

前言
最近在学习Web Api框架的时候接触到了async/await,这个特性是.NET 4.5引入的,由于之前对于异步编程不是很了解,所以花费了一些时间学习一下相关的知识,并整理成这篇博客,如果在阅读的过程中发现不对的地方,欢迎大家指正。
同步编程与异步编程
通常情况下,我们写的C#代码就是同步的,运行在同一个线程中,从程序的第一行代码到最后一句代码顺序执行。而异步编程的核心是使用多线程,通过让不同的线程执行不同的任务,实现不同代码的并行运行。
前台线程与后台线程
关于多线程,早在.NET2.0时代,基础类库中就提供了Thread实现。默认情况下,实例化一个Thread创建的是前台线程,只要有前台线程在运行,应用程序的进程就一直处于运行状态,以控制台应用程序为例,在Main方法中实例化一个Thread,这个Main方法就会等待Thread线程执行完毕才退出。而对于后台线程,应用程序将不考虑其是否执行完毕,只要应用程序的主线程和前台线程执行完毕就可以退出,退出后所有的后台线程将被自动终止。来看代码应该更清楚一些:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
namespace ConsoleApp
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("主线程开始");
//实例化Thread,默认创建前台线程
Thread t1 = new Thread(DoRun1);
t1.Start();
//可以通过修改Thread的IsBackground,将其变为后台线程
Thread t2 = new Thread(DoRun2) { IsBackground = true };
t2.Start();
Console.WriteLine("主线程结束");
}
static void DoRun1()
{
Thread.Sleep(500);
Console.WriteLine("这是前台线程调用");
}
static void DoRun2()
{
Thread.Sleep(1500);
Console.WriteLine("这是后台线程调用");
}
}
}运行上面的代码,可以看到DoRun2方法的打印信息“这是后台线程调用”将不会被显示出来,因为应用程序执行完主线程和前台线程后,就自动退出了,所有的后台线程将被自动终止。这里后台线程设置了等待1.5s,假如这个后台线程比前台线程或主线程提前执行完毕,对应的信息“这是后台线程调用”将可以被成功打印出来。
Task
.NET 4.0推出了新一代的多线程模型Task。async/await特性是与Task紧密相关的,所以在了解async/await前必须充分了解Task的使用。这里将以一个简单的Demo来看一下Task的使用,同时与Thread的创建方式做一下对比。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Web;
using System.Threading;
using System.Threading.Tasks;
namespace TestApp
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("主线程启动");
//.NET 4.5引入了Task.Run静态方法来启动一个线程
Task.Run(() => { Thread.Sleep(1000); Console.WriteLine("Task1启动"); });
//Task启动的是后台线程,假如要在主线程中等待后台线程执行完毕,可以调用Wait方法
Task task = Task.Run(() => { Thread.Sleep(500); Console.WriteLine("Task2启动"); });
task.Wait();
Console.WriteLine("主线程结束");
}
}
}首先,必须明确一点是Task启动的线程是后台线程,不过可以通过在Main方法中调用task.Wait()方法,使应用程序等待task执行完毕。Task与Thread的一个重要区分点是:Task底层是使用线程池的,而Thread每次实例化都会创建一个新的线程。这里可以通过这段代码做一次验证:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Web;
using System.Threading;
using System.Threading.Tasks;
namespace TestApp
{
class Program
{
static void DoRun1()
{
Console.WriteLine("Thread Id =" + Thread.CurrentThread.ManagedThreadId);
}
static void DoRun2()
{
Thread.Sleep(50);
Console.WriteLine("Task调用Thread Id =" + Thread.CurrentThread.ManagedThreadId);
}
static void Main(string[] args)
{
for (int i = 0; i < 50; i++)
{
new Thread(DoRun1).Start();
}
for (int i = 0; i < 50; i++)
{
Task.Run(() => { DoRun2(); });
}
//让应用程序不立即退出
Console.Read();
}
}
}运行代码,可以看到DoRun1()方法每次的Thread Id都是不同的,而DoRun2()方法的Thread Id是重复出现的。我们知道线程的创建和销毁是一个开销比较大的操作,Task.Run()每次执行将不会立即创建一个新线程,而是到CLR线程池查看是否有空闲的线程,有的话就取一个线程处理这个请求,处理完请求后再把线程放回线程池,这个线程也不会立即撤销,而是设置为空闲状态,可供线程池再次调度,从而减少开销。
Task<TResult>
Task<TResult>是Task的泛型版本,这两个之间的最大不同是Task<TResult>可以有一个返回值,看一下代码应该一目了然:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Web;
using System.Threading;
using System.Threading.Tasks;
namespace TestApp
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("主线程开始");
Task task = Task.Run(() => { Thread.Sleep(1000); return Thread.CurrentThread.ManagedThreadId.ToString(); });
Console.WriteLine(task.Result);
Console.WriteLine("主线程结束");
}
}
}Task<TResult>的实例对象有一个Result属性,当在Main方法中调用task.Result的时候,将等待task执行完毕并得到返回值,这里的效果跟调用task.Wait()是一样的,只是多了一个返回值。
async/await 特性
经过前面的铺垫,终于迎来了这篇文章的主角async/await,还是先通过代码来感受一下这两个特性的使用。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Web;
using System.Threading;
using System.Threading.Tasks;
namespace TestApp
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("-------主线程启动-------");
Task task = GetLengthAsync();
Console.WriteLine("Main方法做其他事情");
Console.WriteLine("Task返回的值" + task.Result);
Console.WriteLine("-------主线程结束-------");
}
static async Task GetLengthAsync()
{
Console.WriteLine("GetLengthAsync Start");
string str = await GetStringAsync();
Console.WriteLine("GetLengthAsync End");
return str.Length;
}
static Task GetStringAsync()
{
return Task.Run(() => { Thread.Sleep(2000); return "finished"; });
}
}
}首先来看一下async关键字。async用来修饰方法,表明这个方法是异步的,声明的方法的返回类型必须为:void或Task或Task<TResult>。返回类型为Task的异步方法中无需使用return返回值,而返回类型为Task<TResult>的异步方法中必须使用return返回一个TResult的值,如上述Demo中的异步方法返回一个int。而返回类型可为void,则是为了和事件处理程序兼容,比如下面的示例:
public Form1()
{
InitializeComponent();
btnDo.Click += Down;
}
public async void Down(object sender, EventArgs e)
{
btnDo.Enabled = false;
string str = await Run();
labText.Text = str;
btnDo.Enabled = true;
}
public Task Run()
{
return Task.Run(() => { Thread.Sleep(5000); return DateTime.Now.ToString(); });
}再来看一下await关键字。await必须用来修饰Task或Task<TResult>,而且只能出现在已经用async关键字修饰的异步方法中。
通常情况下,async/await必须成对出现才有意义,假如一个方法声明为async,但却没有使用await关键字,则这个方法在执行的时候就被当作同步方法,这时编译器也会抛出警告提示async修饰的方法中没有使用await,将被作为同步方法使用。了解了关键字async\await的特点后,我们来看一下上述Demo在控制台会输入什么吧。

输出的结果已经很明确地告诉我们整个执行流程了。GetLengthAsync异步方法刚开始是同步执行的,所以"GetLengthAsync Start"字符串会被打印出来,直到遇到第一个await关键字,真正的异步任务GetStringAsync开始执行,await相当于起到一个标记/唤醒点的作用,同时将控制权放回给Main方法,"Main方法做其他事情"字符串会被打印出来。之后由于Main方法需要访问到task.Result,所以就会等待异步方法GetLengthAsync的执行,而GetLengthAsync又等待GetStringAsync的执行,一旦GetStringAsync执行完毕,就会回到await GetStringAsync这个点上执行往下执行,这时"GetLengthAsync End"字符串就会被打印出来。
当然,我们也可以使用下面的方法完成上面控制台的输出。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Web;
using System.Threading;
using System.Threading.Tasks;
namespace TestApp
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("-------主线程启动-------");
Task task = GetLengthAsync();
Console.WriteLine("Main方法做其他事情");
Console.WriteLine("Task返回的值" + task.Result);
Console.WriteLine("-------主线程结束-------");
}
static Task GetLengthAsync()
{
Console.WriteLine("GetLengthAsync Start");
Task task = Task.Run(() => { string str = GetStringAsync().Result;
Console.WriteLine("GetLengthAsync End");
return str.Length; });
return task;
}
static Task GetStringAsync()
{
return Task.Run(() => { Thread.Sleep(2000); return "finished"; });
}
}
}对比两种方法,是不是async\await关键字的原理其实就是通过使用一个线程完成异步调用吗?答案是否定的。async关键字表明可以在方法内部使用await关键字,方法在执行到await前都是同步执行的,运行到await处就会挂起,并返回到Main方法中,直到await标记的Task执行完毕,才唤醒回到await点上,继续向下执行。更深入点的介绍可以查看文章末尾的参考文献。
async/await 实际应用
微软已经对一些基础类库的方法提供了异步实现,接下来将实现一个例子来介绍一下async/await的实际应用。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Web;
using System.Threading;
using System.Threading.Tasks;
using System.Net;
namespace TestApp
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("开始获取博客园首页字符数量");
Task task1 = CountCharsAsync("http://www.cnblogs.com");
Console.WriteLine("开始获取百度首页字符数量");
Task task2 = CountCharsAsync("http://www.baidu.com");
Console.WriteLine("Main方法中做其他事情");
Console.WriteLine("博客园:" + task1.Result);
Console.WriteLine("百度:" + task2.Result);
}
static async Task CountCharsAsync(string url)
{
WebClient wc = new WebClient();
string result = await wc.DownloadStringTaskAsync(new Uri(url));
return result.Length;
}
}
}参考文献:<IIIustrated C# 2012> 关于async/await的FAQ 《深入理解C#》
- 公众号绑定到微信开放平台要求:绑定的公众帐号必须已获得资质认证,并且开启了安全保护
- 微信开放平台帐号下的应用,要获得微信登录、智能接口、公众号第三方平台开发等高级能力,必须申请微信开放平台开发者资质认证

推荐:参考此文:如何升级 ASP.NET 项目 MySql.Data 和 Connector/NET 至 8.0.x
-------------------------------------------------------------------------------------------------------
这是 MySQL 官方提供的,用来帮助 .NET 开发者使用 LINQ 来方便操作 MySQL 数据库的解决方案。
我们所需要的软件全部被封装在 MySQL Installer 套件当中,非常方便。
下载后选择“Custom”自定义选择需要安装的产品和功能:
MySQL Server - 在本机安装 MySQL 数据库,如果我们直接连接远程数据库则不需要安装
MySQL for Visual Studio - 是一款 Visual Studio 插件,用于连接和管理 MySQL 数据库
Connector/NET - ADO.NET 托管提供程序
使用也非常方便:
在“服务资源管理器”中添加连接,更改数据源为“MySQL”。(如果没有该项,重启计算机试试;仍然没有,重新运行 MySQL Installer,选择“Modify ...”,勾选对应 VS 版本的“Visual Studio Integration”和“Entity Framework Designer Integration”)
项目中“添加新项”,在“数据”中选择“ADO.NET 实体数据模型”,即 Entity Framework,而非“LINQ to SQL 类”,根据需要选择表、视图和存储过程
Windows Server 服务器上安装 MySQL Server 过程中(或安装完成后再次运行 MySQL Installer)可配置端口(同时配置防火墙)。
建议勾选安装 MySQL Workbench 来管理 MySQL 数据库。
新建用户时,主机填“%”即该用户允许远程连接。
如果报以下错误:
不支持直接到存储查询(DbSet、DbQuery、DbSqlQuery)的数据绑定。应使用数据填充 DbSet (例如通过对 DbSet 调用 Load),然后绑定到本地数据。对于 WPF,绑定到 DbSet.Local。对于 WinForms,绑定到 DbSet.Local.ToBindingList()。
记得在绑定时加一个 .ToList() 即可。
如果发布后报以下错误:
找不到请求的 .Net Framework Data Provider。可能没有安装。
那么在服务器上安装 Connector/NET 即可。
如果在 VS 中连接此 EF 时如果遇到:
您的项目引用了最新版的实体框架;但是,找不到进行数据连接所需的与此版本兼容的实体框架数据库提供程序。请退出向导,安装兼容提供程序,重新生成您的项目,然后再执行此操作。
或
指定的架构无效。错误 0152: 未找到具有固定名称“MySql.Data.MySqlClient”的 ADO.NET 提供程序的实体框架提供程序。请确保在应用程序配置文件的“entityFramework”节中注册了该提供程序。有关详细信息,请参阅 http://go.microsoft.com/fwlink/?LinkId=260882。
那么,只需在 NuGet 中搜索并重新安装 MySql.Data.Entity ,重新生成项目。如果仍然提示,请检查 Connector/NET 是否有更新。
6.10.4 版本相关的问题参:MySQL Connector/Net 6.10.4 不支持 VS
本文是一个初学者对苹果开发证书的理解,有一定局限性,不适合所有苹果开发者参考,欢迎批评指正。
发布 iOS 应用主要有三块内容:Certificates, Identifiers & Profiles
Certificates(证书):是用来给应用程序签名的
Identifiers(标识符):一个应用对应一个 ID,相当于应用程序的身份证
Provisioning Profiles(描述文件):它将证书、标识符、设备结合起来,形成一个描述文件,让 Xcode 知道需要打一个怎么样的 .ipa 包
如何创建证书
创建 App ID 就不详说了,不要使用带通配符的名称。值得一提的是,如果要使用推送,必须勾选“Push Notifications”,其它功能按需勾选。
创建证书,需要用到 Mac 电脑上的“钥匙串访问”来生成一个“本地证书”(CSR 文件):
打开“钥匙串访问” - 证书助理 - 从证书颁发机构请求证书 - 保存到磁盘
然后就可以拿这个本地证书去 Apple Developer 里生成“开发证书”或“发布证书”(CER 文件)。打包证书和推送证书生成过程类似,区别是选择“App Store and Ad Hoc”还是“Apple Push Notification service SSL”。下载后添加到钥匙串就完成了。
添加测试设备就不提了。
然后就是描述文件,同样有开发和发布两种。开发主要是用于 Xcode 环境中;发布中还分两种:App Store 是用于正式上线的,Ad Hoc 是用于测试设备的。下一步选择 App ID,下一步选择证书,然后给 Profile 取个能够分辨的名字,生成的是一个 mobileprovision 文件。
提供证书文件给第三方打包平台
一般需要提供“iOS Distribution 证书”、“推送证书”、“Ad Hoc”和“App Store”类型的 Profiles、App ID 以及 iTunes Connect 中的 Apple ID(不是指登录的邮箱,是指在 iTunes Connect 中创建的 App 在商店中的 ID)。
证书其实跟 App ID 不是一一对应的关系,多个 App 是可以使用同一个证书的。可以单独创建,到期互不影响。Download 后是 .cer 格式,用“钥匙串”工具可以导出 .p12 证书并设置密码。
如果由于命名无序或创建错误导致无法分辨上架中的 App 用的是哪个证书,哪个描述文件,那么,首先要知道这个 App ID 是多少(就是 iTunes Connect 中所谓的“套装 ID”),然后在 Provisioning Profiles 中挨个查看对应的 App ID,点击“Edit”还能看到使用的证书。
有些平台需要 .pem 文件,是由 .p12 文件通过一个命令转化而来的,具体可以百度。
证书过期怎么办
创建一个呗,然后描述文件 Edit,选择新的证书。
推送证书过期怎么办
在 App ID 里 Edit 就能查看 Push Notifications 项的 SSL Certificate 是否过期。如果过期需要重新创建证书,可以直接在 App ID 的 Edit 里快捷创建(需要“钥匙串”配合)。
不用重新提交 App Store 审核
换一台电脑,证书要怎么导过去
这个问题适用于自己使用 Xcode 开发应用的情况,暂时问一下百度吧。
注:本文部分总结来自百度,未经证实。
Apple Push Services 和 APNs Production iOS 这两种类型有什么区别?
“/”应用程序中的服务器错误。
未能加载文件或程序集“XXXXXX”或它的某一个依赖项。试图加载格式不正确的程序。
说明: 执行当前 Web 请求期间,出现未经处理的异常。请检查堆栈跟踪信息,以了解有关该错误以及代码中导致错误的出处的详细信息。
异常详细信息: System.BadImageFormatException: 未能加载文件或程序集“XXXXXX”或它的某一个依赖项。试图加载格式不正确的程序。
源错误:
执行当前 Web 请求期间生成了未经处理的异常。可以使用下面的异常堆栈跟踪信息确定有关异常原因和发生位置的信息。
程序集加载跟踪: 下列信息有助于确定程序集“XXXXXX”未能加载的原因。
警告: 程序集绑定日志记录被关闭。 要启用程序集绑定失败日志记录,请将注册表值 [HKLM\Software\Microsoft\Fusion!EnableLog] (DWORD)设置为 1。 注意: 会有一些与程序集绑定失败日志记录关联的性能损失。 要关闭此功能,请移除注册表值 [HKLM\Software\Microsoft\Fusion!EnableLog]。
当使用 Visual Studio 发布网站时,可能会遇到上述黄屏报错,原因之一是引用的 dll 路径不正确,可以用 Release 模式生成一次看看;原因之二是应用程序的位数与服务器的不匹配。
一般来说用“Any CPU”的方式没有问题,但遇到上述报错的百度网友都很轻松地通过修改 IIS 应用程序池的“启用 32 位应用程序”来解决这个问题,原因是他们的服务器是 64 位操作系统。当我这次在 32 位操作系统的服务器上遇到这个问题的时候真的是手足无措了,然后一阵乱配置,偶尔还能成功跑起来,于是仔细对比了发布到服务器上的文件,发现只有 bin 目录下的 dll 文件有区别,而导致这些区别的原因是我在发布时把“Release - Any CPU”换成了“Debug - Any CPU”,所以一时找不到更好的解决办法的朋友不妨也试试这个方法,只是会有一点点担心性能问题。有更好的解决方案的朋友也不要忘了联系我。
微信是一个生活方式,朋友圈是用户分享和关注朋友们生活点滴的空间,微信公众平台是一个企业、机构与个人用户之间交流和服务的平台。一直以来,微信致力于为用户提供绿色、健康的网络生态环境。通过《微信公众平台服务协议》、《微信公众平台运营规范》和《微信开放平台开发者服务协议》等相关协议及专项规则,微信公众平台和微信开放平台的内容得到了良好的管理。为了进一步优化微信用户的使用体验,更好地保障微信用户合法权益,现将非由微信公众平台产生(即域名地址不归属于微信公众平台)且在微信内传播的外部链接内容相关管理规范进行公示。
对于违反本规范的内容,一经发现将立即进行处理,包括但不限于停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行访问、屏蔽相关链接等。由微信公众平台或开放平台帐号施行或者发起的,一经查实,前述帐号、主体也将按照微信相关规则进行处罚,包括但不限于限制或禁止使用部分或全部功能、帐号封禁直至注销等,并公告处理结果;微信也有权依照本规范及相关协议、专项规则的规定,拒绝再向前述主体提供服务。
具体规则及相关处罚如下:
-
诱导分享类内容
-
1.1 要求用户分享,分享后方可进行下一步操作,分享后方可知道答案等;
-
1.2 含有明示或暗示用户分享的文案、图片、按钮、弹层、弹窗等的,如:分享给好友、邀请好友一起完成任务等;
-
1.3 通过利益诱惑,诱导用户分享、传播外链内容或者微信公众帐号文章的,包括但不限于:现金奖励、实物奖品、虚拟奖品(红包、优惠券、代金券、积分、话费、流量、信息等)、集赞、拼团、分享可增加抽奖机会、中奖概率,以积分或金钱利益诱导用户分享、点击、点赞微信公众帐号文章等;
-
1.4 用夸张言语来胁迫、引诱用户分享的。包括但不限于:“不转不是中国人”、“请好心人转发一下”、“转发后一生平安”、“转疯了”、“必转”、“转到你的朋友圈朋友都会感激你”等;
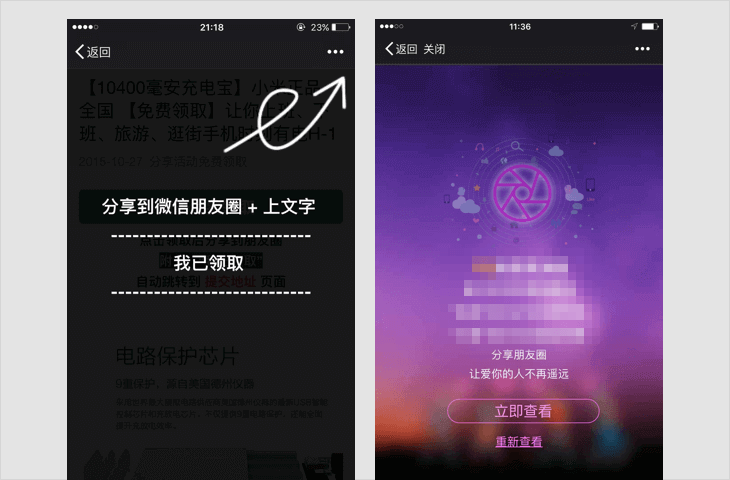
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问,短期封禁相关开放平台帐号或应用的分享接口;对于情节恶劣的情况,永久封禁帐号、域名、IP地址或分享接口。
-
-
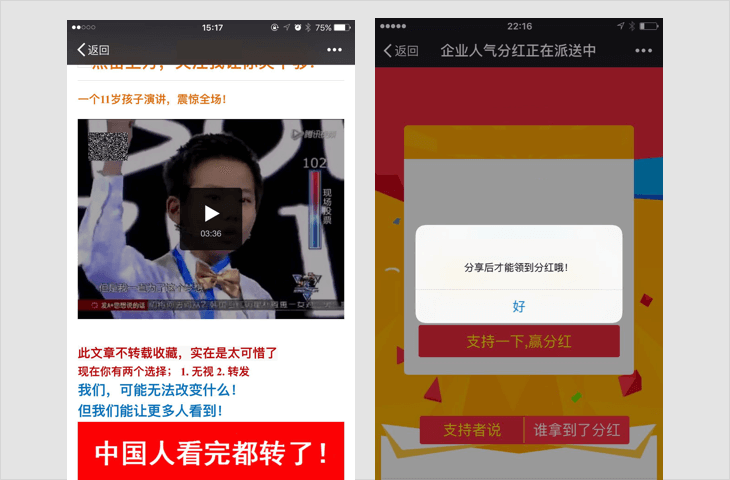
诱导关注类内容
-
强制或诱导用户关注公众帐号的,包括但不限于关注后查看答案、领取红包、关注后方可参与活动等;
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
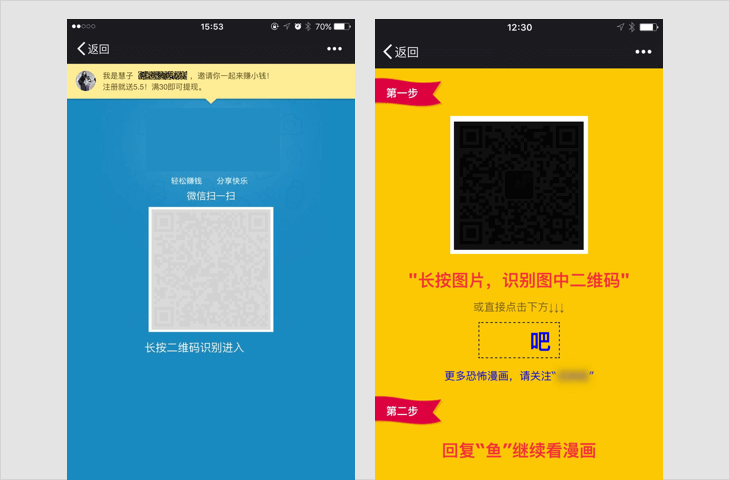
H5游戏、测试类内容
-
以游戏、测试等方式,吸引用户参与互动的,具体形式包括但不限于比手速、好友问答、性格测试,测试签、网页小游戏等;
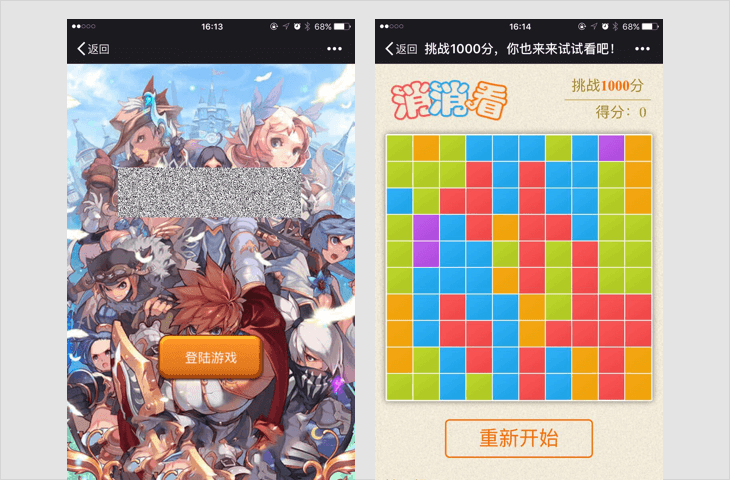
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
欺诈类内容
-
4.1 虚假红包、活动
通过虚假的红包、活动等形式,以赚取现金、实物奖品、虚拟奖品等方式欺骗用户参与的,具体形式包括但不限于虚假现金红包、虚假话费卡、虚假流量红包、虚假优惠券、虚假优惠活动等;
-
4.2 宣传或销售侵害他人合法权益的商品
通过虚假宣传、恶意营销等方式,向用户宣传或诱骗用户购买侵害他人合法权益的物品的,例如以骗取邮费为目的的赠送物品活动、虚假付费服务等;
-
4.3 仿冒微信公众帐号排版、域名
仿冒微信公众帐号文章排版、域名,可能造成微信用户混淆的;
若内容中包含以上情况,一经发现,立即永久封禁帐号、域名、IP地址。
-
-
谣言类内容
-
发送不实信息,制造谣言,可能对他人、企业或其他机构造成损害的,例如自来水有毒、香蕉致癌、小龙虾不能吃等;
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问、短期封禁相关开放平台帐号或应用的分享接口;对于情节恶劣的情况,永久封禁帐号、域名、IP地址;
-
-
骚扰信息、广告信息及垃圾信息
-
传播骚扰、欺诈、垃圾广告等信息的,包括但不限于虚假中奖类信息,不符合国家相关法律法规的保健品、药品、食品类信息,假冒伪劣商品信息,虚假服务信息,虚假网络货币等;
-
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
题文不符、内容低俗的信息
-
7.1 题文不符的信息
故意拟制耸动标题,或以明显倾向性、误导性、煽动性的标题吸引他人点击的,即俗称“标题党”;
-
7.2 内容低俗的信息
涉及性器官、性行为、性暗示的,传播低级趣味、庸俗、有伤风化内容的,或者宣扬暴力、恶意谩骂、侮辱他人内容的,例如:传播走光、偷拍、露点、一夜情、换妻、性虐待、情色动漫、非法性药品广告和性病治疗广告、推介淫秽色情网站等;
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
非法获取用户数据、信息
-
未经用户明确同意,并向用户如实披露数据用途、使用范围等相关信息的情形下复制、存储、使用或传输用户数据的,包括但不限于要求用户共享个人信息(手机号、出生日期等)才可使用其功能,或收集用户密码或者用户个人信息(包括但不限于,手机号,身份证号,生日,住址等);
-
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问,短期封禁相关帐号;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
-
其它违反国家法律法规的内容,包括但不限于:
-
(1) 违反宪法确定的基本原则的;
-
(2) 危害国家安全,泄露国家秘密,颠覆国家政权,破坏国家统一的;
-
(3) 损害国家荣誉和利益的;
-
(4) 煽动民族仇恨、民族歧视,破坏民族团结的;
-
(5) 破坏国家宗教政策,宣扬邪教和封建迷信的;
-
(6) 散布谣言,扰乱社会秩序,破坏社会稳定的;
-
(7) 散布淫秽、色情、赌博、暴力、恐怖或者教唆犯罪的;
-
(8) 侮辱或者诽谤他人,侵害他人合法权益的;
-
(9) 煽动非法集会、结社、游行、示威、聚众扰乱社会秩序;
-
(10) 以非法民间组织名义活动的;
-
(11) 含有法律、行政法规禁止的其他内容的。
-
若内容中包含以上情况,一经发现,立即停止链接内容在朋友圈继续传播、停止对相关域名或IP地址进行的访问,短期封禁相关帐号;对于情节恶劣的情况,永久封禁帐号、域名、IP地址。
-
申诉及常见问题可查看:http://kf.qq.com/faq/131117ne2MV7141117JzI32q.html
微信团队请用户主动遵守上述条款,也欢迎用户对违反微信链接类内容管理规范的内容进行投诉,一经核实,微信团队将立即按照规范进行处理。让我们共同创建并维护和谐的微信生态!
微信团队
编者按:本文作者 Nick Babich 在文中介绍了几种 “提高” 加载速度的方法。
当我们设计产品的时候,我们没有办法模拟不同的加载速度。因此如果用户等待太长的时间才能看到内容,并不是我们特意的安排。
网速不稳定,尤其是当我们加载图片或音乐时,时间会较长。在这种情况下,我们不得不考虑在这种间隙向用户展示什么内容才能让他们感觉不枯燥。
加载动图(Spinner)效果不佳
加载 Spinner 并不是暗示加载或思考的正确方式。默认加载图标(例如 iOS 的加载动画效果是从中心点辐射的灰色线条)通常具有消极的含义。它们应用于多种操作系统功能之中,包括设备启动、连接到网络或者加载数据。

人们讨厌只看到加载 Spinner,但是却看不多进度或时间。让用户盯着一个下载进度条或者旋转圈会让跳出率提高。
不确定的等待时间比已知的、有限的等待时间让人觉得更长。你应该给你的用户一个清晰地等待时间。

进度条可以告诉用户这个过程需要花费多长时间,但是一般不太正确。你可以通过一些方法隐藏过程中的延迟,例如你可以在开始的时候让速度显示地快一点,在结尾的时候,显示速度慢一点。进度条不应该中断,否则用户就会认为这个 App 卡住了。
后台操作
在后台操作中包含行为有两个优点——用户可见;在用户真正发出请求时就会加载完毕。当程序在后台运营时,给用户呈现一些其他的内容。一个很好的案例是在 Instagram 中加载图片。用户一旦选择想要分享的图片,就开始加载。

在后台加载图片的过程中,Instagram 邀请用户添加标题和标签,当用户准备按 “分享” 键时,加载过程就完成了,这时候就可以立刻分享图片了。
仿真内容和 Placeholder(占位符)
如果你无法缩短加载时间,那么你应该试图让用户在等待中更高兴一点。可以利用这个时间显示一些临时的信息。为了提高用户的参与度,可以使用仿真内容作为文本和图片。
几点小建议:
1、加载屏幕不应该太亮。不需要太吸引眼球。Facebook 的灰色 Placeholder 就是一个很好的例子。当加载内容时使用模板元素,让用户熟悉将要加载的内容的整体结构。

2、如果要加载图片,你可以在 placeholder 中使用加载图片的主色调。Medium 的图片加载效果比较好。首先加载一个小型的模糊图片,然后转化成一个清晰的大图片。

使用 placeholder 和仿真内容并没有加快加载过程,但是在用户眼中加载速度好像变快了。
分散用户的注意力
为了不让用户在等待时感到枯燥,可以适当分散他们的注意力。你可以使用一些有趣的、始料未及的东西吸引用户的注意力,为 App 加载赢得充足的时间。

动画片可以分散访客的注意力,让他们忽略加载时间。
结论
用户讨厌等待,如果你让用户觉得他们没有等待,那么他们就会喜欢你的 App。一定要让用户觉得 App 的加载时间比他预计的短。
为防止木马访问网站根目录以外的文件
搭建服务器时一定在所有分区拒绝 IIS_IUSRS 组的一切权限(如果网站用户隶属的是其它组就配置那个组)
新加硬盘时也务必同上操作
创建用户,归组
创建目录
wwwroot
logs
设置目录权限
创建FTP用户
下载代码
IIS创建网站
绑定域名
日志路径,应用
修改应用程序池,版本,管道,标识用户
要上传的目录权限,去脚本
本机改 hosts 测试
改域名解析
改数据库连接
关老站
打开测试
在 ASP.NET Core 或 ASP.NET 5 中部署百度编辑器请跳转此文。
本文记录百度编辑器 ASP.NET 版的部署过程,对其它语言版本也有一定的参考价值。
【2020.02.21 重新整理】
下载
从 GitHub 下载最新发布版本:https://github.com/fex-team/ueditor/releases
按编码分有 gbk 和 utf8 两种版本,按服务端编程语言分有 asp、jsp、net、php 四种版本,按需下载。
目录介绍
以 v1.4.3.3 utf8-net 为例,

客户端部署
本例将上述所有目录和文件拷贝到网站目录 /libs/ueditor/ 下。
当然也可以引用 CDN 静态资源,但会遇到诸多跨域问题,不建议。
在内容编辑页面引入:
<script src="/libs/ueditor/ueditor.config.js"></script>
<script src="/libs/ueditor/ueditor.all.min.js"></script>在内容显示页面引入:
<script src="/libs/ueditor/ueditor.parse.min.js"></script>如需修改编辑器资源文件根路径,参 ueditor.config.js 文件内顶部文件。(一般不需要单独设置)
如果使用 CDN,那么在初始化 UE 实例的时候应配置 serverUrl 值(即 controller.ashx 所在路径)。
客户端配置
初始化 UE 实例:
var ue = UE.getEditor('tb_content', {
// serverUrl: '/libs/ueditor/net/controller.ashx', // 指定服务端接收文件路径
initialFrameWidth: '100%'
});其它参数见官方文档,或 ueditor.config.js 文件。
服务端部署
net 目录是 ASP.NET 版的服务端程序,用来实现接收上传的文件等功能。
本例中在网站中的位置是 /libs/ueditor/net/。如果改动了位置,那么在初始化 UE 的时候也应该配置 serverUrl 值。
这是一个完整的 VS 项目,可以单独部署为一个网站。其中:
net/config.json 服务端配置文件
net/controller.ashx 文件上传入口
net/App_Code/CrawlerHandler.cs 远程抓图动作
net/App_Code/ListFileManager.cs 文件管理动作
net/App_Code/UploadHandler.cs 上传动作
该目录不需要转换为应用程序。
服务端配置
根据 config.json 中 *PathFormat 的默认配置,一般地,上传的图片会保存在 controller.ashx 文件所在目录(即本例中的 /libs/ueditor/)的 upload 目录中:
/libs/ueditor/upload/image/
原因是 UploadHandler.cs 中 Server.MapPath 的参数是由 *PathFormat 决定的。
以修改 config.json 中的 imagePathFormat 为例:
原值:"imagePathFormat": "upload/image/{yyyy}{mm}{dd}/{time}{rand:6}"
改为:"imagePathFormat": "/upload/ueditor/{yyyy}{mm}{dd}/{time}{rand:6}"
以“/”开始的路径在 Server.MapPath 时会定位到网站根目录。
此处不能以“~/”开始,因为最终在客户端显示的图片路径是 imageUrlPrefix + imagePathFormat,若其中包含符号“~”就无法正确显示。
在该配置文件中查找所有 PathFormat,按相同的规则修改。
说到客户端的图片路径,我们只要将
原值:"imageUrlPrefix": "/ueditor/net/"
改为:"imageUrlPrefix": ""
即可返回客户端正确的 URL。
当然也要同步修改 scrawlUrlPrefix、snapscreenUrlPrefix、catcherUrlPrefix、videoUrlPrefix、fileUrlPrefix。
特殊情况,在复制包含图片的网页内容的操作中,若图片地址带“?”等符号,会出现无法保存到磁盘的情况,需要修改以下代码:
打开 CrawlerHandler.cs 文件,找到
ServerUrl = PathFormatter.Format(Path.GetFileName(this.SourceUrl), Config.GetString("catcherPathFormat"));替换成:
ServerUrl = PathFormatter.Format(Path.GetFileName(SourceUrl.Contains("?") ? SourceUrl.Substring(0, SourceUrl.IndexOf("?")) : SourceUrl), Config.GetString("catcherPathFormat"));如果你将图片保存到第三方图库,那么 imageUrlPrefix 值设为相应的域名即可,如:
改为:"imageUrlPrefix": "//cdn.***.com"
然后在 UploadHandler.cs 文件(用于文件上传)中找到
File.WriteAllBytes(localPath, uploadFileBytes);在其下方插入上传到第三方图库的代码,以阿里云 OSS 为例:
// 上传到 OSS
client.PutObject(bucketName, savePath.Substring(1), localPath);在 CrawlerHandler.cs 文件(无程抓图上传)中找到
File.WriteAllBytes(savePath, bytes);在其下方插入上传到第三方图库的代码,以阿里云 OSS 为例:
// 上传到 OSS
client.PutObject(bucketName, ServerUrl.Substring(1), savePath);最后有还有两个以 UrlPrefix 结尾的参数名 imageManagerUrlPrefix 和 fileManagerUrlPrefix 分别是用来列出上传目录中的图片和文件的,
对应的操作是在编辑器上的“多图上传”功能的“在线管理”,和“附件”功能的“在线附件”。
最终列出的图片路径是由 imageManagerUrlPrefix + imageManagerListPath + 图片 URL 组成的,那么:
"imageManagerListPath": "/upload/ueditor/image",
"imageManagerUrlPrefix": "",
以及:
"fileManagerListPath": "/upload/ueditor/file",
"fileManagerUrlPrefix": "",
即可。
如果是上传到第三方图库的,且图库上的文件与本地副本是一致的,那么将 imageManagerUrlPrefix 和 fileManagerUrlPrefix 设置为图库域名,
服务端仍然以 imageManagerListPath 指定的路径来查找本地文件(非图库),但客户端显示图库的文件 URL。
因此,如果文件仅存放在图库上,本地没有副本的情况就无法使用该功能了。
综上,所有的 *UrlPrefix 应该设为一致。
另外记得配置不希望被远程抓图的域名,参数 catcherLocalDomain。
服务端授权
现在来判断一下只有登录用户才允许上传。
首先打开服务端的统一入口文件 controller.ashx,
继承类“IHttpHandler”改为“IHttpHandler, System.Web.SessionState.IRequiresSessionState”,即同时继承两个类,以便可使用 Session,
找到“switch”,其上插入:
if (用户未登录) { throw new System.Exception("请登录后再试"); }即用户已登录或 action 为获取 config 才进入 switch。然后,
else
{
action = new NotAllowedHandler(context);
}这里的 NotAllowedHandler 是参照 NotSupportedHandler 创建的,提示语 state 可以是“登录后才能进行此操作。”
上传目录权限设置
上传目录(即本例中的 /upload/ueditor/ 目录)应设置允许写入和禁止执行。
基本用法
设置内容:
ue.setContent("Hello world.");获取内容:
var a = ue.getContent();更多用法见官方文档:http://fex.baidu.com/ueditor/#api-common
其它事宜
配置上传附件的文件格式
找到文件:config.json,更改“上传文件配置”的 fileAllowFiles 项,
同时在 Web 服务器上允许这些格式的文件可访问权限。以 IIS 为例,在“MIME 类型”模块中添加扩展名。
遇到从客户端(......)中检测到有潜在危险的 Request.Form 值。请参考此文
另外,对于不支持上传 .webp 类型的图片的问题,可以作以下修改:
config.json 中搜索“".bmp"”,替换为“".bmp", ".webp"”
IIS 中选中对应网站或直接选中服务器名,打开“MIME 类型”,添加,文件扩展名为“.webp”,MIME 类型为“image/webp”
最后,为了在内容展示页面看到跟编辑器中相同的效果,请参照官方文档引用 uParse
若有插入代码,再引用:
<link href="/lib/ueditor/utf8-net/third-party/SyntaxHighlighter/shCoreDefault.css" rel="stylesheet" />
<script src="/lib/ueditor/utf8-net/third-party/SyntaxHighlighter/shCore.js"></script>
其它插件雷同。
若对编辑器的尺寸有要求,在初始化时设置即可:
var ue = UE.getEditor('tb_content', {
initialFrameWidth: '100%',
initialFrameHeight: 320
});
家里用的 6M 小水管,经常遇到打开网页龟速,于是进入 TP-LINK 路由器控制面板,打开流量统计,发现竟然是 iPhone 在偷跑流量。下载速度几乎为 0.00KB/s,但上传速度稳定在 50~80KB/s,属于满负荷上传。
于是问度娘有没有类似网络监控的应用,无果。在 App Store 找各种流量仪,发现都是只管数据流量的,没有监控哪些应用在占用 WiFi。
看看手机状态栏也没有正在使用网络的 Loading 图标,莫非手机中毒了?
双击 Home 键,一个一个地删除后台程序,每次看流量都还在上传。
又是各种百度,终于有了眉目,是不是 iCloud 在 WiFi 下自动备份?
进入 设置 - iCloud - 备份 - iCloud 云备份,确实是“开”的,但明明写清楚了只有在 iPhone 接入电源、锁定且接入无线局域网时,才自动备份数据。
试一下吧,关闭它。继续观察……还在上传。
这倒提醒到我了,是不是在自动备份照片呢?
干脆我就再等等,过了几分钟,路由器上看到上传速度降下来了,于是我拿着手机猛地拍了好多照片,不一会儿,上传速度又噌噌噌往上飙了,看来原因是找到了。
那么我就直接把百度云删了吧,因为我是用它来自动备份照片的。
可是……仍然没什么卵用。
那就只剩你了:iCloud
进入 设置 - iCloud - 照片 - 我的照片流,关闭!
整个世界安静了……
--------------------------------------------------------------------
几天以后,悲剧地发现,还是在上传数据
--------------------------------------------------------------------
几周后,家里换用小米路由器,再没有发现 iPhone 偷偷上传。
(也有可能是我关闭了 设置 - iCloud - 备份 - iCloud 云备份 的缘故。)
--------------------------------------------------------------------
几个月后,我无意间进入 设置 - iCloud - 储存空间 - 管理储存空间 - 此 iPhone,看到列出了备份到 iCloud 上的数据。照片图库没有问题,有新照片一定是增量备份的,但是 QQ 和微信的数据就不一定了,以电脑端的聊天记录为例,QQ 是放在 Msg2.0.db 或 Msg3.0.db 单个文件的,如果手机端也是,而且每次都要把几百 MB 甚至几 GB 的文件备份到 iCloud 上,结果可想而知。