

把选中的座位按并排分组后,每组座位的:
两侧都有且仅有一个空位时,往影院中央移一座;
一侧有且仅有一个空位,另一侧有连续的大于1个空位时,往仅有一个空位一侧移一座;
其它情况不移动。
逻辑实现时须注意:
在判断某组时,其它组中的座位视为已售;
循环组时应优先判断远离影院中央的座位组,这样可以尽可能地往中央移座;
循环中一旦遇到移座情况,应重新分组优化选座。

- 因为只有“认证的服务号”才有“网页授权获取用户基本信息”接口功能,所以首先你得拥有已认证的服务号,和一个已认证的订阅号(就是本例中用来被加粉的)。订阅号必须认证才有“获取用户基本信息”接口功能
- 注册微信·开放平台,绑定这两个公众号
- 实现过程:用订阅号的权限获取所有用户信息(绑定到开放平台后用户接口返回的数据已包含 UnionID),并且当用户关注或取消关注时更新用户信息;打开网页时,用服务号的权限获取当前用户的 UnionID;由于这两个公众号绑定在同一个开放平台,所以这两个 UnionID 对同一用户是一样的,这样就可以实现在网页上判断用户是否已关注订阅号

 资源中心
资源中心在开发微信中的网页时,会遇到一些域名相关的配置:
① 公众号设置 - 功能设置 - 业务域名
② 公众号设置 - 功能设置 - JS接口安全域名
③ 接口权限 - 网页授权获取用户基本信息
④ 商户平台 - 产品中心 - 开发配置 - JSAPI支付授权目录
⑤ 小程序 - 开发 - 开发设置 - 业务域名
⑥ 公众号开发 - 基本设置 - IP白名单
第①种 业务域名:相对不重要,只是用来禁止显示“防欺诈盗号,请勿支付或输入qq密码”提示框,可配置 3 个二级或二级以上域名(个人理解是“非顶级域名”,即填写了 b.a.com 的话,对 c.b.a.com 不起作用,待测)。
我们网站的域名和公众号是没有绑定关系的,那么你在打开一个(可能是朋友分享的)网页时,跟哪个公众号的配置去关联呢,答案是 JS-SDK。
测试结果:由于一个月只有3次修改机会,这次先测二级域名,有效;再测顶级域名,有效;删除所有,仍有效。所以应该是缓存作用。过几天再试,然后下个月先测顶级域名,来确定直接填写顶级域名是否对所有二级域名有效。
第②种 JS接口安全域名:是配置所配置的域名下的网页可调用 JS-SDK。可配置 5 个一级或一级以上域名(个人理解是“任何级域名”,即填写了 b.a.com 对 c.b.a.com 也有效,但对 c.z.a.com 无效,待测。如果我们拥有顶级域名对应网站的控制权(上传验证文件到网站根目录),直接填写顶级域名即可)。
使用 JS-SDK 的每个网页都必须注入配置信息(wx.config),而之前必须获取 jsapi_ticket,jsapi_ticket api 的调用次数非常有限,必须全局缓存。而获取 jsapi_ticket 之前必须先获取 access_token,同样需要全局缓存。所以,我们专门做个接口,功能是传入需要使用 JS-SDK 的网页的 url,输出 wx.config 需要用到的配置信息,来实现在不同网页(网站)使用 JS-SDK。
第③种 网页授权域名:这是已认证的服务号才能享有的特权,主要作用是获取用户在该服务号中的 openid 和 unionid。可配置 1 个 2 个回调域名(可填写任意级别的域名,但仅对该域名的网页(网站)有效,若填写了 a.com 对 b.a.com 是无效的)。
因此,如果我们需要在不同二级域名甚至不同顶级域名下的网页(以下称之为活动页面)实现用户授权,需要做一个统一的代理授权页面(回调域名当然是填写这个页面所在的域名),引导用户依次打开:微信授权页面 - 代理授权页面 - 活动页面,根据开发说明文档,具体实现如下:
当用户第一次打开活动页面时,引导打开微信授权页面(https://open.weixin.qq.com/connect/oauth2/authorize),其中参数 redirect_uri 指定回调地址,即代理授权页面地址,参数 state 指定活动页面地址。微信授权页面返回 code 和 state,code 作为换取网页授权 access_token 的票据。到这一步,本来可以由代理授权页面直接拿这个 code 去换取 access_token、openid 和 unionid 了,但是由于当前用户还在 302 重定向过程中,将这些信息带入到活动页面时势必导致信息泄露,所以这里将 code 追加到 state 指定的网址上后重定向到活动页面,活动页面拿到 code 再通过服务器端向代理授权页面所在服务器请求 openid 和 unionid,并将它们保存于 Session 中视为用户登录。这样,服务号的 appid 和 secret 也能得到保护。代理授权页面请求的微信服务器接口地址是 https://api.weixin.qq.com/sns/oauth2/access_token。
注:网页授权 access_token 不同于 JS-SDK 中使用的全局唯一接口调用凭据 access_token,没有请求次数限制。
流程既然通了,实现逻辑可以这样设定:
活动页面首先判断 Session 中是否有 openid 或 unionid,若有表示已授权登录;没有再判断地址栏是否有 code 参数,若有则调用代理授权页面所在服务器的接口,用 code 换 openid 和 unionid;没有则直接重定向到代理授权页面,带上 state。用 code 换 openid 和 unionid 时若成功则保存至 Session,若失败则仍然重定向到代理授权页面,带上 state,特别注意 state 中的活动页面地址确保没有 code 参数。
第④种 JSAPI支付授权目录:涉及到微信支付时用到,顾名思义是固定某一个网站内的某个目录,以“/”结尾。最多可添加 5 个。如果支付页面在目录 https://www.a.com/b/ 下,那么可以填写 https://www.a.com/b/ 或 https://www.a.com/(建议后者),暂未测试填写 https://a.com/ 会不会起作用。涉及支付安全,建议设置支付页面的最深一层不可写的目录,以防目录内被上传后门文件带来的安全隐患。
第⑤种 小程序业务域名:任何需要在小程序的 web-view 组件中打开的网页,都必须配置小程序业务域名,限制 20 个。该域名要求必须 https,可填入“任何级域名”(建议填顶级域名,即填写了 a.com 对 b.a.com 也有效。如果我们拥有顶级域名对应网站的控制权(上传验证文件到网站根目录),直接填写顶级域名即可)。
第⑥种 IP白名单:仅填写管理全局 access_token 的中控服务器的 IP。
总结:在上述自定义接口部署完成后,如果微信中的网页想获取用户的 unionid,则不需要配置域名,直接使用统一的代理授权即可;如果需要使用 JS-SDK 功能,如分享、上传等等,则需要配置 JS 接口安全域名;如果有表单,最好配置一下业务域名。
本文系个人经验总结,部分结果未经证实,欢迎指正!QQ:940534113
在 ASP.NET Core 或 ASP.NET 5 中部署百度编辑器请跳转此文。
本文记录百度编辑器 ASP.NET 版的部署过程,对其它语言版本也有一定的参考价值。
【2020.02.21 重新整理】
下载
从 GitHub 下载最新发布版本:https://github.com/fex-team/ueditor/releases
按编码分有 gbk 和 utf8 两种版本,按服务端编程语言分有 asp、jsp、net、php 四种版本,按需下载。
目录介绍
以 v1.4.3.3 utf8-net 为例,

客户端部署
本例将上述所有目录和文件拷贝到网站目录 /libs/ueditor/ 下。
当然也可以引用 CDN 静态资源,但会遇到诸多跨域问题,不建议。
在内容编辑页面引入:
<script src="/libs/ueditor/ueditor.config.js"></script>
<script src="/libs/ueditor/ueditor.all.min.js"></script>在内容显示页面引入:
<script src="/libs/ueditor/ueditor.parse.min.js"></script>如需修改编辑器资源文件根路径,参 ueditor.config.js 文件内顶部文件。(一般不需要单独设置)
如果使用 CDN,那么在初始化 UE 实例的时候应配置 serverUrl 值(即 controller.ashx 所在路径)。
客户端配置
初始化 UE 实例:
var ue = UE.getEditor('tb_content', {
// serverUrl: '/libs/ueditor/net/controller.ashx', // 指定服务端接收文件路径
initialFrameWidth: '100%'
});其它参数见官方文档,或 ueditor.config.js 文件。
服务端部署
net 目录是 ASP.NET 版的服务端程序,用来实现接收上传的文件等功能。
本例中在网站中的位置是 /libs/ueditor/net/。如果改动了位置,那么在初始化 UE 的时候也应该配置 serverUrl 值。
这是一个完整的 VS 项目,可以单独部署为一个网站。其中:
net/config.json 服务端配置文件
net/controller.ashx 文件上传入口
net/App_Code/CrawlerHandler.cs 远程抓图动作
net/App_Code/ListFileManager.cs 文件管理动作
net/App_Code/UploadHandler.cs 上传动作
该目录不需要转换为应用程序。
服务端配置
根据 config.json 中 *PathFormat 的默认配置,一般地,上传的图片会保存在 controller.ashx 文件所在目录(即本例中的 /libs/ueditor/)的 upload 目录中:
/libs/ueditor/upload/image/
原因是 UploadHandler.cs 中 Server.MapPath 的参数是由 *PathFormat 决定的。
以修改 config.json 中的 imagePathFormat 为例:
原值:"imagePathFormat": "upload/image/{yyyy}{mm}{dd}/{time}{rand:6}"
改为:"imagePathFormat": "/upload/ueditor/{yyyy}{mm}{dd}/{time}{rand:6}"
以“/”开始的路径在 Server.MapPath 时会定位到网站根目录。
此处不能以“~/”开始,因为最终在客户端显示的图片路径是 imageUrlPrefix + imagePathFormat,若其中包含符号“~”就无法正确显示。
在该配置文件中查找所有 PathFormat,按相同的规则修改。
说到客户端的图片路径,我们只要将
原值:"imageUrlPrefix": "/ueditor/net/"
改为:"imageUrlPrefix": ""
即可返回客户端正确的 URL。
当然也要同步修改 scrawlUrlPrefix、snapscreenUrlPrefix、catcherUrlPrefix、videoUrlPrefix、fileUrlPrefix。
特殊情况,在复制包含图片的网页内容的操作中,若图片地址带“?”等符号,会出现无法保存到磁盘的情况,需要修改以下代码:
打开 CrawlerHandler.cs 文件,找到
ServerUrl = PathFormatter.Format(Path.GetFileName(this.SourceUrl), Config.GetString("catcherPathFormat"));替换成:
ServerUrl = PathFormatter.Format(Path.GetFileName(SourceUrl.Contains("?") ? SourceUrl.Substring(0, SourceUrl.IndexOf("?")) : SourceUrl), Config.GetString("catcherPathFormat"));如果你将图片保存到第三方图库,那么 imageUrlPrefix 值设为相应的域名即可,如:
改为:"imageUrlPrefix": "//cdn.***.com"
然后在 UploadHandler.cs 文件(用于文件上传)中找到
File.WriteAllBytes(localPath, uploadFileBytes);在其下方插入上传到第三方图库的代码,以阿里云 OSS 为例:
// 上传到 OSS
client.PutObject(bucketName, savePath.Substring(1), localPath);在 CrawlerHandler.cs 文件(无程抓图上传)中找到
File.WriteAllBytes(savePath, bytes);在其下方插入上传到第三方图库的代码,以阿里云 OSS 为例:
// 上传到 OSS
client.PutObject(bucketName, ServerUrl.Substring(1), savePath);最后有还有两个以 UrlPrefix 结尾的参数名 imageManagerUrlPrefix 和 fileManagerUrlPrefix 分别是用来列出上传目录中的图片和文件的,
对应的操作是在编辑器上的“多图上传”功能的“在线管理”,和“附件”功能的“在线附件”。
最终列出的图片路径是由 imageManagerUrlPrefix + imageManagerListPath + 图片 URL 组成的,那么:
"imageManagerListPath": "/upload/ueditor/image",
"imageManagerUrlPrefix": "",
以及:
"fileManagerListPath": "/upload/ueditor/file",
"fileManagerUrlPrefix": "",
即可。
如果是上传到第三方图库的,且图库上的文件与本地副本是一致的,那么将 imageManagerUrlPrefix 和 fileManagerUrlPrefix 设置为图库域名,
服务端仍然以 imageManagerListPath 指定的路径来查找本地文件(非图库),但客户端显示图库的文件 URL。
因此,如果文件仅存放在图库上,本地没有副本的情况就无法使用该功能了。
综上,所有的 *UrlPrefix 应该设为一致。
另外记得配置不希望被远程抓图的域名,参数 catcherLocalDomain。
服务端授权
现在来判断一下只有登录用户才允许上传。
首先打开服务端的统一入口文件 controller.ashx,
继承类“IHttpHandler”改为“IHttpHandler, System.Web.SessionState.IRequiresSessionState”,即同时继承两个类,以便可使用 Session,
找到“switch”,其上插入:
if (用户未登录) { throw new System.Exception("请登录后再试"); }即用户已登录或 action 为获取 config 才进入 switch。然后,
else
{
action = new NotAllowedHandler(context);
}这里的 NotAllowedHandler 是参照 NotSupportedHandler 创建的,提示语 state 可以是“登录后才能进行此操作。”
上传目录权限设置
上传目录(即本例中的 /upload/ueditor/ 目录)应设置允许写入和禁止执行。
基本用法
设置内容:
ue.setContent("Hello world.");获取内容:
var a = ue.getContent();更多用法见官方文档:http://fex.baidu.com/ueditor/#api-common
其它事宜
配置上传附件的文件格式
找到文件:config.json,更改“上传文件配置”的 fileAllowFiles 项,
同时在 Web 服务器上允许这些格式的文件可访问权限。以 IIS 为例,在“MIME 类型”模块中添加扩展名。
遇到从客户端(......)中检测到有潜在危险的 Request.Form 值。请参考此文
另外,对于不支持上传 .webp 类型的图片的问题,可以作以下修改:
config.json 中搜索“".bmp"”,替换为“".bmp", ".webp"”
IIS 中选中对应网站或直接选中服务器名,打开“MIME 类型”,添加,文件扩展名为“.webp”,MIME 类型为“image/webp”
最后,为了在内容展示页面看到跟编辑器中相同的效果,请参照官方文档引用 uParse
若有插入代码,再引用:
<link href="/lib/ueditor/utf8-net/third-party/SyntaxHighlighter/shCoreDefault.css" rel="stylesheet" />
<script src="/lib/ueditor/utf8-net/third-party/SyntaxHighlighter/shCore.js"></script>
其它插件雷同。
若对编辑器的尺寸有要求,在初始化时设置即可:
var ue = UE.getEditor('tb_content', {
initialFrameWidth: '100%',
initialFrameHeight: 320
});
本文适用于 IIS 7, IIS 7.5, IIS 8, IIS 8.5, IIS 10 等 Web 服务器,IIS 6(Windows Server 2003)用户请查阅 ISAPI_Rewrite。
在 IIS 中要实现 URL 重写,需要下载并安装 URL Rewrite 组件,http://www.iis.net/downloads/microsoft/url-rewrite
在 IIS 管理器中选中任意网站,主窗口可见“URL 重写”,双击打开。(如果你想配置这台服务器的所有网站有效,直接选中左侧菜单中的服务器名,打开“URL 重写”即可。)
右侧“添加规则...”,选择“入站规则”中的“空白规则”,确定。
填写规则名称,在“匹配 URL”框中选择“与模式匹配”,根据自己的需求选择“正则表达式”、“通配符”或“完全匹配”,“模式”中填写要防盗链的文件路径规则,例如正则表达式 ^.*\.(jpg|png)$ 将匹配所有目录下的 .jpg 和 .png 文件。
接下来将设置图片在允许的域名下显示。
在“条件”框中选择“全部匹配”,点击“添加”,“条件输入”中填写“{HTTP_REFERER}”(不含引号,含花括号),表示判断 HTTP 请求中 Header 的 Referer。选择“与模式不匹配”,模式中填写匹配规则,如 ^$ 表示允许 Referer 为空(如直接从浏览器打开的情况),再加一个规则 ^https?://([^/]*\.)?(xoyozo.net|himiao.com)/.*$ 表示允许在 xoyozo.net 和 himiao.com 这两个域名下显示图片。当然如果你有很多域名或需要设置不同的规则,可以继续添加,但最好把访问量大的规则移到前面,从而减少系统匹配次数,提高访问效率。
最后,在“操作”框中设置你想要的处理方式,可以是“重定向”到一张防盗链提醒的图片上(推荐类型临时 307),也可以自定义响应,例如,状态代码(403),子代码(0),原因(Forbidden: Access is denied.),描述(You do not have permission to view this directory or page using the credentials that you supplied.),查看 HTTP 状态代码。
如果你是配置某个网站的“URL 重写”,那么在网站根目录下的 web.config 文件中,<system.webServer /> 节点下可以看到刚刚配置的规则,例如:
<rewrite>
<rules>
<rule name="RequestBlockingRule1" stopProcessing="true">
<match url="^.*\.(jpg|png)$" />
<conditions>
<add input="{HTTP_REFERER}" pattern="^https?://([^/]*\.)?(xoyozo.net|himiao.com)/.*$" negate="true" />
<add input="{HTTP_REFERER}" pattern="^$" negate="true" />
</conditions>
<action type="Redirect" url="http://42.96.165.253/logo2013.png" redirectType="Temporary" />
</rule>
</rules>
</rewrite>
真机同步:Ctrl + R
注释/取消注释代码:Ctrl + /
整理代码:Ctrl + Shift + F
var iOS7AndLater = api.systemType == 'ios' && parseFloat(api.systemVersion) >= 7; // api.systemVersion 结果类似 4.5.6,parseFloat 后 iOS 为 4, Android 为 4.5
api.addEventListener({
name:'swipedown'
},function(ret,err){
//operation
});
api.addEventListener({
name:'swipeup'
},function(ret,err){
//operation
});
有时候在监听 swipedown 和 swipeup 事件时没有进入 callback,原因是打开这个 window 或 frame 时,bounces 是 true 的,只要将 bounces: false 即可。
api.showProgress();
api.hideProgress();
api.openFrame({
name
url
rect
});
api.openFrameGroup
api.openWin
api.setRefreshHeaderInfo({},function(ret,err){
// coding...
alert("正在用力刷新");
api.refreshHeaderLocalDone();
});
localStorage.setItem("xxx",ret.id);
if(localStorage.getItem("xxx")){ }

编者按:今天腾讯万技师同学的这篇技术总结必须强烈安利下,目录清晰,层次分明,每个接口都有对应的简介、系统要求、实例、核心代码以及超实用的思维发散,帮你直观把这些知识点get起来。以现在HTML 5的势头,同志们,你看到的这些,可都是钱呐。
十二年前,无论多么复杂的布局,在我们神奇的table面前,都不是问题;
十年前,阿捷的一本《网站重构》,为我们开启了新的篇章;
八年前,我们研究yahoo.com,惊叹它在IE5下都表现得如此完美;
六年前,Web标准化成了我们的基础技能,我们开始研究网站性能优化;
四年前,我们开始研究自动化工具,自动化测试,谁没玩过nodejs都不好意思说是页面仔;
二年前,各种终端风起云涌,响应式、APP开发都成为了我们研究的范围,CSS3动画开始风靡;
如今,CSS3动画、Canvas、SVG、甚至webGL你已经非常熟悉,你是否开始探寻,接下来,我们可以玩什么,来为我们项目带来一丝新意?
没错,本文就是以HTML5 Device API为核心,对HTML5的一些新接口作了一个完整的测试,希望能让大家有所启发。
目录:
一、让音乐随心而动 – 音频处理 Web audio API
二、捕捉用户摄像头 – 媒体流 Media Capture
三、你是逗逼? – 语音识别 Web Speech API
四、让我尽情呵护你 – 设备电量 Battery API
五、获取用户位置 – 地理位置 Geolocation API
六、把用户捧在手心 – 环境光 Ambient Light API
七、陀螺仪 Deviceorientation
八、Websocket
九、NFC
十、震动 - Vibration API
十一、网络环境 Connection API
一、让音乐随心而动 – 音频处理 Web audio API
简介:
Audio对象提供的只是音频文件的播放,而Web Audio则是给了开发者对音频数据进行分析、处理的能力,比如混音、过滤。
系统要求:
ios6+、android chrome、android firefox
实例:

http://sy.qq.com/brucewan/device-api/web-audio.html
核心代码:
var context = new webkitAudioContext();
var source = context.createBufferSource(); // 创建一个声音源
source.buffer = buffer; // 告诉该源播放何物
createBufferSourcesource.connect(context.destination); // 将该源与硬件相连
source.start(0); //播放
技术分析:
当我们加载完音频数据后,我们将创建一个全局的AudioContext对象来对音频进行处理,AudioContext可以创建各种不同功能类型的音频节点AudioNode,比如

1、源节点(source node)
我们可以使用两种方式加载音频数据:
<1>、audio标签
var sound, audio = new Audio();
audio.addEventListener('canplay', function() {
sound = context.createMediaElementSource(audio);
sound.connect(context.destination);
});
audio.src = '/audio.mp3';
<2>、XMLHttpRequest
var sound, context = createAudioContext();
var audioURl = '/audio.mp3'; // 音频文件URL
var xhr = new XMLHttpRequest();
xhr.open('GET', audioURL, true);
xhr.responseType = 'arraybuffer';
xhr.onload = function() {
context.decodeAudioData(request.response, function (buffer) {
source = context.createBufferSource();
source.buffer = buffer;
source.connect(context.destination);
}
}
xhr.send();
2、分析节点(analyser node)
我们可以使用AnalyserNode来对音谱进行分析,例如:
var audioCtx = new (window.AudioContext || window.webkitAudioContext)();
var analyser = audioCtx.createAnalyser();
analyser.fftSize = 2048;
var bufferLength = analyser.frequencyBinCount;
var dataArray = new Uint8Array(bufferLength);
analyser.getByteTimeDomainData(dataArray);
function draw() {
drawVisual = requestAnimationFrame(draw);
analyser.getByteTimeDomainData(dataArray);
// 将dataArray数据以canvas方式渲染出来
};
draw();
3、处理节点(gain node、panner node、wave shaper node、delay node、convolver node等)
不同的处理节点有不同的作用,比如使用BiquadFilterNode调整音色(大量滤波器)、使用ChannelSplitterNode分割左右声道、使用GainNode调整增益值实现音乐淡入淡出等等。
需要了解更多的音频节点可能参考:
https://developer.mozilla.org/en-US/docs/Web/API/Web_Audio_API
4、目的节点(destination node)
所有被渲染音频流到达的最终地点
思维发散:
1、可以让CSS3动画跟随背景音乐舞动,可以为我们的网页增色不少;
2、可以尝试制作H5酷酷的变声应用,增加与用户的互动;
3、甚至可以尝试H5音乐创作。
看看google的创意:http://v.youku.com/v_show/id_XNTk0MjQyNDMy.html
二、捕捉用户摄像头 – 媒体流 Media Capture
简介:
通过getUserMedia捕捉用户摄像头获取视频流和通过麦克风获取用户声音。
系统要求:
android chrome、android firefox
实例:
捕获用户摄像头 捕获用户麦克风

http://sy.qq.com/brucewan/device-api/camera.html

http://sy.qq.com/brucewan/device-api/microphone-usermedia.html
核心代码:
1、摄像头捕捉
navigator.webkitGetUserMedia ({video: true}, function(stream) {
video.src = window.URL.createObjectURL(stream);
localMediaStream = stream;
}, function(e){
})
2、从视频流中拍照
btnCapture.addEventListener('touchend', function(){
if (localMediaStream) {
canvas.setAttribute('width', video.videoWidth);
canvas.setAttribute('height', video.videoHeight);
ctx.drawImage(video, 0, 0);
}
}, false);
3、用户声音录制
navigator.getUserMedia({audio:true}, function(e) {
context = new audioContext();
audioInput = context.createMediaStreamSource(e);
volume = context.createGain();
recorder = context.createScriptProcessor(2048, 2, 2);
recorder.onaudioprocess = function(e){
recordingLength += 2048;
recorder.connect (context.destination);
}
}, function(error){});
4、保存用户录制的声音
var buffer = new ArrayBuffer(44 + interleaved.length * 2);
var view = new DataView(buffer);
fileReader.readAsDataURL(blob); // android chrome audio不支持blob
… audio.src = event.target.result;
思维发散:
1、从视频拍照自定义头像;
2、H5视频聊天;
3、结合canvas完成好玩的照片合成及处理;
4、结合Web Audio制作有意思变声应用。
三、你是逗逼? – 语音识别 Web Speech API简介:
1、将文本转换成语音;
2、将语音识别为文本。
系统要求:
ios7+,android chrome,android firefox
测试实例:

http://sy.qq.com/brucewan/device-api/microphone-webspeech.html
核心代码:
1、文本转换成语音,使用SpeechSynthesisUtterance对象;
var msg = new SpeechSynthesisUtterance();
var voices = window.speechSynthesis.getVoices();
msg.volume = 1; // 0 to 1
msg.text = ‘识别的文本内容’;
msg.lang = 'en-US';
speechSynthesis.speak(msg);
2、语音转换为文本,使用SpeechRecognition对象。
var newRecognition = new webkitSpeechRecognition();
newRecognition.onresult = function(event){
var interim_transcript = '';
for (var i = event.resultIndex; i < event.results.length; ++i) {
final_transcript += event.results[i][0].transcript;
}
};
测试结论:
1、Android支持不稳定;语音识别测试失败(暂且认为是某些内置接口被墙所致)。
思维发散:
1、当语音识别成为可能,那声音控制将可以展示其强大的功能。在某些场景,比如开车、网络电视,声音控制将大大改善用户体验;
2、H5游戏中最终分数播报,股票信息实时声音提示,Web Speech都可以大放异彩。
四、让我尽情呵护你 – 设备电量 Battery API简介:
查询用户设备电量及是否正在充电。
系统要求:
android firefox
测试实例:

http://sy.qq.com/brucewan/device-api/battery.html
核心代码:
var battery = navigator.battery || navigator.webkitBattery || navigator.mozBattery || navigator.msBattery;
var str = '';
if (battery) {
str += '<p>你的浏览器支持HTML5 Battery API</p>';
if(battery.charging) {
str += '<p>你的设备正在充电</p>';
} else {
str += '<p>你的设备未处于充电状态</p>';
}
str += '<p>你的设备剩余'+ parseInt(battery.level*100)+'%的电量</p>';
} else {
str += '<p>你的浏览器不支持HTML5 Battery API</p>';
}
测试结论:
1、QQ浏览器与UC浏览器支持该接口,但未正确显示设备电池信息;
2、caniuse显示android chrome42支持该接口,实测不支持。
思维发散:
相对而言,我觉得这个接口有些鸡肋。
很显然,并不合适用HTML5做电池管理方面的工作,它所提供的权限也很有限。
我们只能尝试做一些优化用户体验的工作,当用户设备电量不足时,进入省电模式,比如停用滤镜、摄像头开启、webGL、减少网络请求等。
五、获取用户位置 – 地理位置 Geolocation简介:
Geolocation API用于将用户当前地理位置信息共享给信任的站点,目前主流移动设备都能够支持。
系统要求:
ios6+、android2.3+
测试实例:

http://sy.qq.com/brucewan/device-api/geolocation.html
核心代码:
var domInfo = $("#info");
// 获取位置坐标
if (navigator.geolocation) {
navigator.geolocation.getCurrentPosition(showPosition,showError);
}
else{
domInfo.innerHTML="抱歉,你的浏览器不支持地理定位!";
}
// 使用腾讯地图显示位置
function showPosition(position) {
var lat=position.coords.latitude;
var lon=position.coords.longitude;
mapholder = $('#mapholder')
mapholder.style.height='250px';
mapholder.style.width = document.documentElement.clientWidth + 'px';
var center = new soso.maps.LatLng(lat, lon);
var map = new soso.maps.Map(mapholder,{
center: center,
zoomLevel: 13
});
var geolocation = new soso.maps.Geolocation();
var marker = null;
geolocation.position({}, function(results, status) {
console.log(results);
var city = $("#info");
if (status == soso.maps.GeolocationStatus.OK) {
map.setCenter(results.latLng);
domInfo.innerHTML = '你当前所在城市: ' + results.name;
if (marker != null) {
marker.setMap(null);
}
// 设置标记
marker = new soso.maps.Marker({
map: map,
position:results.latLng
});
} else {
alert("检索没有结果,原因: " + status);
}
});
}
测试结论:
1、Geolocation API的位置信息来源包括GPS、IP地址、RFID、WIFI和蓝牙的MAC地址、以及GSM/CDMS的ID等等。规范中没有规定使用这些设备的先后顺序。
2、初测3g环境下比wifi环境理定位更准确;
3、测试三星 GT-S6358(android2.3) geolocation存在,但显示位置信息不可用POSITION_UNAVAILABLE。
六、把用户捧在手心 – 环境光 Ambient Light简介:
Ambient Light API定义了一些事件,这些时间可以提供源于周围光亮程度的信息,这通常是由设备的光感应器来测量的。设备的光感应器会提取出辉度信息。
系统要求:
android firefox
测试实例:

http://sy.qq.com/brucewan/device-api/ambient-light.html
核心代码:
这段代码实现感应用前当前环境光强度,调整网页背景和文字颜色。
var domInfo = $('#info');
if (!('ondevicelight' in window)) {
domInfo.innerHTML = '你的设备不支持环境光Ambient Light API';
} else {
var lightValue = document.getElementById('dl-value');
window.addEventListener('devicelight', function(event) {
domInfo.innerHTML = '当前环境光线强度为:' + Math.round(event.value) + 'lux';
var backgroundColor = 'rgba(0,0,0,'+(1-event.value/100) +')';
document.body.style.backgroundColor = backgroundColor;
if(event.value < 50) {
document.body.style.color = '#fff'
} else {
document.body.style.color = '#000'
}
});
}
思维发散:
该接口适合的范围很窄,却能做出很贴心的用户体验。
1、当我们根据Ambient Light强度、陀螺仪信息、当地时间判断出用户正躺在床上准备入睡前在体验我们的产品,我们自然可以调整我们背景与文字颜色让用户感觉到舒适,我们还可以来一段安静的音乐,甚至使用Web Speech API播报当前时间,并说一声“晚安”,何其温馨;
2、该接口也可以应用于H5游戏场景,比如日落时分,我们可以在游戏中使用安静祥和的游戏场景;
3、当用户在工作时间将手机放在暗处,偷偷地瞄一眼股市行情的时候,我们可以用语音大声播报,“亲爱的,不用担心,你的股票中国中车马上就要跌停了”,多美的画面。
参考文献:
https://developer.mozilla.org/en-US/docs/Web/API
http://webaudiodemos.appspot.com/
http://www.w3.org/2009/dap/
我们继续讲解LINQ to SQL语句,这篇我们来讨论Group By/Having操作符和Exists/In/Any/All/Contains操作符。
Group By/Having操作符
适用场景:分组数据,为我们查找数据缩小范围。
说明:分配并返回对传入参数进行分组操作后的可枚举对象。分组;延迟
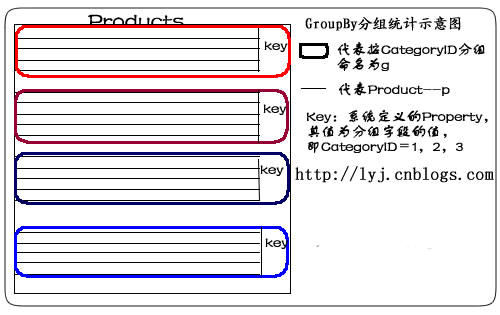
1.简单形式:
var q =
from p in db.Products
group p by p.CategoryID into g
select g;
语句描述:使用Group By按CategoryID划分产品。
说明:from p in db.Products 表示从表中将产品对象取出来。group p by p.CategoryID into g表示对p按CategoryID字段归类。其结果命名为g,一旦重新命名,p的作用域就结束了,所以,最后select时,只能select g。当然,也不必重新命名可以这样写:
var q =
from p in db.Products
group p by p.CategoryID;
我们用示意图表示:
如果想遍历某类别中所有记录,这样:
foreach (var gp in q)
{
if (gp.Key == 2)
{
foreach (var item in gp)
{
//do something
}
}
}
2.Select匿名类:
var q =
from p in db.Products
group p by p.CategoryID into g
select new { CategoryID = g.Key, g };
说明:在这句LINQ语句中,有2个property:CategoryID和g。这个匿名类,其实质是对返回结果集重新进行了包装。把g的property封装成一个完整的分组。如下图所示:

如果想遍历某匿名类中所有记录,要这么做:
foreach (var gp in q)
{
if (gp.CategoryID == 2)
{
foreach (var item in gp.g)
{
//do something
}
}
}
3.最大值
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
MaxPrice = g.Max(p => p.UnitPrice)
};
语句描述:使用Group By和Max查找每个CategoryID的最高单价。
说明:先按CategoryID归类,判断各个分类产品中单价最大的Products。取出CategoryID值,并把UnitPrice值赋给MaxPrice。
4.最小值
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
MinPrice = g.Min(p => p.UnitPrice)
};
语句描述:使用Group By和Min查找每个CategoryID的最低单价。
说明:先按CategoryID归类,判断各个分类产品中单价最小的Products。取出CategoryID值,并把UnitPrice值赋给MinPrice。
5.平均值
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
AveragePrice = g.Average(p => p.UnitPrice)
};
语句描述:使用Group By和Average得到每个CategoryID的平均单价。
说明:先按CategoryID归类,取出CategoryID值和各个分类产品中单价的平均值。
6.求和
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
TotalPrice = g.Sum(p => p.UnitPrice)
};
语句描述:使用Group By和Sum得到每个CategoryID 的单价总计。
说明:先按CategoryID归类,取出CategoryID值和各个分类产品中单价的总和。
7.计数
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
NumProducts = g.Count()
};
语句描述:使用Group By和Count得到每个CategoryID中产品的数量。
说明:先按CategoryID归类,取出CategoryID值和各个分类产品的数量。
8.带条件计数
var q =
from p in db.Products
group p by p.CategoryID into g
select new {
g.Key,
NumProducts = g.Count(p => p.Discontinued)
};
语句描述:使用Group By和Count得到每个CategoryID中断货产品的数量。
说明:先按CategoryID归类,取出CategoryID值和各个分类产品的断货数量。 Count函数里,使用了Lambda表达式,Lambda表达式中的p,代表这个组里的一个元素或对象,即某一个产品。
9.Where限制
var q =
from p in db.Products
group p by p.CategoryID into g
where g.Count() >= 10
select new {
g.Key,
ProductCount = g.Count()
};
语句描述:根据产品的―ID分组,查询产品数量大于10的ID和产品数量。这个示例在Group By子句后使用Where子句查找所有至少有10种产品的类别。
说明:在翻译成SQL语句时,在最外层嵌套了Where条件。
10.多列(Multiple Columns)
var categories =
from p in db.Products
group p by new
{
p.CategoryID,
p.SupplierID
}
into g
select new
{
g.Key,
g
};
语句描述:使用Group By按CategoryID和SupplierID将产品分组。
说明: 既按产品的分类,又按供应商分类。在by后面,new出来一个匿名类。这里,Key其实质是一个类的对象,Key包含两个Property:CategoryID、SupplierID。用g.Key.CategoryID可以遍历CategoryID的值。
11.表达式(Expression)
var categories =
from p in db.Products
group p by new { Criterion = p.UnitPrice > 10 } into g
select g;
语句描述:使用Group By返回两个产品序列。第一个序列包含单价大于10的产品。第二个序列包含单价小于或等于10的产品。
说明:按产品单价是否大于10分类。其结果分为两类,大于的是一类,小于及等于为另一类。
Exists/In/Any/All/Contains操作符
适用场景:用于判断集合中元素,进一步缩小范围。
Any
说明:用于判断集合中是否有元素满足某一条件;不延迟。(若条件为空,则集合只要不为空就返回True,否则为False)。有2种形式,分别为简单形式和带条件形式。
1.简单形式:
仅返回没有订单的客户:
var q =
from c in db.Customers
where !c.Orders.Any()
select c;
生成SQL语句为:
SELECT [t0].[CustomerID], [t0].[CompanyName], [t0].[ContactName],
[t0].[ContactTitle], [t0].[Address], [t0].[City], [t0].[Region],
[t0].[PostalCode], [t0].[Country], [t0].[Phone], [t0].[Fax]
FROM [dbo].[Customers] AS [t0]
WHERE NOT (EXISTS(
SELECT NULL AS [EMPTY] FROM [dbo].[Orders] AS [t1]
WHERE [t1].[CustomerID] = [t0].[CustomerID]
))
2.带条件形式:
仅返回至少有一种产品断货的类别:
var q =
from c in db.Categories
where c.Products.Any(p => p.Discontinued)
select c;
生成SQL语句为:
SELECT [t0].[CategoryID], [t0].[CategoryName], [t0].[Description],
[t0].[Picture] FROM [dbo].[Categories] AS [t0]
WHERE EXISTS(
SELECT NULL AS [EMPTY] FROM [dbo].[Products] AS [t1]
WHERE ([t1].[Discontinued] = 1) AND
([t1].[CategoryID] = [t0].[CategoryID])
)
All
说明:用于判断集合中所有元素是否都满足某一条件;不延迟
1.带条件形式
var q =
from c in db.Customers
where c.Orders.All(o => o.ShipCity == c.City)
select c;
语句描述:这个例子返回所有订单都运往其所在城市的客户或未下订单的客户。
Contains
说明:用于判断集合中是否包含有某一元素;不延迟。它是对两个序列进行连接操作的。
string[] customerID_Set =
new string[] { "AROUT", "BOLID", "FISSA" };
var q = (
from o in db.Orders
where customerID_Set.Contains(o.CustomerID)
select o).ToList();
语句描述:查找"AROUT", "BOLID" 和 "FISSA" 这三个客户的订单。 先定义了一个数组,在LINQ to SQL中使用Contains,数组中包含了所有的CustomerID,即返回结果中,所有的CustomerID都在这个集合内。也就是in。 你也可以把数组的定义放在LINQ to SQL语句里。比如:
var q = (
from o in db.Orders
where (
new string[] { "AROUT", "BOLID", "FISSA" })
.Contains(o.CustomerID)
select o).ToList();
Not Contains则取反:
var q = (
from o in db.Orders
where !(
new string[] { "AROUT", "BOLID", "FISSA" })
.Contains(o.CustomerID)
select o).ToList();
1.包含一个对象:
var order = (from o in db.Orders
where o.OrderID == 10248
select o).First();
var q = db.Customers.Where(p => p.Orders.Contains(order)).ToList();
foreach (var cust in q)
{
foreach (var ord in cust.Orders)
{
//do something
}
}
语句描述:这个例子使用Contain查找哪个客户包含OrderID为10248的订单。
2.包含多个值:
string[] cities =
new string[] { "Seattle", "London", "Vancouver", "Paris" };
var q = db.Customers.Where(p=>cities.Contains(p.City)).ToList();
语句描述:这个例子使用Contains查找其所在城市为西雅图、伦敦、巴黎或温哥华的客户。
总结一下这篇我们说明了以下语句:
| Group By/Having | 分组数据;延迟 |
| Any | 用于判断集合中是否有元素满足某一条件;不延迟 |
| All | 用于判断集合中所有元素是否都满足某一条件;不延迟 |
| Contains | 用于判断集合中是否包含有某一元素;不延迟 |
本系列链接:LINQ体验系列文章导航
LINQ推荐资源
LINQ专题:http://kb.cnblogs.com/zt/linq/ 关于LINQ方方面面的入门、进阶、深入的文章。
LINQ小组:http://space.cnblogs.com/group/linq/ 学习中遇到什么问题或者疑问提问的好地方。
自从有了IP数据库这种东西,QQ外挂的显示IP功能也随之而生,本人见识颇窄,是否还有其他应用不得而知,不过,IP数据库确实是个不错的东西。如今网络上最流行的IP数据库我想应该是纯真版的(说错了也不要扁我),迄今为止其IP记录条数已经接近30000,对于有些IP甚至能精确到楼层,不亦快哉。2004年4、5月间,正逢LumaQQ破土动工,为了加上这个人人都喜欢,但是好像人人都不知道为什么喜欢的显IP功能,我也采用了纯真版IP数据库,它的优点是记录多,查询速度快,它只用一个文件QQWry.dat就包含了所有记录,方便嵌入到其他程序中,也方便升级。
基本结构
QQWry.dat文件在结构上分为3块:文件头,记录区,索引区。一般我们要查找IP时,先在索引区查找记录偏移,然后再到记录区读出信息。由于记录区的记录是不定长的,所以直接在记录区中搜索是不可能的。由于记录数比较多,如果我们遍历索引区也会是有点慢的,一般来说,我们可以用二分查找法搜索索引区,其速度比遍历索引区快若干数量级。图1是QQWry.dat的文件结构图。

图1. QQWry.dat文件结构
要注意的是,QQWry.dat里面全部采用了little-endian字节序
一. 了解文件头
QQWry.dat的文件头只有8个字节,其结构非常简单,首四个字节是第一条索引的绝对偏移,后四个字节是最后一条索引的绝对偏移。
二. 了解记录区
每条IP记录都由国家和地区名组成,国家地区在这里并不是太确切,因为可能会查出来“清华大学计算机系”之类的,这里清华大学就成了国家名了,所以这个国家地区名和IP数据库制作的时候有关系。所以记录的格式有点像QName,有一个全局部分和局部部分组成,我们这里还是沿用国家名和地区名的说法。
于是我们想象着一条记录的格式应该是: [IP地址][国家名][地区名],当然,这个没有什么问题,但是这只是最简单的情况。很显然,国家名和地区名可能会有很多的重复,如果每条记录都保存一个完整的名称拷贝是非常不理想的,所以我们就需要重定向以节省空间。所以为了得到一个国家名或者地区名,我们就有了两个可能:第一就是直接的字符串表示的国家名,第二就是一个4字节的结构,第一个字节表明了重定向的模式,后面3个字节是国家名或者地区名的实际偏移位置。对于国家名来说,情况还可能更复杂些,因为这样的重定向最多可能有两次。
那么什么是重定向模式?根据上面所说,一条记录的格式是[IP地址][国家记录][地区记录],如果国家记录是重定向的话,那么地区记录是有可能没有的,于是就有了两种情况,我管他叫做模式1和模式2。我们对这些格式的情况举图说明:

图2. IP记录的最简单形式
图2表示了最简单的IP记录格式,我想没有什么可以解释的

图3. 重定向模式1
图3演示了重定向模式1的情况。我们看到在模式1的情况下,地区记录也跟着国家记录走了,在IP地址之后只剩下了国家记录的4字节,后面3个字节构成了一个指针,指向了实际的国家名,然后又跟着地址名。模式1的标识字节是0x01。

图4. 重定向模式2
图4演示了重定向模式2的情况。我们看到了在模式2的情况下(其标识字节是0x02),地区记录没有跟着国家记录走,因此在国家记录之后4个字节之后还是有地区记录。我想你已经明白了模式1和模式2的区别,即:模式1的国家记录后面不会再有地区记录,模式2的国家记录后会有地区记录。下面我们来看一下更复杂的情况。

图5. 混和情况1
图5演示了当国家记录为模式1的时候可能出现的更复杂情况,在这种情况下,重定向指向的位置仍然是个重定向,不过第二次重定向为模式2。大家不用担心,没有模式3了,这个重定向也最多只有两次,并且如果发生了第二次重定向,则其一定为模式2,而且这种情况只会发生在国家记录上,对于地区记录,模式1和模式2是一样的,地区记录也不会发生2次重定向。不过,这个图还可以更复杂,如图7:

图6. 混和情况2
图6是模式1下最复杂的混和情况,不过我想应该也很好理解,只不过地区记录也来重定向而已,有一点我要提醒你,如果重定向的地址是0,则表示未知的地区名。
所以我们总结如下:一条IP记录由[IP地址][国家记录][地区记录]组成,对于国家记录,可以有三种表示方式:字符串形式,重定向模式1和重定向模式2。对于地区记录,可以有两种表示方式:字符串形式和重定向,另外有一条规则:重定向模式1的国家记录后不能跟地区记录。按照这个总结,在这些方式中合理组合,就构成了IP记录的所有可能情况。
设计的理由
在我们继续去了解索引区的结构之前,我们先来了解一下为何记录区的结构要如此设计。我想你可能想到了答案:字符串重用。没错,在这种结构下,对于一个国家名和地区名,我只需要保存其一次就可以了。我们举例说明,为了表示方便,我们用小写字母代表IP记录,C表示国家名,A表示地区名:
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2, A1 = A2,那么我们就可以使用图3显示的结构来实现重用
有三条记录a(C1, A1), b(C2, A2), c(C3, A3),如果C1 = C2, A2 = A3,现在我们想存储记录b,那么我们可以用图6的结构来实现重用
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2,现在我们想存储记录b,那么我们可以采用模式2表示C2,用字符串表示A2
你可以举出更多的情况,你也会发现在这种结构下,不同的字符串只需要存储一次。
了解索引区
在"了解文件头"部分,我们说明了文件头实际上是两个指针,分别指向了第一条索引和最后一条索引的绝对偏移。如图8所示:

图8. 文件头指向索引区图示
实在是很简单,不是吗?从文件头你就可以定位到索引区,然后你就可以开始搜索IP了!每条索引长度为7个字节,前4个字节是起始IP地址,后三个字节就指向了IP记录。这里有些概念需要说明一下,什么是起始IP,那么有没有结束IP?假设有这么一条记录:166.111.0.0 - 166.111.255.255,那么166.111.0.0就是起始IP,166.111.255.255就是结束IP,结束IP就是IP记录中的那头4个字节,这下你应该就清楚了吧。于是乎,每条索引配合一条记录,构成了一个IP范围,如果你要查找166.111.138.138所在的位置,你就会发现166.111.138.138落在了166.111.0.0- 166.111.255.255 这个范围内,那么你就可以顺着这条索引去读取国家和地区名了。那么我们给出一个最详细的图解吧:

图9. 文件详细结构
现在一切都清楚了是不是?也许还有一点你不清楚,QQWry.dat的版本信息存在哪里呢? 答案是:最后一条IP记录实际上就是版本信息,最后一条记录显示出来就是这样:255.255.255.0255.255.255.255 纯真网络 2004年6月25日IP数据。OK,到现在你应该全部清楚了。
Demo
下一步:我给出一个读取IP记录的程序片断,此片断摘录自LumaQQ源文件edu.tsinghua.lumaqq.IPSeeker.java,如果你有兴趣,可以下载源代码详细看看。
/** *//**
* 给定一个ip国家地区记录的偏移,返回一个IPLocation结构
* @param offset 国家记录的起始偏移
* @return IPLocation对象
*/
private IPLocation getIPLocation(long offset) {
try {
// 跳过4字节ip
ipFile.seek(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = ipFile.readByte();
if(b == REDIRECT_MODE_1) {
// 读取国家偏移
long countryOffset = readLong3();
// 跳转至偏移处
ipFile.seek(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = ipFile.readByte();
if(b == REDIRECT_MODE_2) {
loc.country = readString(readLong3());
ipFile.seek(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(ipFile.getFilePointer());
} else if(b == REDIRECT_MODE_2) {
loc.country = readString(readLong3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(ipFile.getFilePointer() - 1);
loc.area = readArea(ipFile.getFilePointer());
}
return loc;
} catch (IOException e) {
return null;
}
}
/** *//**
* 从offset偏移开始解析后面的字节,读出一个地区名
* @param offset 地区记录的起始偏移
* @return 地区名字符串
* @throws IOException 地区名字符串
*/
private String readArea(long offset) throws IOException {
ipFile.seek(offset);
byte b = ipFile.readByte();
if(b == REDIRECT_MODE_1 || b == REDIRECT_MODE_2) {
long areaOffset = readLong3(offset + 1);
if(areaOffset == 0)
return LumaQQ.getString("unknown.area");
else
return readString(areaOffset);
} else
return readString(offset);
}
/** *//**
* 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法
* 用了这么一个函数来做转换
* @param offset 整数的起始偏移
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/** *//**
* 从当前位置读取3个字节转换成long
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3() {
long ret = 0;
try {
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/** *//**
* 从offset偏移处读取一个以0结束的字符串
* @param offset 字符串起始偏移
* @return 读取的字符串,出错返回空字符串
*/
private String readString(long offset) {
try {
ipFile.seek(offset);
int i;
for(i = 0, buf[i] = ipFile.readByte(); buf[i] != 0; buf[++i] = ipFile.readByte());
if(i != 0)
return Utils.getString(buf, 0, i, "GBK");
} catch (IOException e) {
log.error(e.getMessage());
}
return "";
}代码并不复杂,getIPLocation是主要方法,它检查国家记录格式,并针对字符串形式,模式1,模式2采用不同的代码,readArea则相对简单,因为只有字符串和重定向两种情况需要处理。
总结
纯真IP数据库的结构使得查找IP简单迅速,不过你想要编辑它却是比较麻烦的,我想应该需要专门的工具来生成QQWry.dat文件,由于其文件格式的限制,你要直接添加IP记录就不容易了。不过,能查到IP已经很开心了,希望纯真记录越来越多~。
LumaQQ is a Java QQ client which has a reusablepure Java core and SWT-based GUI