

设规则:
属性-文件传输规则-全局
如果 时间 为 较旧 并且 传输 为 下载 那么 覆盖
如果 大小 为 不同 并且 传输 为 下载 那么 覆盖
如果没有匹配的规则,那么:跳过
建站点:
站点-站点管理器-新建站点
设好本地路径,传输 自定义规则 使用全局设置
队列:
连接站点,在需要备份的目录上右键,队列
在队列上右键,另存为
计划:
工具-计划-新建任务
选择队列文件,使用自定义规则
设置执行时间,Windows 密码
设置完成!

| 符号 | 规则 | 示例 |
= | 精确匹配 | location = /a 仅可以匹配 /a 这个 uri |
| 不带任何修饰符 | 前缀匹配 | location /a 可以匹配 /a、/ab、/a/b 等 uri |
~ 或 ~* | 正则匹配
|
|
如果有多个 location 块匹配同一个请求,Nginx 会优先选择精确匹配的块,其次是正则匹配,最后是前缀匹配。
~ 与 ~* 不分优先,视 location 位置先后来匹配。
微信是一个生活方式,朋友圈是用户分享和关注朋友们生活点滴的空间,微信公众平台是一个企业、机构与个人用户之间交流和服务的平台。一直以来,微信致力于为用户提供绿色、健康的网络生态环境。通过《微信公众平台服务协议》、《微信公众平台运营规范》和《微信开放平台开发者服务协议》等相关协议及专项规则,微信公众平台和微信开放平台的内容得到了良好的管理。为了进一步优化微信用户的使用体验,更好地保障微信用户合法权益,现将非由微信公众平台产生(即域名地址不归属于微信公众平台)且在微信内传播的外部链接内容相关管理规范进行公示。
对于违反本规范的内容,一经发现将立即进行处理,包括但不限于停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行访问、屏蔽相关链接等。由微信公众平台或开放平台帐号施行或者发起的,一经查实,前述帐号、主体也将按照微信相关规则进行处罚,包括但不限于限制或禁止使用部分或全部功能、帐号封禁直至注销等,并公告处理结果;微信也有权依照本规范及相关协议、专项规则的规定,拒绝再向前述主体提供服务。
具体规则及相关处罚如下:
-
诱导分享类内容
-
1.1 要求用户分享,分享后方可进行下一步操作,分享后方可知道答案等;
-
1.2 含有明示或暗示用户分享的文案、图片、按钮、弹层、弹窗等的,如:分享给好友、邀请好友一起完成任务等;
-
1.3 通过利益诱惑,诱导用户分享、传播外链内容或者微信公众帐号文章的,包括但不限于:现金奖励、实物奖品、虚拟奖品(红包、优惠券、代金券、积分、话费、流量、信息等)、集赞、拼团、分享可增加抽奖机会、中奖概率,以积分或金钱利益诱导用户分享、点击、点赞微信公众帐号文章等;
-
1.4 用夸张言语来胁迫、引诱用户分享的。包括但不限于:“不转不是中国人”、“请好心人转发一下”、“转发后一生平安”、“转疯了”、“必转”、“转到你的朋友圈朋友都会感激你”等;
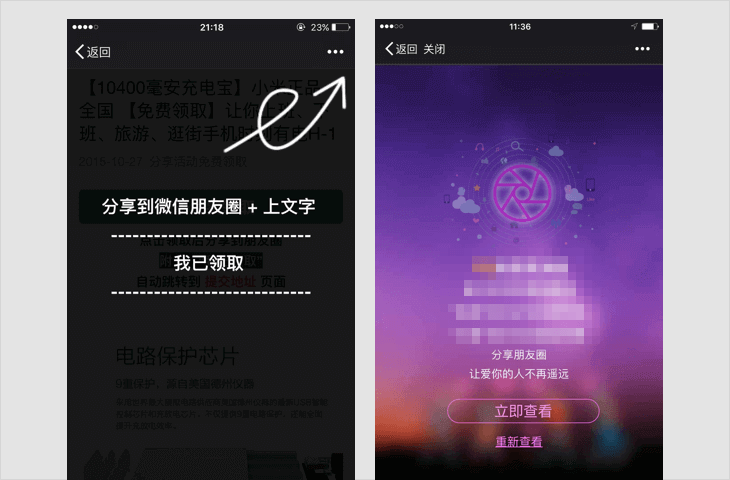
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问,短期封禁相关开放平台帐号或应用的分享接口;对于情节恶劣的情况,永久封禁帐号、域名、IP地址或分享接口。
-
-
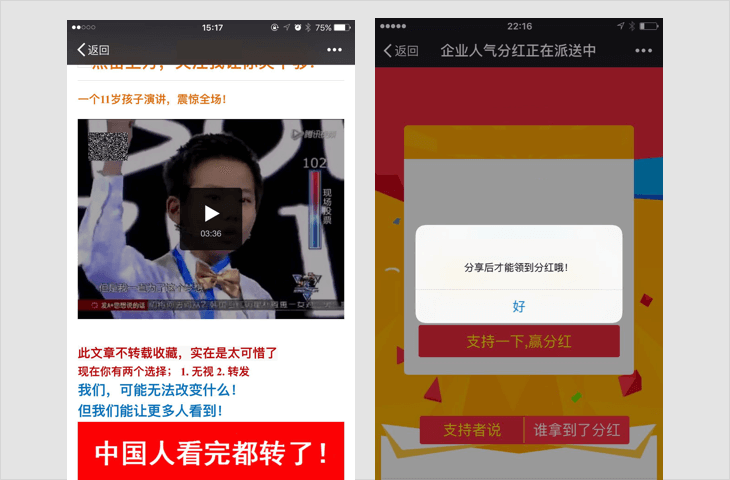
诱导关注类内容
-
强制或诱导用户关注公众帐号的,包括但不限于关注后查看答案、领取红包、关注后方可参与活动等;
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
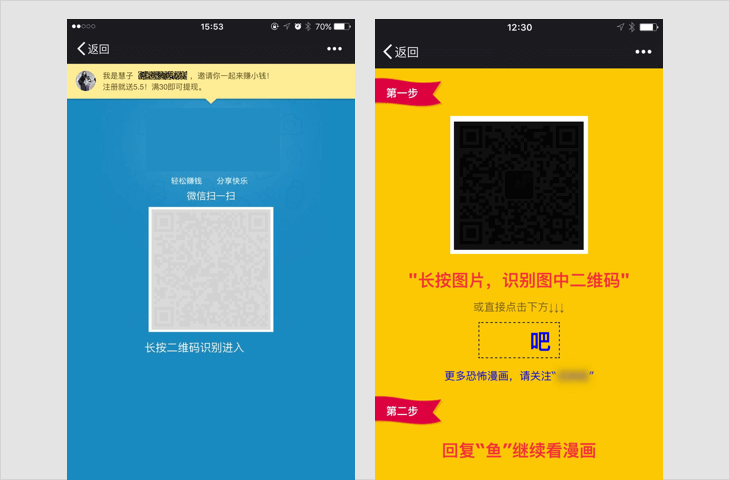
H5游戏、测试类内容
-
以游戏、测试等方式,吸引用户参与互动的,具体形式包括但不限于比手速、好友问答、性格测试,测试签、网页小游戏等;
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
欺诈类内容
-
4.1 虚假红包、活动
通过虚假的红包、活动等形式,以赚取现金、实物奖品、虚拟奖品等方式欺骗用户参与的,具体形式包括但不限于虚假现金红包、虚假话费卡、虚假流量红包、虚假优惠券、虚假优惠活动等;
-
4.2 宣传或销售侵害他人合法权益的商品
通过虚假宣传、恶意营销等方式,向用户宣传或诱骗用户购买侵害他人合法权益的物品的,例如以骗取邮费为目的的赠送物品活动、虚假付费服务等;
-
4.3 仿冒微信公众帐号排版、域名
仿冒微信公众帐号文章排版、域名,可能造成微信用户混淆的;
若内容中包含以上情况,一经发现,立即永久封禁帐号、域名、IP地址。
-
-
谣言类内容
-
发送不实信息,制造谣言,可能对他人、企业或其他机构造成损害的,例如自来水有毒、香蕉致癌、小龙虾不能吃等;
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问、短期封禁相关开放平台帐号或应用的分享接口;对于情节恶劣的情况,永久封禁帐号、域名、IP地址;
-
-
骚扰信息、广告信息及垃圾信息
-
传播骚扰、欺诈、垃圾广告等信息的,包括但不限于虚假中奖类信息,不符合国家相关法律法规的保健品、药品、食品类信息,假冒伪劣商品信息,虚假服务信息,虚假网络货币等;
-
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
题文不符、内容低俗的信息
-
7.1 题文不符的信息
故意拟制耸动标题,或以明显倾向性、误导性、煽动性的标题吸引他人点击的,即俗称“标题党”;
-
7.2 内容低俗的信息
涉及性器官、性行为、性暗示的,传播低级趣味、庸俗、有伤风化内容的,或者宣扬暴力、恶意谩骂、侮辱他人内容的,例如:传播走光、偷拍、露点、一夜情、换妻、性虐待、情色动漫、非法性药品广告和性病治疗广告、推介淫秽色情网站等;
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
非法获取用户数据、信息
-
未经用户明确同意,并向用户如实披露数据用途、使用范围等相关信息的情形下复制、存储、使用或传输用户数据的,包括但不限于要求用户共享个人信息(手机号、出生日期等)才可使用其功能,或收集用户密码或者用户个人信息(包括但不限于,手机号,身份证号,生日,住址等);
-
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问,短期封禁相关帐号;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
其它违反国家法律法规的内容,包括但不限于:
-
(1) 违反宪法确定的基本原则的;
-
(2) 危害国家安全,泄露国家秘密,颠覆国家政权,破坏国家统一的;
-
(3) 损害国家荣誉和利益的;
-
(4) 煽动民族仇恨、民族歧视,破坏民族团结的;
-
(5) 破坏国家宗教政策,宣扬邪教和封建迷信的;
-
(6) 散布谣言,扰乱社会秩序,破坏社会稳定的;
-
(7) 散布淫秽、色情、赌博、暴力、恐怖或者教唆犯罪的;
-
(8) 侮辱或者诽谤他人,侵害他人合法权益的;
-
(9) 煽动非法集会、结社、游行、示威、聚众扰乱社会秩序;
-
(10) 以非法民间组织名义活动的;
-
(11) 含有法律、行政法规禁止的其他内容的。
-
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问,短期封禁相关帐号;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
申诉及常见问题可查看:http://kf.qq.com/faq/131117ne2MV7141117JzI32q.html
微信团队请用户主动遵守上述条款,也欢迎用户对违反微信链接类内容管理规范的内容进行投诉,一经核实,微信团队将立即按照规范进行处理。让我们共同创建并维护和谐的微信生态!
微信团队
以某论坛配置 memcache 只允许本机 IP 访问 11211 端口为例:
一句一句执行:
service iptables status // 查询当前防火墙状态 iptables -A INPUT -s 127.0.0.1/24 -p tcp --dport 11211 -j ACCEPT // 允许本地回环 iptables -A INPUT -s X.X.X.X/24 -p tcp --dport 11211 -j ACCEPT // 允许本机内网IP iptables -A INPUT -s X.X.X.X/24 -p tcp --dport 11211 -j ACCEPT // 允许本机公网IP iptables -A INPUT -p tcp --dport 11211 -j DROP // 禁止其它IP service iptables status // 查询当前防火墙状态 service iptables save // 保存规则
在 ASP.NET Core 或 ASP.NET 5 中部署百度编辑器请跳转此文。
本文记录百度编辑器 ASP.NET 版的部署过程,对其它语言版本也有一定的参考价值。
【2020.02.21 重新整理】
下载
从 GitHub 下载最新发布版本:https://github.com/fex-team/ueditor/releases
按编码分有 gbk 和 utf8 两种版本,按服务端编程语言分有 asp、jsp、net、php 四种版本,按需下载。
目录介绍
以 v1.4.3.3 utf8-net 为例,

客户端部署
本例将上述所有目录和文件拷贝到网站目录 /libs/ueditor/ 下。
当然也可以引用 CDN 静态资源,但会遇到诸多跨域问题,不建议。
在内容编辑页面引入:
<script src="/libs/ueditor/ueditor.config.js"></script>
<script src="/libs/ueditor/ueditor.all.min.js"></script>在内容显示页面引入:
<script src="/libs/ueditor/ueditor.parse.min.js"></script>如需修改编辑器资源文件根路径,参 ueditor.config.js 文件内顶部文件。(一般不需要单独设置)
如果使用 CDN,那么在初始化 UE 实例的时候应配置 serverUrl 值(即 controller.ashx 所在路径)。
客户端配置
初始化 UE 实例:
var ue = UE.getEditor('tb_content', {
// serverUrl: '/libs/ueditor/net/controller.ashx', // 指定服务端接收文件路径
initialFrameWidth: '100%'
});其它参数见官方文档,或 ueditor.config.js 文件。
服务端部署
net 目录是 ASP.NET 版的服务端程序,用来实现接收上传的文件等功能。
本例中在网站中的位置是 /libs/ueditor/net/。如果改动了位置,那么在初始化 UE 的时候也应该配置 serverUrl 值。
这是一个完整的 VS 项目,可以单独部署为一个网站。其中:
net/config.json 服务端配置文件
net/controller.ashx 文件上传入口
net/App_Code/CrawlerHandler.cs 远程抓图动作
net/App_Code/ListFileManager.cs 文件管理动作
net/App_Code/UploadHandler.cs 上传动作
该目录不需要转换为应用程序。
服务端配置
根据 config.json 中 *PathFormat 的默认配置,一般地,上传的图片会保存在 controller.ashx 文件所在目录(即本例中的 /libs/ueditor/)的 upload 目录中:
/libs/ueditor/upload/image/
原因是 UploadHandler.cs 中 Server.MapPath 的参数是由 *PathFormat 决定的。
以修改 config.json 中的 imagePathFormat 为例:
原值:"imagePathFormat": "upload/image/{yyyy}{mm}{dd}/{time}{rand:6}"
改为:"imagePathFormat": "/upload/ueditor/{yyyy}{mm}{dd}/{time}{rand:6}"
以“/”开始的路径在 Server.MapPath 时会定位到网站根目录。
此处不能以“~/”开始,因为最终在客户端显示的图片路径是 imageUrlPrefix + imagePathFormat,若其中包含符号“~”就无法正确显示。
在该配置文件中查找所有 PathFormat,按相同的规则修改。
说到客户端的图片路径,我们只要将
原值:"imageUrlPrefix": "/ueditor/net/"
改为:"imageUrlPrefix": ""
即可返回客户端正确的 URL。
当然也要同步修改 scrawlUrlPrefix、snapscreenUrlPrefix、catcherUrlPrefix、videoUrlPrefix、fileUrlPrefix。
特殊情况,在复制包含图片的网页内容的操作中,若图片地址带“?”等符号,会出现无法保存到磁盘的情况,需要修改以下代码:
打开 CrawlerHandler.cs 文件,找到
ServerUrl = PathFormatter.Format(Path.GetFileName(this.SourceUrl), Config.GetString("catcherPathFormat"));替换成:
ServerUrl = PathFormatter.Format(Path.GetFileName(SourceUrl.Contains("?") ? SourceUrl.Substring(0, SourceUrl.IndexOf("?")) : SourceUrl), Config.GetString("catcherPathFormat"));如果你将图片保存到第三方图库,那么 imageUrlPrefix 值设为相应的域名即可,如:
改为:"imageUrlPrefix": "//cdn.***.com"
然后在 UploadHandler.cs 文件(用于文件上传)中找到
File.WriteAllBytes(localPath, uploadFileBytes);在其下方插入上传到第三方图库的代码,以阿里云 OSS 为例:
// 上传到 OSS
client.PutObject(bucketName, savePath.Substring(1), localPath);在 CrawlerHandler.cs 文件(无程抓图上传)中找到
File.WriteAllBytes(savePath, bytes);在其下方插入上传到第三方图库的代码,以阿里云 OSS 为例:
// 上传到 OSS
client.PutObject(bucketName, ServerUrl.Substring(1), savePath);最后有还有两个以 UrlPrefix 结尾的参数名 imageManagerUrlPrefix 和 fileManagerUrlPrefix 分别是用来列出上传目录中的图片和文件的,
对应的操作是在编辑器上的“多图上传”功能的“在线管理”,和“附件”功能的“在线附件”。
最终列出的图片路径是由 imageManagerUrlPrefix + imageManagerListPath + 图片 URL 组成的,那么:
"imageManagerListPath": "/upload/ueditor/image",
"imageManagerUrlPrefix": "",
以及:
"fileManagerListPath": "/upload/ueditor/file",
"fileManagerUrlPrefix": "",
即可。
如果是上传到第三方图库的,且图库上的文件与本地副本是一致的,那么将 imageManagerUrlPrefix 和 fileManagerUrlPrefix 设置为图库域名,
服务端仍然以 imageManagerListPath 指定的路径来查找本地文件(非图库),但客户端显示图库的文件 URL。
因此,如果文件仅存放在图库上,本地没有副本的情况就无法使用该功能了。
综上,所有的 *UrlPrefix 应该设为一致。
另外记得配置不希望被远程抓图的域名,参数 catcherLocalDomain。
服务端授权
现在来判断一下只有登录用户才允许上传。
首先打开服务端的统一入口文件 controller.ashx,
继承类“IHttpHandler”改为“IHttpHandler, System.Web.SessionState.IRequiresSessionState”,即同时继承两个类,以便可使用 Session,
找到“switch”,其上插入:
if (用户未登录) { throw new System.Exception("请登录后再试"); }即用户已登录或 action 为获取 config 才进入 switch。然后,
else
{
action = new NotAllowedHandler(context);
}这里的 NotAllowedHandler 是参照 NotSupportedHandler 创建的,提示语 state 可以是“登录后才能进行此操作。”
上传目录权限设置
上传目录(即本例中的 /upload/ueditor/ 目录)应设置允许写入和禁止执行。
基本用法
设置内容:
ue.setContent("Hello world.");获取内容:
var a = ue.getContent();更多用法见官方文档:http://fex.baidu.com/ueditor/#api-common
其它事宜
配置上传附件的文件格式
找到文件:config.json,更改“上传文件配置”的 fileAllowFiles 项,
同时在 Web 服务器上允许这些格式的文件可访问权限。以 IIS 为例,在“MIME 类型”模块中添加扩展名。
遇到从客户端(......)中检测到有潜在危险的 Request.Form 值。请参考此文
另外,对于不支持上传 .webp 类型的图片的问题,可以作以下修改:
config.json 中搜索“".bmp"”,替换为“".bmp", ".webp"”
IIS 中选中对应网站或直接选中服务器名,打开“MIME 类型”,添加,文件扩展名为“.webp”,MIME 类型为“image/webp”
最后,为了在内容展示页面看到跟编辑器中相同的效果,请参照官方文档引用 uParse
若有插入代码,再引用:
<link href="/lib/ueditor/utf8-net/third-party/SyntaxHighlighter/shCoreDefault.css" rel="stylesheet" />
<script src="/lib/ueditor/utf8-net/third-party/SyntaxHighlighter/shCore.js"></script>
其它插件雷同。
若对编辑器的尺寸有要求,在初始化时设置即可:
var ue = UE.getEditor('tb_content', {
initialFrameWidth: '100%',
initialFrameHeight: 320
});
本文适用于 IIS 7, IIS 7.5, IIS 8, IIS 8.5, IIS 10 等 Web 服务器,IIS 6(Windows Server 2003)用户请查阅 ISAPI_Rewrite。
在 IIS 中要实现 URL 重写,需要下载并安装 URL Rewrite 组件,http://www.iis.net/downloads/microsoft/url-rewrite
在 IIS 管理器中选中任意网站,主窗口可见“URL 重写”,双击打开。(如果你想配置这台服务器的所有网站有效,直接选中左侧菜单中的服务器名,打开“URL 重写”即可。)
右侧“添加规则...”,选择“入站规则”中的“空白规则”,确定。
填写规则名称,在“匹配 URL”框中选择“与模式匹配”,根据自己的需求选择“正则表达式”、“通配符”或“完全匹配”,“模式”中填写要防盗链的文件路径规则,例如正则表达式 ^.*\.(jpg|png)$ 将匹配所有目录下的 .jpg 和 .png 文件。
接下来将设置图片在允许的域名下显示。
在“条件”框中选择“全部匹配”,点击“添加”,“条件输入”中填写“{HTTP_REFERER}”(不含引号,含花括号),表示判断 HTTP 请求中 Header 的 Referer。选择“与模式不匹配”,模式中填写匹配规则,如 ^$ 表示允许 Referer 为空(如直接从浏览器打开的情况),再加一个规则 ^https?://([^/]*\.)?(xoyozo.net|himiao.com)/.*$ 表示允许在 xoyozo.net 和 himiao.com 这两个域名下显示图片。当然如果你有很多域名或需要设置不同的规则,可以继续添加,但最好把访问量大的规则移到前面,从而减少系统匹配次数,提高访问效率。
最后,在“操作”框中设置你想要的处理方式,可以是“重定向”到一张防盗链提醒的图片上(推荐类型临时 307),也可以自定义响应,例如,状态代码(403),子代码(0),原因(Forbidden: Access is denied.),描述(You do not have permission to view this directory or page using the credentials that you supplied.),查看 HTTP 状态代码。
如果你是配置某个网站的“URL 重写”,那么在网站根目录下的 web.config 文件中,<system.webServer /> 节点下可以看到刚刚配置的规则,例如:
<rewrite>
<rules>
<rule name="RequestBlockingRule1" stopProcessing="true">
<match url="^.*\.(jpg|png)$" />
<conditions>
<add input="{HTTP_REFERER}" pattern="^https?://([^/]*\.)?(xoyozo.net|himiao.com)/.*$" negate="true" />
<add input="{HTTP_REFERER}" pattern="^$" negate="true" />
</conditions>
<action type="Redirect" url="http://42.96.165.253/logo2013.png" redirectType="Temporary" />
</rule>
</rules>
</rewrite>
公司有个项目是使用实体刷卡的会员管理系统,并为其它系统如餐饮系统、美发厅管理系统等提供统一的会员注册与信息管理。暂定使用一维条形码卡。
一般来说,商品最常用的编码是EAN-13,而非商品(如图书馆会员卡,驾驶证条码等)一般使用39码。
39码 在线测试地址:http://xoyozo.net/Tools/Code39
EAN-13 在线测试地址:http://xoyozo.net/Tools/EAN-13
39码
39码比较简单,条码以“*”为起始符和终止符,见下图:

它所能表示的字符包括:0~9 的数字,大写 A~Z 的英文字母,「+」,「-」,「*」,「/」,「%」,「$」,「.」,以及空格符(Space)等,共44组编码。
39码表:“0”对应白色空位,“1”对应黑色线条。
| 字元 | 逻辑型态 | 字元 | 逻辑型态 |
|---|---|---|---|
| A | 110101001011 | N | 101011010011 |
| B | 101101001011 | O | 110101101001 |
| C | 110110100101 | P | 101101101001 |
| D | 101011001011 | Q | 101010110011 |
| E | 110101100101 | R | 110101011001 |
| F | 101101100101 | S | 101101011001 |
| G | 101010011011 | T | 101011011001 |
| H | 110101001101 | U | 110010101011 |
| I | 101101001101 | V | 100110101011 |
| J | 101011001101 | W | 110011010101 |
| K | 110101010011 | X | 100101101011 |
| L | 101101010011 | Y | 110010110101 |
| M | 110110101001 | Z | 100110110101 |
| 字元 | 逻辑型态 | 字元 | 逻辑型态 |
|---|---|---|---|
| 0 | 101001101101 | + | 100101001001 |
| 1 | 110100101011 | - | 100101011011 |
| 2 | 101100101011 | * | 100101101101 |
| 3 | 110110010101 | / | 100100101001 |
| 4 | 101001101011 | % | 101001001001 |
| 5 | 110100110101 | $ | 100100100101 |
| 6 | 101100110101 | . | 110010101101 |
| 7 | 101001011011 | 空白 | 100110101101 |
| 8 | 110100101101 | ||
| 9 | 101100101101 |
值得注意的是,39码生成的条形中,每个码之间有一个空位,经扫描枪测试,该空位与一个单位的线条宽度相等时,能确保被正确扫描。
代码见附件
EAN-13码
EAN-13码是由13位数字构成,其中最后一位为校验码:

| 左侧空白区 | 起始符 | 左侧数据符 | 中间分隔符 | 右侧数据符 | 校验符 | 终止符 | 右测空白区 |
| 9个模块 | 3个模块 | 42个模块 | 5个模块 | 35个模块 | 7个模块 | 3个模块 | 9个模块 |
校验码计算的步骤如下: 以 234235654652 为例:
| 数据码 | 校验码 | ||||||||||||
| 代码位置序号 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 数字码 | 2 | 3 | 4 | 2 | 3 | 5 | 6 | 5 | 4 | 6 | 5 | 2 | ? |
| 偶数位 | 3 | + | 2 | + | 5 | + | 5 | + | 6 | + | 2 | ||
| 奇数位 | 2 | + | 4 | + | 3 | + | 6 | + | 4 | + | 5 | ||
① 从序号2开始,将所有偶数位的数字代码求和,得出S1; S1=3+2+5+5+6+2=23
② 从序号3开始,将所有奇数位的数字求和,得出S2; S2=2+4+3+6+4+5=24
③ S3=S1*3+S2; S3=23*3+24=93
④ C=10-(S3的个位数),得到校验码C的值。并且当S3的个位数为0时,C=0。 C=10-3=7
EAN码的编码规则:
数字符 |
左侧数据符 | 右侧数据符 | |
| A | B | C | |
| 0 | 0001101 | 0100111 | 1110010 |
| 1 | 0011001 | 0110011 | 1100110 |
| 2 | 0010011 | 0011011 | 1101100 |
| 3 | 0111101 | 0100001 | 1000010 |
| 4 | 0100011 | 0011101 | 1011100 |
| 5 | 0110001 | 0111001 | 1001110 |
| 6 | 0101111 | 0000101 | 1010000 |
| 7 | 0111011 | 0010001 | 1000100 |
| 8 | 0110111 | 0001001 | 1001000 |
| 9 | 0001011 | 0010111 | 1110100 |
(关于左侧数据符,网络上的资料均显示A3及B6为6位数,经本人实践亲自查证,已修正)
起始符:101
中间分隔符:01010
终止符:101。
A、B、C中的“0”和“1”分别表示具有一个模块宽度的“空”和“条”。
因为左侧数据编码方式有两种,要按照前置码选其中一种,如表:
| 前置字符 | 左侧数据符编码规则的选择 | |||||
| 0 | A | A | A | A | A | A |
| 1 | A | A | B | A | B | B |
| 2 | A | A | B | B | A | B |
| 3 | A | A | B | B | B | A |
| 4 | A | B | A | A | B | B |
| 5 | A | B | B | A | A | B |
| 6(中国) | A | B | B | B | A | A |
| 7 | A | B | A | B | A | B |
| 8 | A | B | A | B | B | A |
| 9 | A | B | B | A | B | A |
方法:
write,向HTML动态写入内容
writeln,多加一个换行
open,与window.open类似,不建议用
close,当向新打开的文档对象中写完所有的内容后,一定要调用该方法关闭文档流
clear,用于清除文档中的所有内容,建议用document.write("");document.close();这两条语句来实现同样的功能。
getElementById,返回id的对象
getElementByName,返回name的对象组(注意是数组)
getElementByTagName,返回标签名的对象组
createElement,产生一个代表某个HTML元素的对象,随后再其它方法将这个对象插入到文档中。
createStyleSheet,为当前HTML产生一个样式表或增加一条样式规则。
属性:
document.cookie
自从有了IP数据库这种东西,QQ外挂的显示IP功能也随之而生,本人见识颇窄,是否还有其他应用不得而知,不过,IP数据库确实是个不错的东西。如今网络上最流行的IP数据库我想应该是纯真版的(说错了也不要扁我),迄今为止其IP记录条数已经接近30000,对于有些IP甚至能精确到楼层,不亦快哉。2004年4、5月间,正逢LumaQQ破土动工,为了加上这个人人都喜欢,但是好像人人都不知道为什么喜欢的显IP功能,我也采用了纯真版IP数据库,它的优点是记录多,查询速度快,它只用一个文件QQWry.dat就包含了所有记录,方便嵌入到其他程序中,也方便升级。
基本结构
QQWry.dat文件在结构上分为3块:文件头,记录区,索引区。一般我们要查找IP时,先在索引区查找记录偏移,然后再到记录区读出信息。由于记录区的记录是不定长的,所以直接在记录区中搜索是不可能的。由于记录数比较多,如果我们遍历索引区也会是有点慢的,一般来说,我们可以用二分查找法搜索索引区,其速度比遍历索引区快若干数量级。图1是QQWry.dat的文件结构图。

图1. QQWry.dat文件结构
要注意的是,QQWry.dat里面全部采用了little-endian字节序
一. 了解文件头
QQWry.dat的文件头只有8个字节,其结构非常简单,首四个字节是第一条索引的绝对偏移,后四个字节是最后一条索引的绝对偏移。
二. 了解记录区
每条IP记录都由国家和地区名组成,国家地区在这里并不是太确切,因为可能会查出来“清华大学计算机系”之类的,这里清华大学就成了国家名了,所以这个国家地区名和IP数据库制作的时候有关系。所以记录的格式有点像QName,有一个全局部分和局部部分组成,我们这里还是沿用国家名和地区名的说法。
于是我们想象着一条记录的格式应该是: [IP地址][国家名][地区名],当然,这个没有什么问题,但是这只是最简单的情况。很显然,国家名和地区名可能会有很多的重复,如果每条记录都保存一个完整的名称拷贝是非常不理想的,所以我们就需要重定向以节省空间。所以为了得到一个国家名或者地区名,我们就有了两个可能:第一就是直接的字符串表示的国家名,第二就是一个4字节的结构,第一个字节表明了重定向的模式,后面3个字节是国家名或者地区名的实际偏移位置。对于国家名来说,情况还可能更复杂些,因为这样的重定向最多可能有两次。
那么什么是重定向模式?根据上面所说,一条记录的格式是[IP地址][国家记录][地区记录],如果国家记录是重定向的话,那么地区记录是有可能没有的,于是就有了两种情况,我管他叫做模式1和模式2。我们对这些格式的情况举图说明:

图2. IP记录的最简单形式
图2表示了最简单的IP记录格式,我想没有什么可以解释的

图3. 重定向模式1
图3演示了重定向模式1的情况。我们看到在模式1的情况下,地区记录也跟着国家记录走了,在IP地址之后只剩下了国家记录的4字节,后面3个字节构成了一个指针,指向了实际的国家名,然后又跟着地址名。模式1的标识字节是0x01。

图4. 重定向模式2
图4演示了重定向模式2的情况。我们看到了在模式2的情况下(其标识字节是0x02),地区记录没有跟着国家记录走,因此在国家记录之后4个字节之后还是有地区记录。我想你已经明白了模式1和模式2的区别,即:模式1的国家记录后面不会再有地区记录,模式2的国家记录后会有地区记录。下面我们来看一下更复杂的情况。

图5. 混和情况1
图5演示了当国家记录为模式1的时候可能出现的更复杂情况,在这种情况下,重定向指向的位置仍然是个重定向,不过第二次重定向为模式2。大家不用担心,没有模式3了,这个重定向也最多只有两次,并且如果发生了第二次重定向,则其一定为模式2,而且这种情况只会发生在国家记录上,对于地区记录,模式1和模式2是一样的,地区记录也不会发生2次重定向。不过,这个图还可以更复杂,如图7:

图6. 混和情况2
图6是模式1下最复杂的混和情况,不过我想应该也很好理解,只不过地区记录也来重定向而已,有一点我要提醒你,如果重定向的地址是0,则表示未知的地区名。
所以我们总结如下:一条IP记录由[IP地址][国家记录][地区记录]组成,对于国家记录,可以有三种表示方式:字符串形式,重定向模式1和重定向模式2。对于地区记录,可以有两种表示方式:字符串形式和重定向,另外有一条规则:重定向模式1的国家记录后不能跟地区记录。按照这个总结,在这些方式中合理组合,就构成了IP记录的所有可能情况。
设计的理由
在我们继续去了解索引区的结构之前,我们先来了解一下为何记录区的结构要如此设计。我想你可能想到了答案:字符串重用。没错,在这种结构下,对于一个国家名和地区名,我只需要保存其一次就可以了。我们举例说明,为了表示方便,我们用小写字母代表IP记录,C表示国家名,A表示地区名:
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2, A1 = A2,那么我们就可以使用图3显示的结构来实现重用
有三条记录a(C1, A1), b(C2, A2), c(C3, A3),如果C1 = C2, A2 = A3,现在我们想存储记录b,那么我们可以用图6的结构来实现重用
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2,现在我们想存储记录b,那么我们可以采用模式2表示C2,用字符串表示A2
你可以举出更多的情况,你也会发现在这种结构下,不同的字符串只需要存储一次。
了解索引区
在"了解文件头"部分,我们说明了文件头实际上是两个指针,分别指向了第一条索引和最后一条索引的绝对偏移。如图8所示:

图8. 文件头指向索引区图示
实在是很简单,不是吗?从文件头你就可以定位到索引区,然后你就可以开始搜索IP了!每条索引长度为7个字节,前4个字节是起始IP地址,后三个字节就指向了IP记录。这里有些概念需要说明一下,什么是起始IP,那么有没有结束IP?假设有这么一条记录:166.111.0.0 - 166.111.255.255,那么166.111.0.0就是起始IP,166.111.255.255就是结束IP,结束IP就是IP记录中的那头4个字节,这下你应该就清楚了吧。于是乎,每条索引配合一条记录,构成了一个IP范围,如果你要查找166.111.138.138所在的位置,你就会发现166.111.138.138落在了166.111.0.0- 166.111.255.255 这个范围内,那么你就可以顺着这条索引去读取国家和地区名了。那么我们给出一个最详细的图解吧:

图9. 文件详细结构
现在一切都清楚了是不是?也许还有一点你不清楚,QQWry.dat的版本信息存在哪里呢? 答案是:最后一条IP记录实际上就是版本信息,最后一条记录显示出来就是这样:255.255.255.0255.255.255.255 纯真网络 2004年6月25日IP数据。OK,到现在你应该全部清楚了。
Demo
下一步:我给出一个读取IP记录的程序片断,此片断摘录自LumaQQ源文件edu.tsinghua.lumaqq.IPSeeker.java,如果你有兴趣,可以下载源代码详细看看。
/** *//**
* 给定一个ip国家地区记录的偏移,返回一个IPLocation结构
* @param offset 国家记录的起始偏移
* @return IPLocation对象
*/
private IPLocation getIPLocation(long offset) {
try {
// 跳过4字节ip
ipFile.seek(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = ipFile.readByte();
if(b == REDIRECT_MODE_1) {
// 读取国家偏移
long countryOffset = readLong3();
// 跳转至偏移处
ipFile.seek(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = ipFile.readByte();
if(b == REDIRECT_MODE_2) {
loc.country = readString(readLong3());
ipFile.seek(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(ipFile.getFilePointer());
} else if(b == REDIRECT_MODE_2) {
loc.country = readString(readLong3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(ipFile.getFilePointer() - 1);
loc.area = readArea(ipFile.getFilePointer());
}
return loc;
} catch (IOException e) {
return null;
}
}
/** *//**
* 从offset偏移开始解析后面的字节,读出一个地区名
* @param offset 地区记录的起始偏移
* @return 地区名字符串
* @throws IOException 地区名字符串
*/
private String readArea(long offset) throws IOException {
ipFile.seek(offset);
byte b = ipFile.readByte();
if(b == REDIRECT_MODE_1 || b == REDIRECT_MODE_2) {
long areaOffset = readLong3(offset + 1);
if(areaOffset == 0)
return LumaQQ.getString("unknown.area");
else
return readString(areaOffset);
} else
return readString(offset);
}
/** *//**
* 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法
* 用了这么一个函数来做转换
* @param offset 整数的起始偏移
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/** *//**
* 从当前位置读取3个字节转换成long
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3() {
long ret = 0;
try {
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/** *//**
* 从offset偏移处读取一个以0结束的字符串
* @param offset 字符串起始偏移
* @return 读取的字符串,出错返回空字符串
*/
private String readString(long offset) {
try {
ipFile.seek(offset);
int i;
for(i = 0, buf[i] = ipFile.readByte(); buf[i] != 0; buf[++i] = ipFile.readByte());
if(i != 0)
return Utils.getString(buf, 0, i, "GBK");
} catch (IOException e) {
log.error(e.getMessage());
}
return "";
}代码并不复杂,getIPLocation是主要方法,它检查国家记录格式,并针对字符串形式,模式1,模式2采用不同的代码,readArea则相对简单,因为只有字符串和重定向两种情况需要处理。
总结
纯真IP数据库的结构使得查找IP简单迅速,不过你想要编辑它却是比较麻烦的,我想应该需要专门的工具来生成QQWry.dat文件,由于其文件格式的限制,你要直接添加IP记录就不容易了。不过,能查到IP已经很开心了,希望纯真记录越来越多~。
LumaQQ is a Java QQ client which has a reusablepure Java core and SWT-based GUI
根据〖中华人民共和国国家标准 GB 11643-1999〗中有关公民身份号码的规定,公民身份号码是特征组合码,由十七位数字本体码和一位数字校验码组成。
排列顺序从左至右依次为:六位数字地址码,八位数字出生日期码,三位数字顺序码和一位数字校验码。
地址码表示编码对象常住户口所在县(市、旗、区)的行政区划代码。
生日期码表示编码对象出生的年、月、日,其中年份用四位数字表示,年、月、日之间不用分隔符。
顺序码表示同一地址码所标识的区域范围内,对同年、月、日出生的人员编定的顺序号。顺序码的奇数分给男性,偶数分给女性。
校验码是根据前面十七位数字码,按照ISO 7064:1983.MOD 11-2校验码计算出来的检验码。下面举例说明该计算方法。
15位的身份证编码首先把出生年扩展为4位,简单的就是增加一个19,但是这对于1900年出生的人不使用(这样的寿星不多了)
某男性公民身份号码本体码为34052419800101001,首先按照公式⑴计算:
∑(ai×Wi)(mod 11)……………………………………(1)
公式(1)中:
i----表示号码字符从由至左包括校验码在内的位置序号;
ai----表示第i位置上的号码字符值;
Wi----示第i位置上的加权因子,其数值依据公式Wi=2(n-1)(mod 11)计算得出。
i 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
ai 3 4 0 5 2 4 1 9 8 0 0 1 0 1 0 0 1 a1
Wi 7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2 1
ai×Wi 21 36 0 25 16 16 2 9 48 0 0 9 0 5 0 0 2 a1
根据公式(1)进行计算:
∑(ai×Wi) =(21+36+0+25+16+16+2+9+48++0+0+9+0+5+0+0+2) = 189
189 ÷ 11 = 17 + 2/11
∑(ai×Wi)(mod 11) = 2
然后根据计算的结果,从下面的表中查出相应的校验码,其中X表示计算结果为10:
∑(ai×WI)(mod 11) 0 1 2 3 4 5 6 7 8 9 10
校验码字符值ai 1 0 X 9 8 7 6 5 4 3 2
根据上表,查出计算结果为2的校验码为所以该人员的公民身份号码应该为 34052419800101001X。
C#代码:
private string per15To18(string perIDSrc)
{
int iS = 0;
//加权因子常数
int[] iW = new int[] { 7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2 };
//校验码常数
string LastCode = "10X98765432";
//新身份证号
string perIDNew;
perIDNew = perIDSrc.Substring(0, 6);
//填在第6位及第7位上填上‘1’,‘9’两个数字
perIDNew += "19";
perIDNew += perIDSrc.Substring(6, 9);
//进行加权求和
for (int i = 0; i < 17; i++)
{
iS += int.Parse(perIDNew.Substring(i, 1)) * iW[i];
}
//取模运算,得到模值
int iY = iS % 11;
//从LastCode中取得以模为索引号的值,加到身份证的最后一位,即为新身份证号。
perIDNew += LastCode.Substring(iY, 1);
return perIDNew;
}