无条件跳转到备用域名,如果数据库中有保存完整网址路径的,关闭原网站并解绑备用域名之后,进行批量替换。(缺点是可能会影响在搜索引擎的网站权重)
部分有定时器的网站要注意,如果两个网站的定时器都正常开启会导致意外的,需要停止其中一个网站的定时器。
当然每种方法都有优缺点,选择可以接受且方便的一种即可。
更多文章:
因需要将服务商账户改为月结账户,在抖店“电子面单”页面无法修改已申请的服务商,只能取消合作,再重新开通,这会导致易打单无法打印面单,提示“请设置抖音电子面单地址”。
解决方法是进入易打单,在“批量打印”页面点击“设置模板”,抖店电子面单项刷新并重新勾选,保存。
一般我们使用原生 JS 的时候使用 abort() 来取消 fetch 请求。
在使用 axios 发送请求时,如果我们想要取消请求,可以使用 axios 提供的 CancelToken 和 cancel 方法。下面是具体的实现步骤:
// 创建 CacnelToken 实例
const cancelTokenSource = axios.CancelToken.source();
// GET 方式请求
axios.get(url, {
cancelToken: cancelTokenSource.token
}).catch(thrown => {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
console.log('An error occurred', thrown);
}
});
// POST 方式请求
axios.post(url, data, {
cancelToken: cancelTokenSource.token
});
// 取消请求
cancelTokenSource.cancel('请求被取消');get 请求的时候,cancelToken 是放在第二个参数里;post 的时候,cancelToken 是放在第三个参数里。axios-0.27.2 中测试成功。
在即时响应的搜索框中可以这样处理:(vue3)
let cancelTokenSource;
const app = Vue.createApp({
methods: {
fn_list: function () {
// 如果已有请求则取消
cancelTokenSource && cancelTokenSource.cancel();
// 创建一个新的请求
cancelTokenSource = axios.CancelToken.source();
axios.post(url, data, {
cancelToken: cancelTokenSource.token
}).then(function (response) {
// 请求成功
}).catch(function (error) {
// 请求失败/取消
});
},
}
});
const vm = app.mount('#app');如果你用 jQuery,请参此文。
