

猜想是无法给远程连接的用户权限问题。结果这样子操作mysql库,即可解决。在本机登入mysql后,更改 “mysql” 数据库里的 “user” 表里的 “host” 项,从”localhost”改称'%'。。
mysql -u root -p
mysql>use mysql;
mysql>select 'host' from user where user='root';
mysql>update user set host = '%' where user ='root';
mysql>flush privileges;
mysql>select 'host' from user where user='root';
第二句:选择mysql库
第三句:查看mysql库中的user表的host值(即可进行连接访问的主机/IP名称)
第四句:修改host值(以通配符%的内容增加主机/IP地址),当然也可以直接增加IP地址
第五句:刷新MySQL的系统权限相关表
第六句:再重新查看user表时,有修改。。
重起mysql服务即可完成。

一、添加引用 using System.Web.SessionState;
二、实现接口 public class Handler : IHttpHandler, IRequiresSessionState { }
三、使用方法 HttpContext.Current.Session["xxx"] = value;
调用返回 ArrayList 类型的 Web Service 的方法,可以使用如下代码获取数据集:
ArrayList al = new ArrayList(mallbll.MallsSearch());
做网页的朋友应该都知道常用的几个HTML转义符,如“ ”表示空格,“>”表示“>”等,但是有时候我们为了网页的文字不被搜索引擎收录,比如评论信息,这时可以用同样的方法去转义汉字等各种字符,一般格式为 "&#"+ASCII+";",如“中华人民共和国”可以转义为“中华人民共和国”。
在C#中可以这样来实现:
private string htmlEscape(string s)
{
StringBuilder sb = new StringBuilder();
foreach (char c in s)
{
sb.Append("&#" + (int)c + ";");
}
return sb.ToString();
}今年早些时候,我通过blog介绍了 C# 和 VB 语言的一项新的扩充特性"扩展方法"。
扩展方法让开发者可以向已有的 CLR 类型的公共契约中添加新的方法,而不需要子类化或重新编译原有的类型。通过这种做法,可以使很多有用的应用场景成为可能(包括 LINQ)。同时,扩展方法也可以用来非常方便地向代码中添加"语法糖"。
过去几个月,我一直在准备一些很酷的扩展方法的清单,并计划在有空的时候实现它们(不确定何时...但至少我还能从这些想法中获得乐趣)。在上述清单中有两个扩展方法的应用场景,分别是用于为任意 .NET 对象自动生成JSON (JavaScript Object Notation)或 XML 序列化字符串的。
简单场景:ToJSON() 扩展方法
假设我有一个 Person 类定义如下(注意:我使用了 自动属性的新特性来实现):
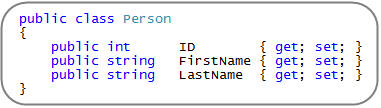
接下来,我就可以初始化一系列 Person 对象的集合,然后只需调用 ToJSON() 扩展方法,就能得到表示该集合内容的 JSON 字符串。如下所示:

这和 .NET 中内建的,Object 类的 ToString() 方法调用方式很相似 —— 只是生成的结果是表示集合内容的 JSON 格式的字符串而已。然后我们就可以在 AJAX 场景的客户端使用它:

注意:点击上图中调试器的放大镜图标,可以打开"文本视图(Text Visualizer)",能更方便的查看 JSON 序列化字符串:
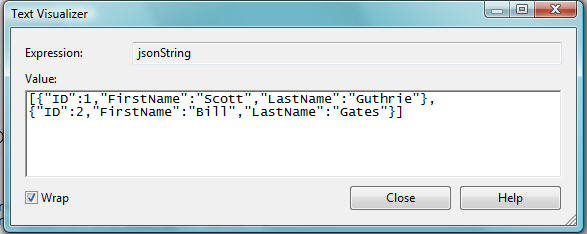
接下来,这个字符串格式在客户端可以用 JavaScript 来实例化为合适的 JavaScript 对象,用于表示我的集合内容(注: ASP.NET AJAX 有一个内建的 JavaScript 库支持这些特性)。
实现 ToJSON 扩展方法
实现一个基本的 ToJSON() 扩展方法很简单。只要使用 System.Web.Script.Serialization 命名空间下的 JavaScriptSerializer 类即可,然后象下面所示的那样定义两个扩展方法。其中一个方法用于对目标对象图(object graph)进行"深"的序列化,而另一个方法则是一个重载的版本,它允许你指定序列化的深度(比如:ToJSON(2) 只序列化 2 个层次的深度)。
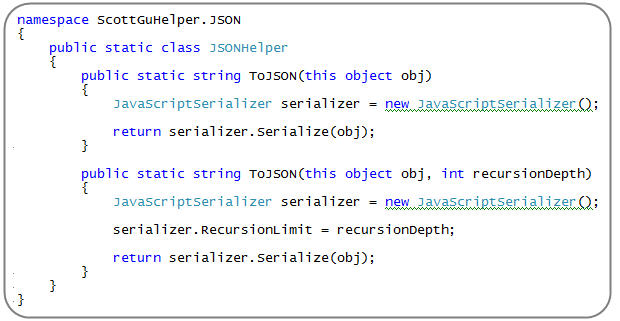
注意,上面的 ToJSON() 扩展方法只是针对 "Object" 类型而定义的——这意味着它可以被用于 .NET 中的任何类型(不限于集合)。也就是说,我们不仅能对上述集合调用 .ToJSON() 方法,还可以对单独的 Person 对象调用 ToJSON() 方法,或者任意其他的 .NET 类型都可以。
要使用上述扩展方法,只需在程序的顶部添加如下命名空间的引用即可:

然后 VS 2008 就可以为任意对象提供针对这些扩展方法的代码自动完成和编译时支持功能:
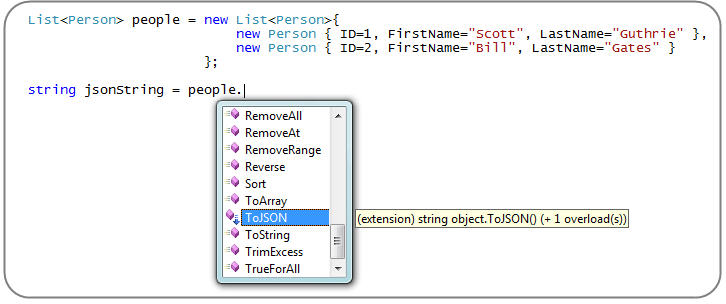
注意:除了 JavaScriptSerializer 类之外,.NET 3.5 还包含一个新的new System.Runtime.Serialization.DataContractJsonSerializer class 类 ,你也可以用它来做 JSON 序列化/反序列化的工作。
小结
希望以上的例子能给你一个使用扩展方法来封装功能的示例。下次希望我们一起来看一些好的工具库,用于提供类似有用的扩展方法的功能。
我非常想看到其他关于可复用的扩展方法使用场景的建议(请通过这篇帖子的评论来建议)。然后我们可以琢磨出,如何创建一个好的 CodePlex 项目,来把这些方法捆绑到一个库中以便利用。
希望这篇帖子对你有用,
Scott
相信大家绝大多数都希望任务栏的资源管理器默认打开的是计算机,而不是库,现在有一个超级简单的方法,给大家分享一下:在任务栏上找到资源管理器(windows explorer)图标,按住Shift+右键-属性,然后更改目标为下列内容:%SystemRoot%\explorer.exe /e, ::{20D04FE0-3AEA-1069-A2D8-08002B30309D}-
这样就可以默认打开计算机了,试一试吧!
有一个更简单的方法!!!
任务栏文件夹 - 右键 - Windows 资源管理器 - 右键 就可以直接修改啦!
改成任意文件夹路径都可以
使用AjaxControlTookit时,如果控件的右侧小箭头不出现,则可检查:
1,是否添加引用
2,工具箱中的相关选项卡对应的DLL是否跟引用中的DLL一致(可删除并重建相关选项卡)
一般情况下就可以正常使用AjaxControlTookit了。
返回序列中的第一个元素。
返回序列中的第一个元素;如果序列中不包含任何元素,则返回默认值。
返回序列的唯一元素;如果该序列并非恰好包含一个元素,则会引发异常。
返回序列中满足指定条件的唯一元素;如果这类元素不存在,则返回默认值;如果有多个元素满足该条件,此方法将引发异常。