

去年,我们分享了《40个良好用户界面Tips》,对设计师来说确实很有帮助,今年,Goodui.org已经更新至71条,这些原则都是由Goodui官方精心整理,认为这些都是非常重要的设计要点,所以对于设计师来说,建议学习一下。
01 尝试使用一列的布局替代多列布局

02 给用户一些小的利益,别看上去那么赤裸裸
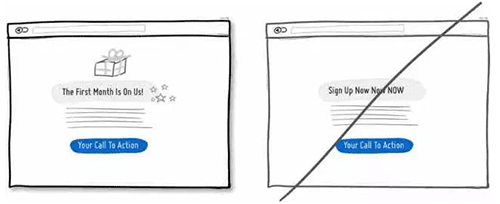
03 合并相似的功能

04 尝试展示来自用户的赞扬,而不是自我表扬

05 重复核心行动点

06 统一视觉规范,提升可识别性

07 尝试使用推荐的口吻,而不是让用户感觉面对一台冷冰冰的机器
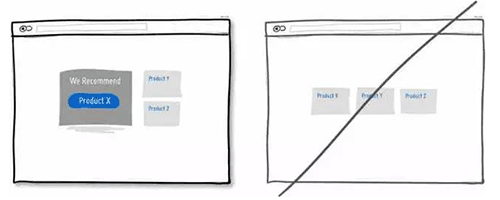
08 给用户吃「后悔药」的机会
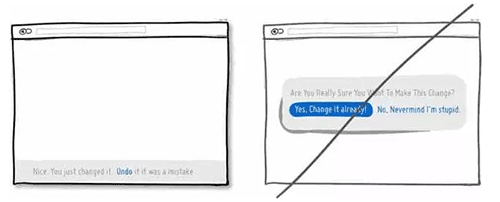
09 告诉用户产品适用的人群,而不是人人都通用

10 将文案写得更加的直接,而不是一堆废话
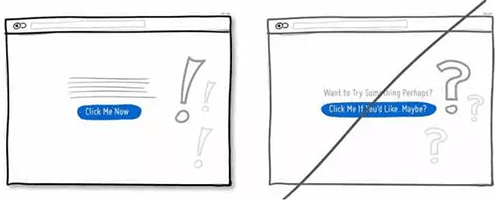
11 增强主行动点的视觉冲击力,提升它在页面中的可对比性
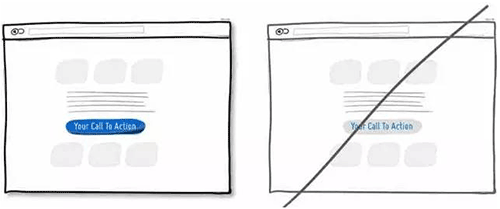
12 让用户知道你从哪儿来更易于拉近与用户的关系
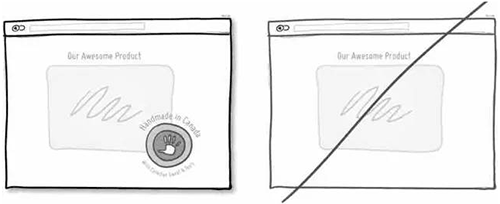
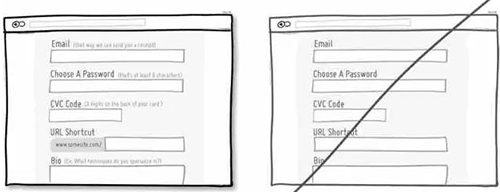
13 将表单做的简单点,确保用户在抓狂之前能进入下一步

14 尽量将用户需要选择的信息展示出来而不是藏起来

15 页面的排版需要考虑用户是否会漏掉底部信息

16 如果页面的底部有需要关注的行动点,别让文中过多的外链带走了用户

17 确保用户知道自己目前的状态

18 将利益点融合在行动点中,增强用户的点击欲望
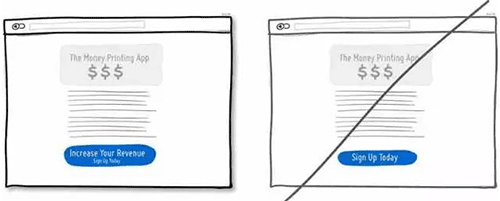
19 将行动点与当前信息结合起来

20 将简要的表单合并到页面中,减少调整页面带来的用户流失

21 适当的增加延迟动效,让用户感知到页面的变化
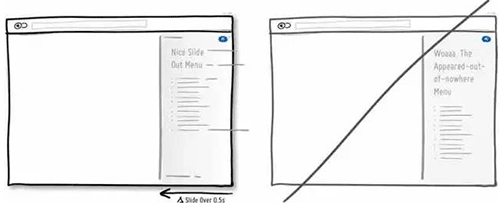
22 让新用户从尝试产品入手,而不是一来就面对冷冰冰的注册表单
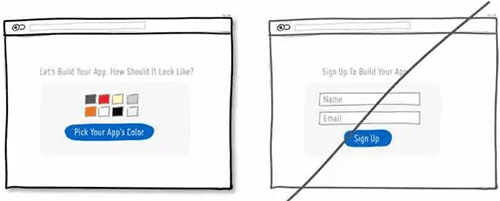
23 减少使用线框,这会过多的吸引用户注意力,而且会让页面看上去透不过气
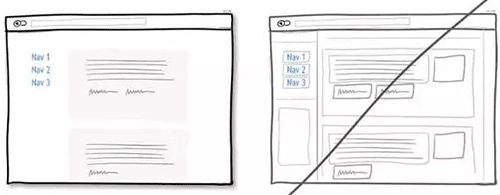
24 给用户推销你能给他带来的利益,而不是功能

25 一定要注意0结果页面的设计,这也是引导用户的好地方
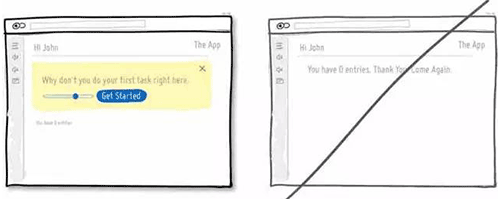
26 给用户选择退出的权利,特别是邮件订阅

27 注意界面元素的一致性,降低用户学习成本

28 给下拉框增加一些预设值,降低用户填写成本
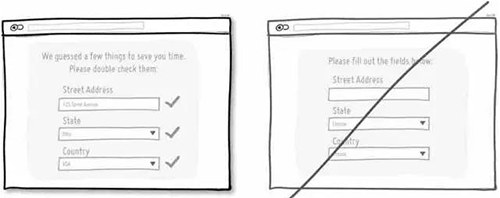
29 延续用户日常的使用习惯,而不是重新创造

30 尝试告诉用做些事情降低自己的损失,而不是提升收益
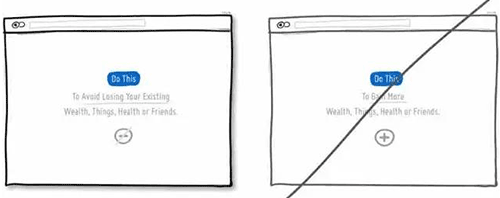
31 提升页面的视觉层次,增强可阅读性

32 将同类的操作合并在一起,降低用户的认知成本
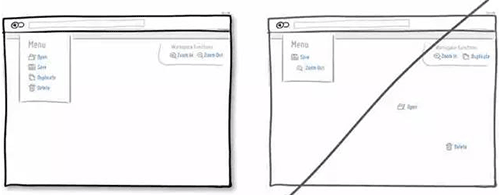
33 表单及时校验,而不是统一提交后在告诉用户填错了

34 尝试将表单输入变得更加宽容,让用户的填写更加简单
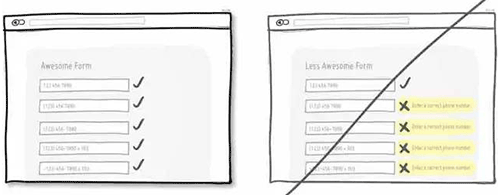
35 通过时间增强紧迫感
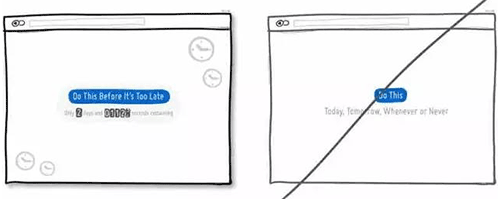
36 提供用户可预见性的操作,降低用户的心理成本
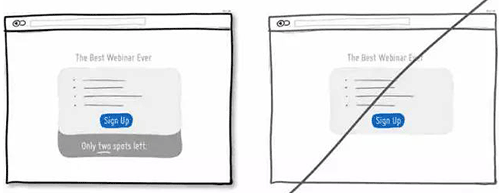
37 尽可能的帮助用户选择,而不是让用户想破脑袋
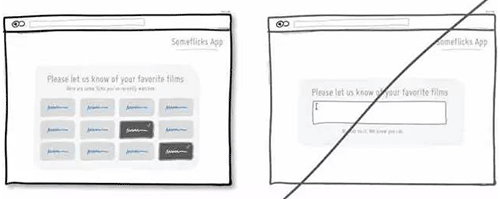
38 尽可能将操作区域放大,降低用户操作成本
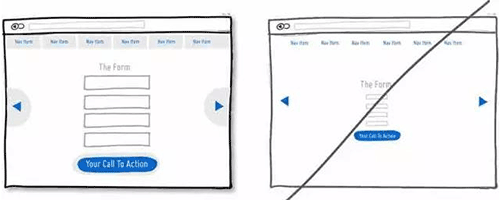
39 页面加载速度很重要,尽可能让用户感受到你的网站速度很快
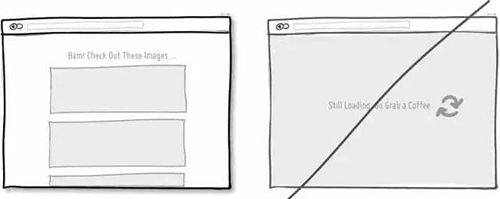
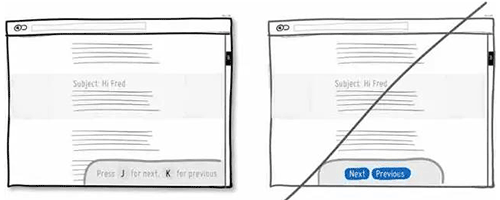
40 如果可以,增加键盘快捷键,提升操作效率
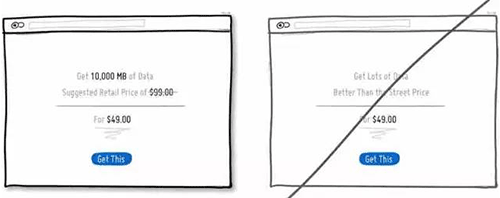
41 尝试通过对比来让用户感知到性价比
42 尝试对进度条进行「设计」来降低用户等待的焦虑

43 根据用户选择逐步展示信息,降低无效信息对用户的干扰

44 有时候较小的承诺比「夸海口」会更容易让用户信服

45 尝试将提示信息弱化,减少对用户操作的干扰
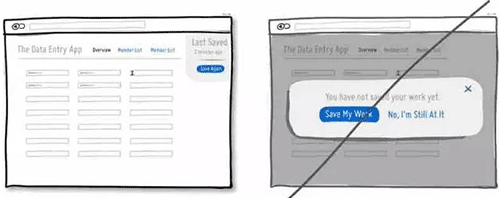
46 尽量通过系统的功能来简化用户的操作
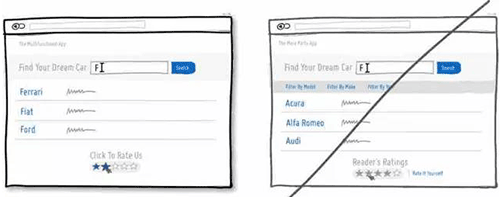
47 用文本配合图标来降低用户的认知成本

48 用更自然的语言代替冷冰冰的机器

49 放出一些摘要信息来帮助用户识别是否需要进一步了解
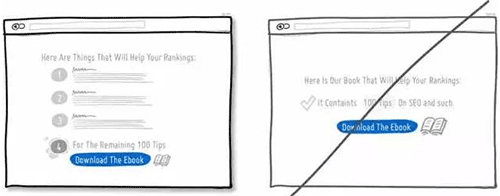
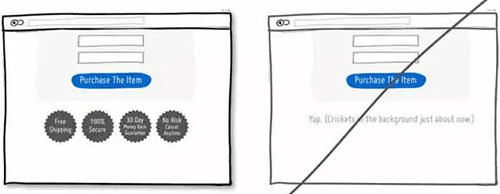
50 在关键的页面增加用户权益信息,增强用户进一步操作的信心
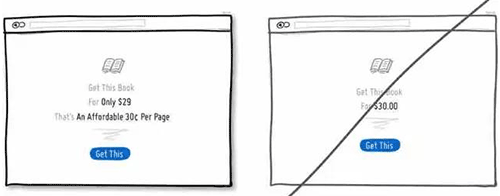
51 将价格进行换算,让用户感觉这很便宜
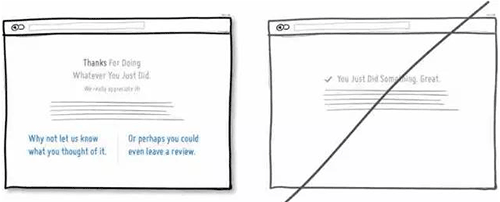
52 记得在成功页面感谢用户
53 将数字转化成易于用户阅读的形式,而不是冷冰冰的机器语言
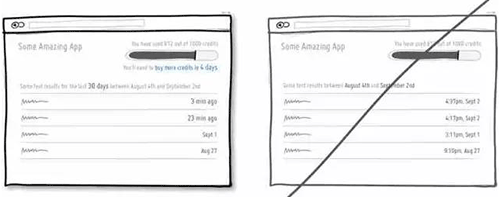
54 告诉用户选择的权利和自由「诱惑力」
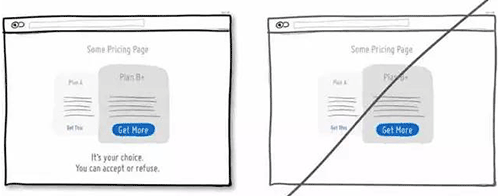
55 尝试让语言更具「诱惑力」
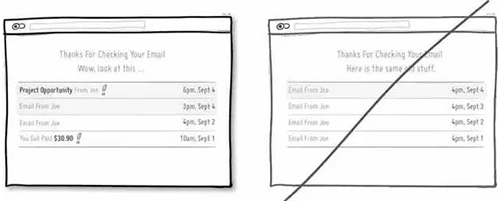
56 通过设计引导用户的注意力
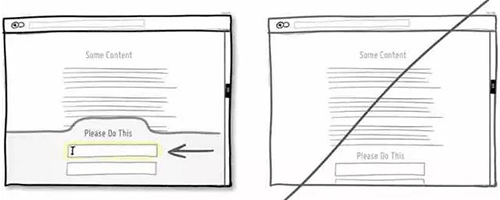
57 通过友好的对比来展示产品,为用户做决定提供帮助

58 通过任务机制来提升用户的满足感
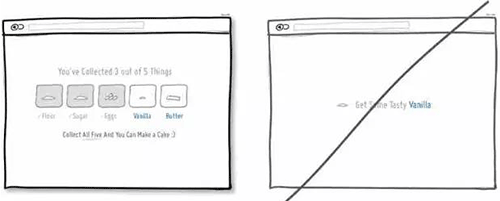
59 让用户了解接下来将要发生什么事情

60 尝试用更幽默一些的语言文案

61 任何操作之后都要给出反馈,让用户知道操作已经生效

62 注意动效的真实使用情况(Amazon 的类目菜单就是一个很好的例子)

63 注意排版的,不要让信息过于拥挤
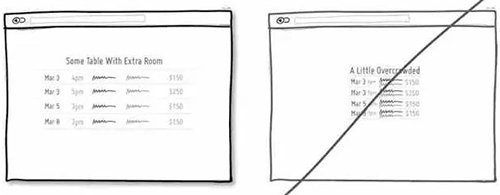
64 尝试用讲故事的方式来传递信息,增强用户的代入感

65 尽量给用户展示真实的信息,不要欺骗

66 随着用户的不断熟悉简化界面
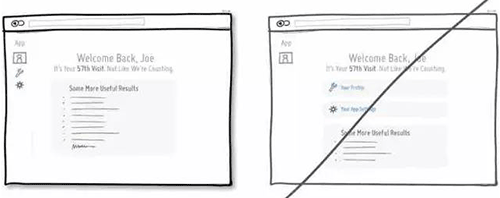
67 试着用用户的口吻展示信息
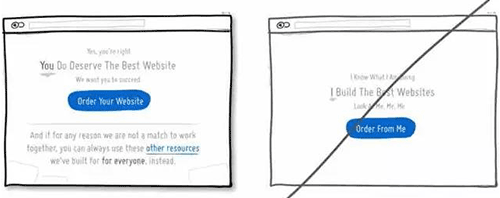
68 在表单中增加一些提示信息,减少错误的几率
69 用简单的文案传递核心关注的信息,少一些废话

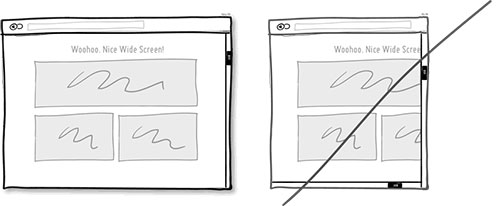
70 尝试使用响应式布局
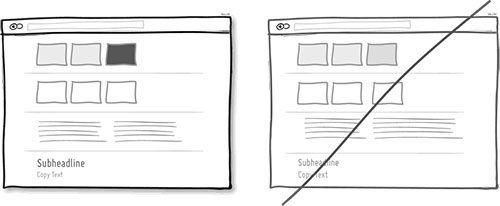
71 视觉表达要清晰,而不是模棱两可
这71条设计原则虽然针对 Web 设计,但有些部分在移动产品设计中同样有效。翻译过程只保留了图片和标题,更多详细内容可以访问 GoodUI 官网:
http://goodui.org/
Apple’s newest devices feature the Retina Display, a screen that packs double as many pixels into the same space as older devices. For designers this immediately brings up the question, “What can I do to make my content look outstanding on these new iPads and iPhones?”. First there are a few tough questions to consider, but then this guide will help you get started making your websites and web apps look amazingly sharp with Retina images!

Things to Consider When Adding Retina Images
The main issue with adding retina images is that the images are double as large and will take up extra bandwidth (this won’t be an issue for actual iOS apps, but this guide is covering web sites & web apps only). If your site is mostly used on-the-go over a 3G network it may not be wise to make all your graphics high-definition, but maybe choose only a select few important images. If you’re creating something that will be used more often on a WI-FI connection or have an application that is deserving of the extra wait for hi-res graphics these steps below will help you target only hi-res capable devices.
Simple Retina Images
The basic concept of a Retina image is that your taking a larger image, with double the amount of pixels that your image will be displayed at (e.g 200 x 200 pixels), and setting the image to fill half of that space (100 x 100 pixels). This can be done manually by setting the height and width in HTML to half the size of your image file.
<img src="my200x200image.jpg" width="100" height="100">
If you’d like to do something more advanced keep reading below for how you can apply this technique using scripting.
Creating Retina Icons for Your Website
When users add your website or web app to their homescreen it will be represented by an icon. These sizes for regular and Retina icons (from Apple) are as follows:
![]()
| iPhone | 57 x 57 |
|---|---|
| Retina iPhone | 114 x 114 |
| iPad | 72 x 72 |
| Retina iPad | 144 x 144 |
For each of these images you create you can link them in the head of your document like this (if you want the device to add the round corners remove -precomposed):
<link href="touch-icon-iphone.png" rel="apple-touch-icon-precomposed" />
<link href="touch-icon-ipad.png" rel="apple-touch-icon-precomposed" sizes="72x72" />
<link href="touch-icon-iphone4.png" rel="apple-touch-icon-precomposed" sizes="114x114" />
<link href="touch-icon-ipad3.png" rel="apple-touch-icon-precomposed" sizes="144x144" />
If the correct size isn’t specified the device will use the smallest icon that is larger than the recommended size (i.e. if you left out the 114px the iPhone 4 would use the 144px icon).
Retina Background Images
Background images that are specified in your CSS can be swapped out using media queries. You’ll first want to generate two versions of each image. For example ‘bgPattern.png’ at 100px x 100px and ‘bgPattern@2x.png’ at 200px x 200px. It will be useful to have a standard naming convention such as adding @2x for these retina images. To add the new @2x image to your site simply add in the media query below (You can add any additional styles that have background images within the braces of the same media query):
.repeatingPattern {
background: url(../images/bgPattern.png) repeat;
background-size: 100px 100px;
}
@media only screen and (-webkit-min-device-pixel-ratio: 2) {
.repeatingPattern {
background: url(../images/bgPattern@2x.png) repeat;
}
}
JavaScript for Retina Image Replacement
For your retina images that aren’t backgrounds the best option seems to be either creating graphics with CSS, using SVG, or replacing your images with JavaScript. Just like the background images, you’ll want to create a normal image and one ‘@2x’ image. Then with JavaScript you can detect if the pixel ratio of the browser is 2x, just like you did with the media query:
if (window.devicePixelRatio == 2) {
//Replace your img src with the new retina image
}
If you’re using jQuery you could quickly replace all your images like this very basic example below. It’s a good idea to add a class to identify the images with hi-res versions so you don’t replace any others by mistake. I’ve added a class=”hires” for this example. Also make sure you have the standard (non-retina) image height and width set in the HTML:
<img class="hires" alt="" src="search.png" width="100" height="100" />
<script type="text/javascript">
$(function () {
if (window.devicePixelRatio == 2) {
var images = $("img.hires");
// loop through the images and make them hi-res
for(var i = 0; i < images.length; i++) {
// create new image name
var imageType = images[i].src.substr(-4);
var imageName = images[i].src.substr(0, images[i].src.length - 4);
imageName += "@2x" + imageType;
//rename image
images[i].src = imageName;
}
}
});
</script>
Server-Side Retina Images
If you’d like to implement a server-side retina image solution, I recommend checking out Jeremy Worboys’ Retina Images (which he also posted in the comments below). His solution uses PHP code to determine which image should be served. The benefit of this solution is that it doesn’t have to replace the small image with the retina one so you’re using less bandwidth, especially if you have lots of images that you’re replacing.
Website Optimization for Retina Displays
If you’re looking for additional information on creating Retina images, I’ve recently had a short book published called Website Optimization for Retina Displays that covers a range of related topics. It contains some of what is above, but also includes samples for many different situations for adding Retina images. It explains the basics of creating Retina images, backgrounds, sprites, and borders. Then it talks about using media queries, creating graphics with CSS, embedding fonts, creating app icons, and more tips for creating Retina websites.
离 VS2008 发布已经过去多年了,最近有个项目必须用到,我觉得还是有必要把它的一些信息写下来,特别是下载和注册方式,方便日后查看。我关心的当然是 Team Suite 版本。
zh-hans_visual_studio_team_system_2008_team_suite_trial_x86_dvd_x14-29243.iso 是 90 天试用版 (需要序列号,网上有很多)
这里推荐 MSDN 版(无需序列号,没有使用期限):
Visual Studio Team System 2008 Team Suite (x86) - DVD (Chinese-Simplified)
文件名:zh-hans_visual_studio_team_system_2008_team_suite_x86_dvd_x14-26452.isoSHA1:12d905fb0c6fd02b33cceaad1e5905929f413c0a
有了用这个 SHA1 去网上搜一下,就可以看到一大堆下载地址,譬如:
ed2k://|file|zh-Hans_visual_studio_team_system_2008_team_suite_x86_dvd_X14-26452.iso|4663904256|8E2D6430D819328940B9BF83568589FA|/
SP1 补丁包:
Visual Studio 2008 Service Pack 1 (x86, x64 WoW) - DVD (Chinese-Simplified)
文件名:zh-hans_visual_studio_2008_service_pack_1_x86_dvd_x15-12981.iso
SHA1:8C3EA92CBC60CECB30B6262DB475BDE1E2620B36
ed2k://|file|zh-hans_visual_studio_2008_service_pack_1_x86_dvd_x15-12981.iso|941703168|E1647161AA5CA4567B787A5606D2A065|/
一、添加引用 using System.Web.SessionState;
二、实现接口 public class Handler : IHttpHandler, IRequiresSessionState { }
三、使用方法 HttpContext.Current.Session["xxx"] = value;

做网页的朋友应该都知道常用的几个HTML转义符,如“ ”表示空格,“>”表示“>”等,但是有时候我们为了网页的文字不被搜索引擎收录,比如评论信息,这时可以用同样的方法去转义汉字等各种字符,一般格式为 "&#"+ASCII+";",如“中华人民共和国”可以转义为“中华人民共和国”。
在C#中可以这样来实现:
private string htmlEscape(string s)
{
StringBuilder sb = new StringBuilder();
foreach (char c in s)
{
sb.Append("&#" + (int)c + ";");
}
return sb.ToString();
}自从有了IP数据库这种东西,QQ外挂的显示IP功能也随之而生,本人见识颇窄,是否还有其他应用不得而知,不过,IP数据库确实是个不错的东西。如今网络上最流行的IP数据库我想应该是纯真版的(说错了也不要扁我),迄今为止其IP记录条数已经接近30000,对于有些IP甚至能精确到楼层,不亦快哉。2004年4、5月间,正逢LumaQQ破土动工,为了加上这个人人都喜欢,但是好像人人都不知道为什么喜欢的显IP功能,我也采用了纯真版IP数据库,它的优点是记录多,查询速度快,它只用一个文件QQWry.dat就包含了所有记录,方便嵌入到其他程序中,也方便升级。
基本结构
QQWry.dat文件在结构上分为3块:文件头,记录区,索引区。一般我们要查找IP时,先在索引区查找记录偏移,然后再到记录区读出信息。由于记录区的记录是不定长的,所以直接在记录区中搜索是不可能的。由于记录数比较多,如果我们遍历索引区也会是有点慢的,一般来说,我们可以用二分查找法搜索索引区,其速度比遍历索引区快若干数量级。图1是QQWry.dat的文件结构图。

图1. QQWry.dat文件结构
要注意的是,QQWry.dat里面全部采用了little-endian字节序
一. 了解文件头
QQWry.dat的文件头只有8个字节,其结构非常简单,首四个字节是第一条索引的绝对偏移,后四个字节是最后一条索引的绝对偏移。
二. 了解记录区
每条IP记录都由国家和地区名组成,国家地区在这里并不是太确切,因为可能会查出来“清华大学计算机系”之类的,这里清华大学就成了国家名了,所以这个国家地区名和IP数据库制作的时候有关系。所以记录的格式有点像QName,有一个全局部分和局部部分组成,我们这里还是沿用国家名和地区名的说法。
于是我们想象着一条记录的格式应该是: [IP地址][国家名][地区名],当然,这个没有什么问题,但是这只是最简单的情况。很显然,国家名和地区名可能会有很多的重复,如果每条记录都保存一个完整的名称拷贝是非常不理想的,所以我们就需要重定向以节省空间。所以为了得到一个国家名或者地区名,我们就有了两个可能:第一就是直接的字符串表示的国家名,第二就是一个4字节的结构,第一个字节表明了重定向的模式,后面3个字节是国家名或者地区名的实际偏移位置。对于国家名来说,情况还可能更复杂些,因为这样的重定向最多可能有两次。
那么什么是重定向模式?根据上面所说,一条记录的格式是[IP地址][国家记录][地区记录],如果国家记录是重定向的话,那么地区记录是有可能没有的,于是就有了两种情况,我管他叫做模式1和模式2。我们对这些格式的情况举图说明:

图2. IP记录的最简单形式
图2表示了最简单的IP记录格式,我想没有什么可以解释的

图3. 重定向模式1
图3演示了重定向模式1的情况。我们看到在模式1的情况下,地区记录也跟着国家记录走了,在IP地址之后只剩下了国家记录的4字节,后面3个字节构成了一个指针,指向了实际的国家名,然后又跟着地址名。模式1的标识字节是0x01。

图4. 重定向模式2
图4演示了重定向模式2的情况。我们看到了在模式2的情况下(其标识字节是0x02),地区记录没有跟着国家记录走,因此在国家记录之后4个字节之后还是有地区记录。我想你已经明白了模式1和模式2的区别,即:模式1的国家记录后面不会再有地区记录,模式2的国家记录后会有地区记录。下面我们来看一下更复杂的情况。

图5. 混和情况1
图5演示了当国家记录为模式1的时候可能出现的更复杂情况,在这种情况下,重定向指向的位置仍然是个重定向,不过第二次重定向为模式2。大家不用担心,没有模式3了,这个重定向也最多只有两次,并且如果发生了第二次重定向,则其一定为模式2,而且这种情况只会发生在国家记录上,对于地区记录,模式1和模式2是一样的,地区记录也不会发生2次重定向。不过,这个图还可以更复杂,如图7:

图6. 混和情况2
图6是模式1下最复杂的混和情况,不过我想应该也很好理解,只不过地区记录也来重定向而已,有一点我要提醒你,如果重定向的地址是0,则表示未知的地区名。
所以我们总结如下:一条IP记录由[IP地址][国家记录][地区记录]组成,对于国家记录,可以有三种表示方式:字符串形式,重定向模式1和重定向模式2。对于地区记录,可以有两种表示方式:字符串形式和重定向,另外有一条规则:重定向模式1的国家记录后不能跟地区记录。按照这个总结,在这些方式中合理组合,就构成了IP记录的所有可能情况。
设计的理由
在我们继续去了解索引区的结构之前,我们先来了解一下为何记录区的结构要如此设计。我想你可能想到了答案:字符串重用。没错,在这种结构下,对于一个国家名和地区名,我只需要保存其一次就可以了。我们举例说明,为了表示方便,我们用小写字母代表IP记录,C表示国家名,A表示地区名:
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2, A1 = A2,那么我们就可以使用图3显示的结构来实现重用
有三条记录a(C1, A1), b(C2, A2), c(C3, A3),如果C1 = C2, A2 = A3,现在我们想存储记录b,那么我们可以用图6的结构来实现重用
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2,现在我们想存储记录b,那么我们可以采用模式2表示C2,用字符串表示A2
你可以举出更多的情况,你也会发现在这种结构下,不同的字符串只需要存储一次。
了解索引区
在"了解文件头"部分,我们说明了文件头实际上是两个指针,分别指向了第一条索引和最后一条索引的绝对偏移。如图8所示:

图8. 文件头指向索引区图示
实在是很简单,不是吗?从文件头你就可以定位到索引区,然后你就可以开始搜索IP了!每条索引长度为7个字节,前4个字节是起始IP地址,后三个字节就指向了IP记录。这里有些概念需要说明一下,什么是起始IP,那么有没有结束IP?假设有这么一条记录:166.111.0.0 - 166.111.255.255,那么166.111.0.0就是起始IP,166.111.255.255就是结束IP,结束IP就是IP记录中的那头4个字节,这下你应该就清楚了吧。于是乎,每条索引配合一条记录,构成了一个IP范围,如果你要查找166.111.138.138所在的位置,你就会发现166.111.138.138落在了166.111.0.0- 166.111.255.255 这个范围内,那么你就可以顺着这条索引去读取国家和地区名了。那么我们给出一个最详细的图解吧:

图9. 文件详细结构
现在一切都清楚了是不是?也许还有一点你不清楚,QQWry.dat的版本信息存在哪里呢? 答案是:最后一条IP记录实际上就是版本信息,最后一条记录显示出来就是这样:255.255.255.0255.255.255.255 纯真网络 2004年6月25日IP数据。OK,到现在你应该全部清楚了。
Demo
下一步:我给出一个读取IP记录的程序片断,此片断摘录自LumaQQ源文件edu.tsinghua.lumaqq.IPSeeker.java,如果你有兴趣,可以下载源代码详细看看。
/** *//**
* 给定一个ip国家地区记录的偏移,返回一个IPLocation结构
* @param offset 国家记录的起始偏移
* @return IPLocation对象
*/
private IPLocation getIPLocation(long offset) {
try {
// 跳过4字节ip
ipFile.seek(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = ipFile.readByte();
if(b == REDIRECT_MODE_1) {
// 读取国家偏移
long countryOffset = readLong3();
// 跳转至偏移处
ipFile.seek(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = ipFile.readByte();
if(b == REDIRECT_MODE_2) {
loc.country = readString(readLong3());
ipFile.seek(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(ipFile.getFilePointer());
} else if(b == REDIRECT_MODE_2) {
loc.country = readString(readLong3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(ipFile.getFilePointer() - 1);
loc.area = readArea(ipFile.getFilePointer());
}
return loc;
} catch (IOException e) {
return null;
}
}
/** *//**
* 从offset偏移开始解析后面的字节,读出一个地区名
* @param offset 地区记录的起始偏移
* @return 地区名字符串
* @throws IOException 地区名字符串
*/
private String readArea(long offset) throws IOException {
ipFile.seek(offset);
byte b = ipFile.readByte();
if(b == REDIRECT_MODE_1 || b == REDIRECT_MODE_2) {
long areaOffset = readLong3(offset + 1);
if(areaOffset == 0)
return LumaQQ.getString("unknown.area");
else
return readString(areaOffset);
} else
return readString(offset);
}
/** *//**
* 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法
* 用了这么一个函数来做转换
* @param offset 整数的起始偏移
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/** *//**
* 从当前位置读取3个字节转换成long
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3() {
long ret = 0;
try {
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/** *//**
* 从offset偏移处读取一个以0结束的字符串
* @param offset 字符串起始偏移
* @return 读取的字符串,出错返回空字符串
*/
private String readString(long offset) {
try {
ipFile.seek(offset);
int i;
for(i = 0, buf[i] = ipFile.readByte(); buf[i] != 0; buf[++i] = ipFile.readByte());
if(i != 0)
return Utils.getString(buf, 0, i, "GBK");
} catch (IOException e) {
log.error(e.getMessage());
}
return "";
}代码并不复杂,getIPLocation是主要方法,它检查国家记录格式,并针对字符串形式,模式1,模式2采用不同的代码,readArea则相对简单,因为只有字符串和重定向两种情况需要处理。
总结
纯真IP数据库的结构使得查找IP简单迅速,不过你想要编辑它却是比较麻烦的,我想应该需要专门的工具来生成QQWry.dat文件,由于其文件格式的限制,你要直接添加IP记录就不容易了。不过,能查到IP已经很开心了,希望纯真记录越来越多~。
LumaQQ is a Java QQ client which has a reusablepure Java core and SWT-based GUI
微软已经开始正式对系统更新的使用者强制检查其所使用的 XP系统是否为盗版的检查,若发现盗版,系统自动更新后,每次启动都提示"您可能是软件盗版的受害者",进入桌面后右下角启动栏里有一个五角星的图案.
相关报道:
即日起微软将启动「正版Windows客户权益独享计划1.0 」 (Windows Genuine Advantage 1.0 , WGA 1.0),用户进入下载中心必须验证是否正版软件,若为盗版软件则不能下载,但是自动更新(Automatic updates)不在此限,所有的用户都可以自动更新修补漏洞。用户在第一次进入Windows update、Microsoft update及Download Center网站进行下载时,将被要求参与WGA验证程序。客户须要下载一个ActiveX控制程序,此程序将自动验证用户计算机所使用的是否为正版 Windows软件。若通过验证,将会有一组Download Key储存在客户计算机中,作为将来进入微软网站进行下载动作时计算机自动辨识之用,微软表示,此验证流程不搜集任何可用来辨认或联络使用者的信息。验证流程已经改善并简化。验证程序将自动验证用户计算机所使用的是否为正版Windows软件,用户不再需键入25码的产品序号,就可以轻松的完成验证过程,大幅降低客户进行验证时的负担。换句话说使用盗版Windows操作系统的用户,将不能直接从下载中心下载Windows Media Player、Antispy等软件,但是依然可以透过自动更新来修补漏洞。
手工解决方法:
方法一:
1.IE => 工具=>Internet 选项 => 程序=> 管理加载项=>IE已经使用的加载项=>Windows Genuine Advantage Validation Tool=>禁用=>然后再上线更新,这样就不会验证了。此WGA(Windows Genuine Advantage Notifications)组件对应文件:legitchechcontrol.dll。WGA是反盗版自动更新验证ActiveX组件,这个正版检验程序植入系统后,会在每次系统启动时,透过网络回报讯息给微软的网站。没更新过的计算机里没有此组件,So..先去update下载此组件后再用此方法去停用此组件,以后即可自动更新了。
2、移除验证码:
计算机=>控制面板=>添加或删除程序=>Windows Installer 3.1(KB893803)=>删除=>重新下载更新档=>windows genuine advantage 不要勾选=>完成。保证不会再出现了(Windows Installer 3.1是修复windows installer安装错误或者提示无法修复MSI出错的微软官方补丁)
3.重启你的计算机,进入安全模式,登陆管理员帐号--保证你拥有进入Windows\system32以及Windows\system32\dllcache路径的权限。在这两个路径下均有一个名为WGATray.EXE的文件。你必须将两个路径下的WGATray.EXE均删除--这将阻止Windows在启动时弹出“盗版XP”气球。
在删除Windows\system32下的WGATray.EXE可能需要一点技巧:
步奏一:WGATray.EXE图标-->右键-->删除-->出现删除确认框后先不要按‘确定’按钮
步奏二:Ctrl+Alt+Del-->打开进程管理器-->找到WGATray.EXE-->删除-->出现删除确认框后先不要按‘确定’按钮
步奏三:先按打开进程管理器的删除确认键,然后用最快速度按步奏一的删除确认键。
步奏四:如果Windows\system32下的WGATray.EXE不会出现,代表操作成功。继续删除Windows\system32\dllcache下的WGATray.EXE。
4.进入注册表,进入
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\ Windows NT\CurrentVersion\Winlogon\Notify
删除其中的“WGALOGON”文件夹--这将Windows将无法加载任何有关WGA的DLL文件。
重启计算机,你将暂时告别微软正版增值计划的“骚扰”。
方法二:
在进入Window update 网页后选择「Express(快速)」或「Custom(自订)」按钮前,在 IE 地址栏输入:
void(window.g_sDisableWGACheck='all')
再按下ENTER后,再选取你要更新的方法"快速","自订"即可
此法可以用来破解微软反盗版的检查。系统就不会查你是用什么版本的WIN了
能保证系统更新还是很有必要的。系统更新的目的多数就是防止电脑病毒的需要。
对于使用VOL免激活版(上海政府、xx银行等)的用户,可以使用替换序列号的简单办法。因为目前尚有部分VOL序列号未被封,并且可以通过正版验证。
HCQ9D-TVCWX-X9QRG-J4B2Y-GR2TT (番茄花园版就是使用的这个序列号)
MRX3F-47B9T-2487J-KWKMF-RPWBY(工行版)
QC986-27D34-6M3TY-JJXP9-TBGMD(台湾交大学生版)
点击下载此文件
替换后请到C:\Documents and Settings\All Users\Application Data下删除Windows Genuine Advantage文件夹。以后即可通过正版验证。
如果XP是很老的破解版本(比如零售版的破解版本)用户,无法使用上述序列号,请下载RemoveWGA工具。RemoveWGA 是一个专门用来清除 WGA 的小程序,使用者只要通过它,就可以阻止微软的 WGA 在系统每次启动时企图连回微软网站的动作,且使用它并不需要担心微软的正版验证机制,你还是一样能够正常的使用 Windows update 的功能,两者之间并没有任何冲突。虽然系统仍是破解的,但将不会再有任何提示,和以前没有变化。注:该工具会被部分杀毒软件识别为病毒。如须使用,下载前可能需要暂时禁用或者关闭一下病毒防火墙。使用过后再恢复。
华军下载地址:http://www.onlinedown.net/soft/6914.htm